# 缓存组件
# 什么时候使用?
- 缓解数据库压力,提升响应速率。
- 节点之间数据同步,内存共享。
平台封装了统一的缓存API组件,单机和集群下由平台统一控制使用对应的缓存实现,真正做到一处开发多处使用的能力。 单机默认采用内存缓存,集群采用集中式Redis缓存。
# 如何使用?
// 第一步,创建缓存群组:PrivilegeCacheImpl.class 为缓存的组名称
private CacheAccessable factory = CacheFactory.getInstance(PrivilegeCacheImpl.class);
// 第二步,创建缓存:menuMap 为缓存名称,在同一个组内缓存名称不能相同
private AdvancedCacheMap<Long, PrivMenuBO, Long> menuMap = factory.createAdvancedMap("menuMap", new PrivMenuL2CacheMapLoader(), true, 500);
// 第三步,使用缓存
获取数据: menuMap.get(1231)
写入数据:menuMap.put(123,Obj)
删除数据:menuMap.remove(123)
# 使用哪种类型?
平台提供了多种缓存模型,开发可以根据实际场景采用对应的缓存方案。
# CacheMap
键值对数据缓存,提供类似于java.util.Map的功能,支持常用的get,put,remove等方法。
/**举例:创建CacheMap**/
CacheMap<String, RestUser> restuserCache = factory.createMap("restuser",new RestUserMapLoader());
/**Rest用户加载*/
public class RestUserMapLoader implements MapDataLoader<String, RestUser>{
@Override
public RestUser load(String key) {
Map<String, RestUser> loadLocal = loadBatch(Arrays.asList(key));
if(loadLocal != null)
return loadLocal.get(key);
return null;
}
@Override
public Map<String, RestUser> loadBatch(Collection<String> keys) {
Map<String, RestUser> map = null;
if(keys.size() > 0) {
RestUserDao restUserDao = (RestUserDao) AppContext.getBean("restUserDao");
List<RestUser> restUsers = restUserDao.findListUserByNames(new ArrayList<String>(keys));
map = convertToMap(restUsers);
}
return map;
}
}
# AdvancedCacheMap
CacheMap的高级实现,除了CacheMap的功能之外,还支持批量数据获取、懒加载、本地模式、索引等。
/**举例:枚举缓存**/
AdvancedCacheMap<Long, CtpEnumItem, EnumItemIndex> advanceCtpEnumItemCache =
factory.createAdvancedMap("ctpEnumItemCache", new EnumItemCacheMapLoader());
/**枚举缓存加载及丢失补偿**/
public class EnumItemCacheMapLoader implements L2CacheMapLoader_Long<Long,CtpEnumItem, HashMap> {
@Override
public Map loadIndexData() {
//如果需要使用index功能需要实现该接口,同时设置下方的hasIndex返回true
}
@Override
public CtpEnumItem loadDataFromDB(Long id) {
//单个数据加载
}
@Override
public boolean hasIndex() {
return false;
}
@Override
public int getL2CacheSize() {
//设置本地LRU缓存的大小,如果在接口中不覆盖,默认大小为1000
return 200000;
}
/**
* 按照key集合从数据库中批量加载数据
* @param ids
* @return
*/
@Override
public Map loadDatasFromDB(Long... ids){
//批量获取
}
/**
* 从数据库中批量加载数据
*
* @return
*/
@Override
public Map loadAllDatasFromDB() {
}
}
# IndexCacheMap
主要的方法同CacheMap,但是加入了索引存储机制,主要用于关系缓存。
/**举例:登录token和用户Id的关系缓存**/
IndexCacheMap<String, Long> cacheThirdUser = factory.createIndexMap("cacheThirdUser", new MemberTransformationLoader());
/**按需加载*/
public class MemberTransformationLoader implements L2IndexCacheMapLoader_String<String,Long> {
private ThirdpartyUserMapperDao thirdpartyUserMapperDao;
@Override
public Map<String, Long> loadIndexData() {
Map<String, Long> userMap = new HashMap<String, Long>();
List<ThirdpartyUserMapper> mapperUserList = getMapperDao().getAllUserMapper();
for (ThirdpartyUserMapper thirdpartyUserMapper : mapperUserList) {
//TODO
}
return userMap;
}
}
# CacheObject
单一对象缓存,提供get,set两个方法。
/**举例:集群配置缓存**/
CacheObject<Properties> cache = factory.createObject("masterProperties",null);
# CacheSet
Set缓存,管理集合类的缓存,提供类似java.util.Set的功能。
/**举例:用户访问Token缓存**/
CacheSet<String> UserIdOfCanAccessMobile = cacheFactory.createSet("UserIdOfCanAccessMobile");
# Redis缓存组件原理
以AdvanceCacheMap实现为例,讲解缓存组件写入和读取的主要流程及原理。
# 缓存读取【get方法】
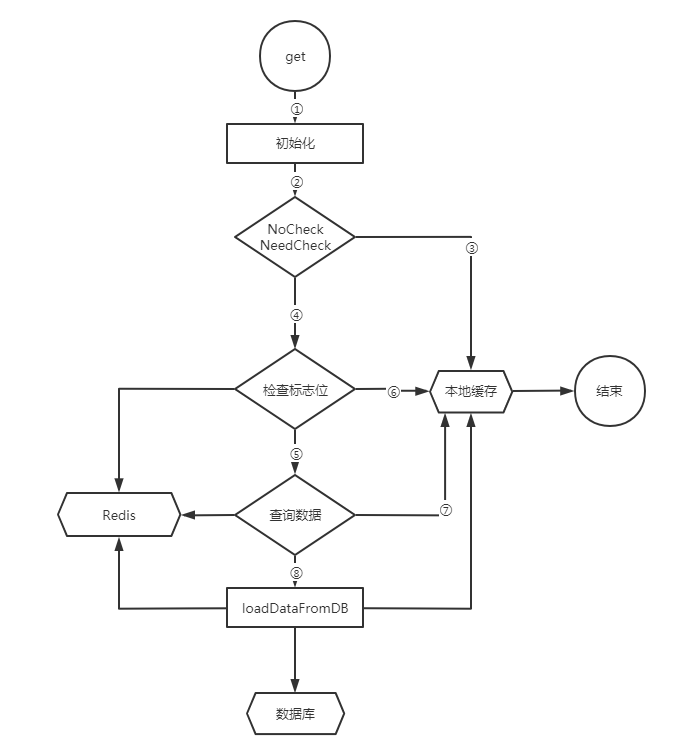
读取缓存数据步骤
① 初始化
② 检查NoCheck机制,在Nocheck中包含了无效Key检查,处理逻辑:AutoRefresh重新加载Index,从AutoRefresh HashMap中获取需要更新的Key;非AutoRefresh检查本地Key的标记位。使用了Index不要设置短时间Nocheck
③ 在NoCheck时间内,直接查询本地缓存返回数据
④ 查询Redis标记位
⑤ 标记为和缓存不一致,获取Redis中缓存数据
⑥ 标记位和本地一致,数据没发生变化,直接取本地缓存中数据返回
⑦ Redis中读取到数据,更新本地缓存,返回数据
⑧ Redis中读取不到数据,从数据库加载数据
# 缓存写入【put方法】
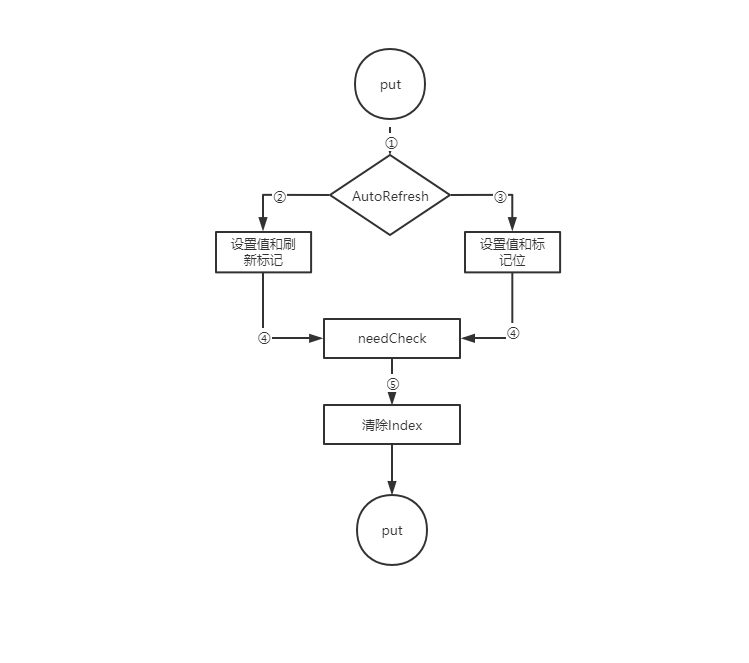
写入缓存数据
① 所有的修改操作基本都走这个逻辑,包括put、remove、update等。
② 如果标记为AutoRefresh,放入数据和Flag的同时,放入Flag刷新标记位,刷新数据2分钟有效,各节点需要在2分钟之内,去拉取Flag并同步数据到本地。
③ 其他缓存,直接放入数据和Flag。
④ 放入本地缓存,并设置needCheck为true,下次获取时,强制做数据对比。
⑤ 清除本地Index,如果实现了Index。
# 常见场景
# 全量缓存
为了提供缓存命中率,很多数据量不大,但访问频率很高的数据可以采用全量缓存,全量缓存的数据在系统启动初始化时,从数据库中全量加载并缓存在Redis中,后续的操作通过后台的自动刷新机制同步到集群中的其他节点。
// autoRefresh设置为true
createAdvancedMap(String cacheName, L2CacheMapLoader_Inner dataLoader, boolean autoRefresh, int noCheckTime);
# 按需加载
启动时,系统不会加载全量的缓存数据,当需要读取数据时才通过接口从数据库中读取数据放入缓存中,使用按需加载时修改自己节点的数据不会通过自动刷新机制同步到集群中的其他节点,但是可以通过调用get方法主动对比flag标记位完成数据同步。
// autoRefresh设置为false
createAdvancedMap(String cacheName, L2CacheMapLoader_Inner dataLoader, boolean autoRefresh, int noCheckTime);
# 数据更新
- 更新数据时,推荐更新完数据库之后,删除Redis缓存中的数据,在下一次加载数据时,如果缓存中没有,会调用数据加载接口从新从数据库加载。尽量不要更新完数据库之后,直接调用put方法往Redis中写入数据。
- 在涉及高频访问时,尽量以数据库数据为基准来做业务判断,比如验证人员登录密码。
# 数据同步
目前缓存组件除了用于加速数据访问速度外,还有一个重要的功能是实现各节点之间数据同步,目前缓存中主要的数据同步机制包含以下两种:
- flag比对,数据在写入时会变更flag标记位,当本地数据的标记位和Redis中不一致时,组件会同步Redis中数据到本地,数据查询主要查询本地缓存中的数据。(主要机制,主动)
- 自动刷新机制,组件会在后台以一定的频率批量刷新Redis中的数据到本地缓存,完成各节点之前的数据同步。(次要机制,被动)
# 高频访问
由于在业务开发中存在循环调用的情况,每次调用即时从Redis中读取数据依旧性能表现不佳,这时可用通过缓存组件中的nocheck机制,在一定时间范围内直接动本地读取数据,减少对Redis访问的频率。 调用方式:
// autoRefresh设置为true
// noCheckTime设置时间范围
createAdvancedMap(String cacheName, L2CacheMapLoader_Inner dataLoader, boolean autoRefresh, int noCheckTime);
这种使用方式依靠自动刷新机制完成各节点之间的数据同步,由于自动刷新机制有一定延迟,且是被动机制,所以在一些低延迟,高数据一致性场景可能会存在一些问题,应该尽量避免使用。如果必须使用可以调用AdvanceCacheMap.get(key,false)穿透到Redis中读取数据。
# 不推荐的使用方式
# 不满足事务提交
在关系数据库中能保证事务的一致性,但是在Redis并不擅长处理事务的问题,如果在长事务中使用redis缓存相关的操作,需要考虑缓存场景的适应性,以及是否可以通过额外的补偿来解决事务的问题。
推荐方式:
- 注册spring事务TransactionSynchronizationManager.registerSynchronization在数据库更新完成后再执行redis操作。
- 在同时操作数据库和缓存时,应该先操作数据库,在操作缓存,同时也可以考虑幂等操作,在数据库事务回滚后是否对Redis中已写入的数据有影响。
# 无补偿模型
现在的缓存组件属于读穿透模型,当数据丢失时,缓存组件可以根据提供的数据加载接口自动补偿丢失的数据,但是一些业务中并没有配置数据加载接口,将会导致缓存数据丢失后不能被找回的情况。在使用缓存组件时尽量都配置数据加载接口,对于一些数据不能通过数据补偿的,需要考虑其他补偿机制,如:幂等,重建,忽略等方式,来满足业务功能。
# index缓存使用不当
IndexMap实现的本身是为实现动态数据加载,但是这个实现要求缓存组件需要知道所有的index(key/主键),并且所有的写操作,更新操作都会触发更新index,所以如果在业务场景中大量使用更新操作,将会导致大量的index重新加载请求,从而带来性能问题。
两种代码编写方式为使用index:
- AdvanceCacheMap的数据加载接口中hasIndex()方法返回True。
- 调用createIndexMap,创建了IndexCacheMap。
# LRU设置不当
当前提供的几种缓存组件都带有本地缓存(JVM)缓存,本地缓存的大小可以通过LRU算法来设置,默认1000,当本地缓存数量超过设定的值后就会被淘汰出本地缓存,如果缓存中的数据量比较大,且访问频率很高,将会导致大量的数据被频繁的淘汰,导致大量的访问请求直接让问Redis,影响性能。
@Override
public int getL2CacheSize() {
return 200;
}
# 不推荐的方法
在缓存组件中提供了keySet,values等方法,这写方法对于本地的JVM缓存是没有问题的,但是对于分布式缓存,对于大数据场景,在缓存中只是加载的一部分热点数据,调用keyset,values,contains都会带来性能问题,或者这些方法返回的数据本身就是不可用的,在实际应用中应该谨慎使用。
AdvancedCacheMap<Long,User,Byte> userCache= = cacheAccessable.createAdvancedMap("userCache", userCacheLoader, true, 2000);
//为什么不推荐使用?
public boolean contains(Long updateValue) { return userCache.contains(updateValue); }
//为什么不推荐使用?
public void method(){
for(Long key:userCache.keySet()){ }
}
# 复杂缓存对象
缓存数据在传输时,需要序列化为字符串,缓存对象尽量使用POJO对象,使用简单的Bean对象,不要讲复杂的,特别是树结构、循环依赖结构的对象放入缓存中,将会带来大量的序列化和网络开销。
# 其他
# 直接操作Redis
有些场景可能现有封装的组件并不能满足我们的要求,可以直接操作Redis
RedisOpt<String, String, String> opt = RedisOptFactory.getStringInstance();
opt.get(key)
opt.set(key)
opt.hget(key,item)
opt.hset(key,item,value)
。。。。
但是在项目中不推荐直接操作Redis,原因如下: 1.无法进行统一管理,通过现有的监控工具查看缓存使用情况。 2.需要直行处理序列化。 3.缓存组件除了支持Redis还支持单机模式无需Redis的情况,需要自行实现兼容。
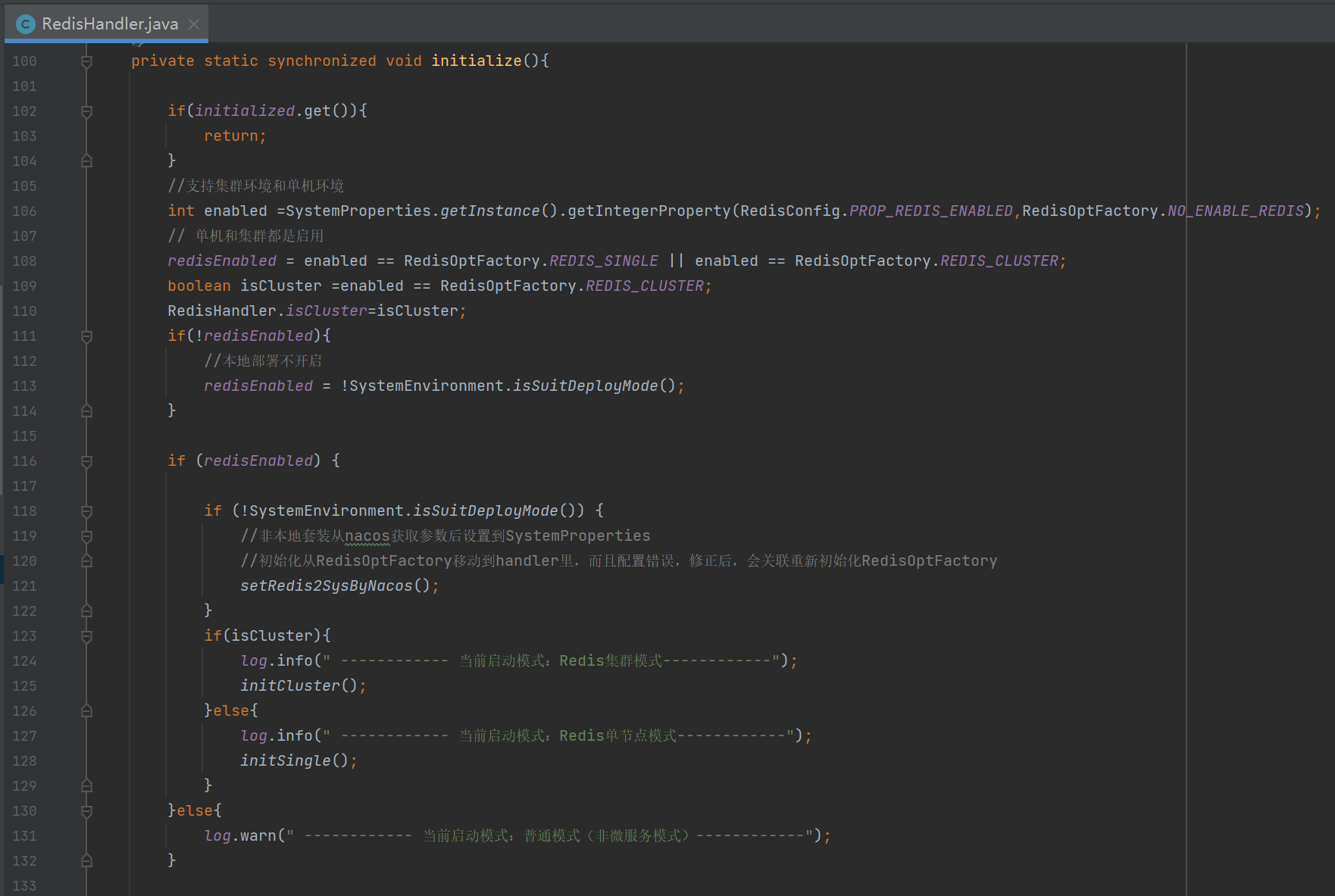
# OA集成Redis底层接入位置
OA是使用Jedis组件连接Redis服务,代码初始启动连接Redis的地方在:\ctp-core\src\main\java\com\seeyon\ctp\component\cache\redis\RedisHandler.java
初始入口:initialize()
initialize()通过读取配置文件判断走单机Redis还是三主三从Redis
单机Redis连接走initSingle()
三主三从Redis连接走initCluster()
# 常见问题
Redis缓存问题排查思路包括: 1.查看logs_sy/cache.log,logs_sy/performance.log,logs_sy/ctp.log日志文件中是否存在与Redis相关的报错 2.进入系统控制台查看缓存数据是否一致
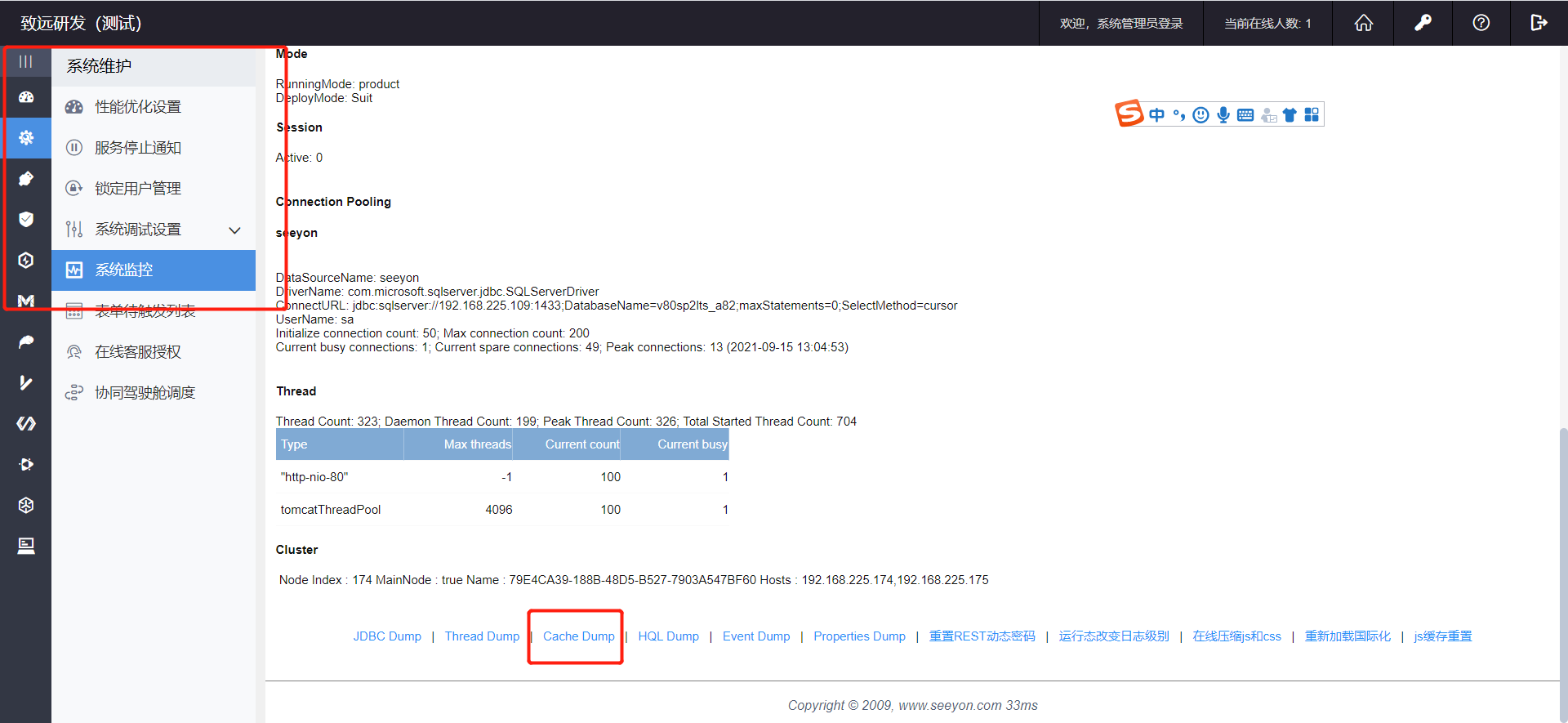
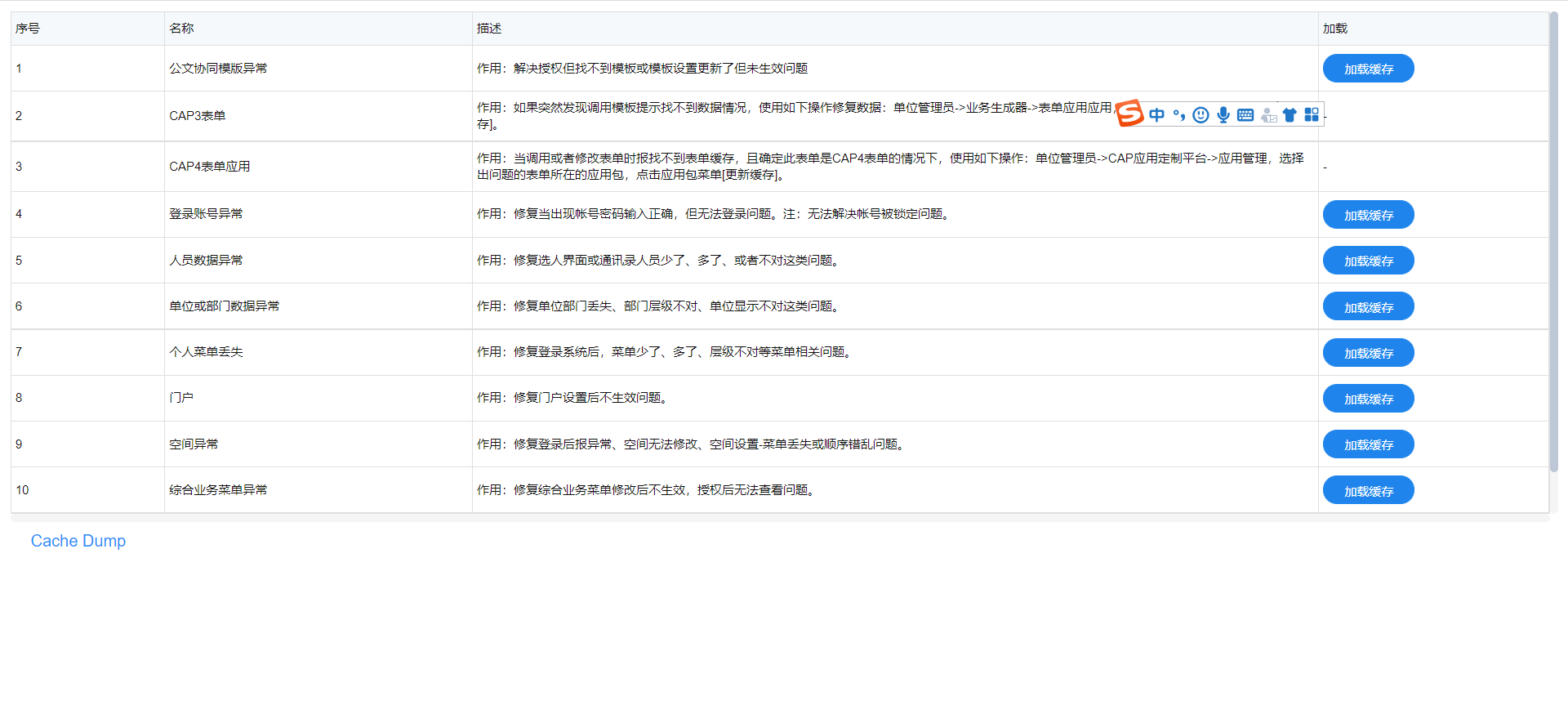
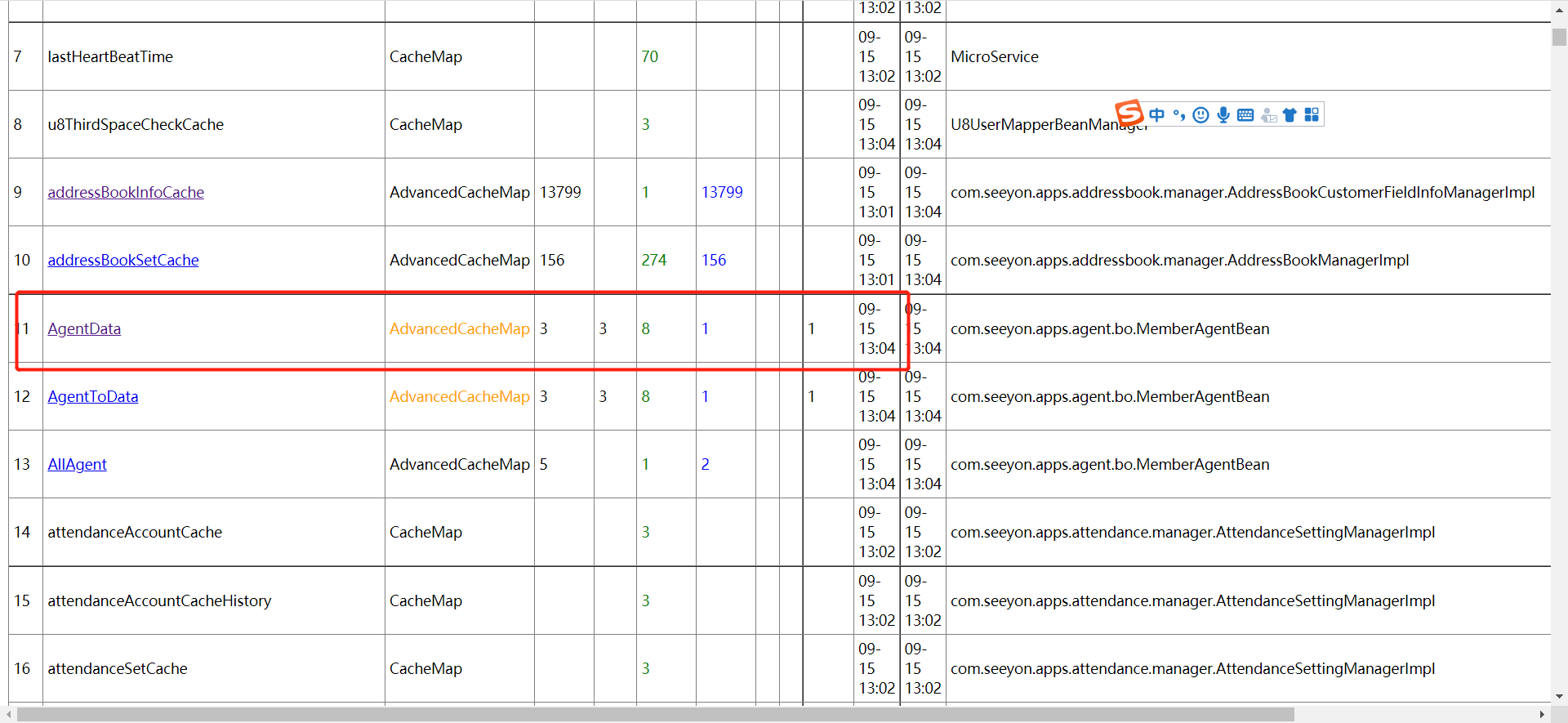
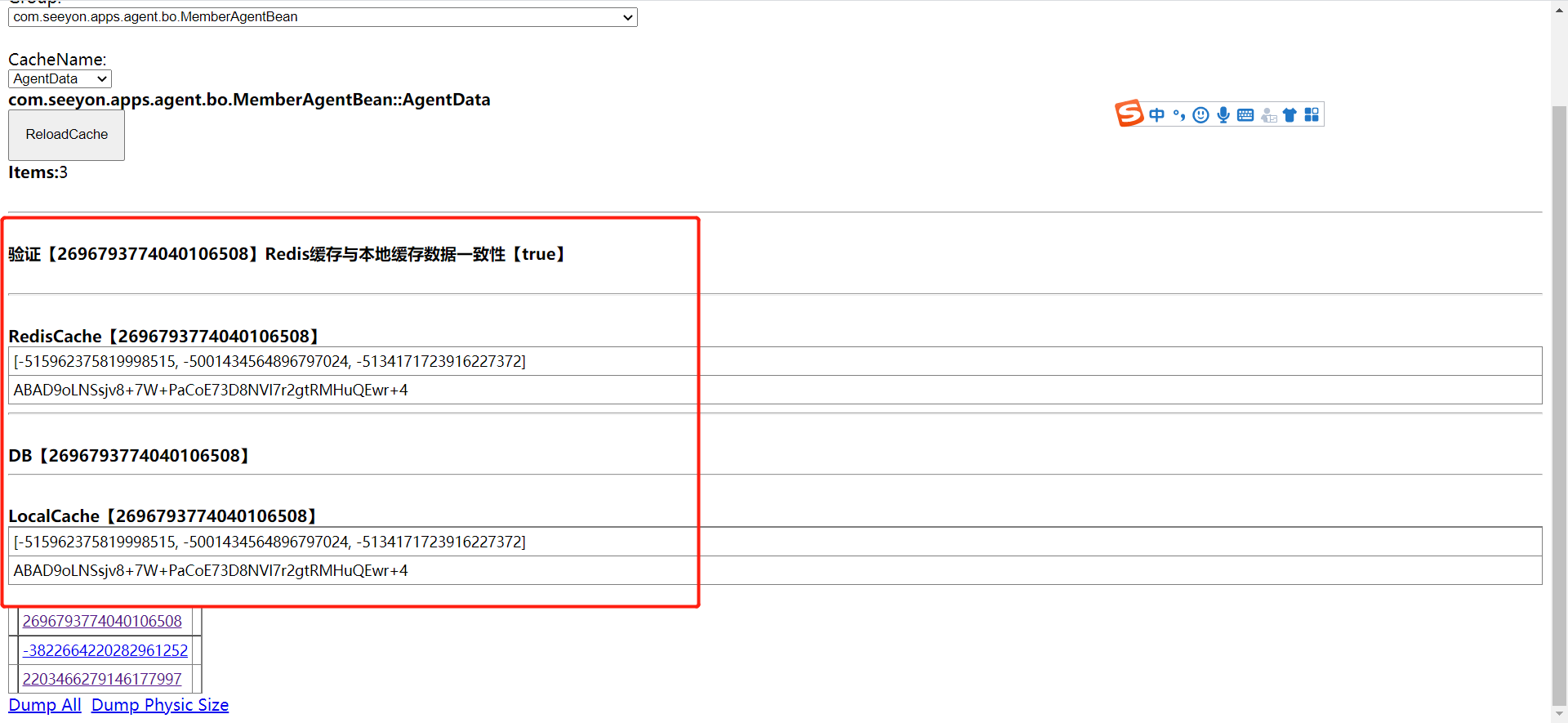
3.检查Redis运行情况
集群缓存配置
单节点登录
$redis-cli -h host -p port -a password -c
查看运行情况
> info
集群
$redis-cli -h host -p port -a password -c
查看集群状态
> cluster nodes
登录到主节点,执行info命令查看状态
快速跳转
