# 适配第三方数据库解决方案
# 适合人群
本文档适合后端开发人员阅读(包括有标准产品定制开发基础的客开人员)
# 前言
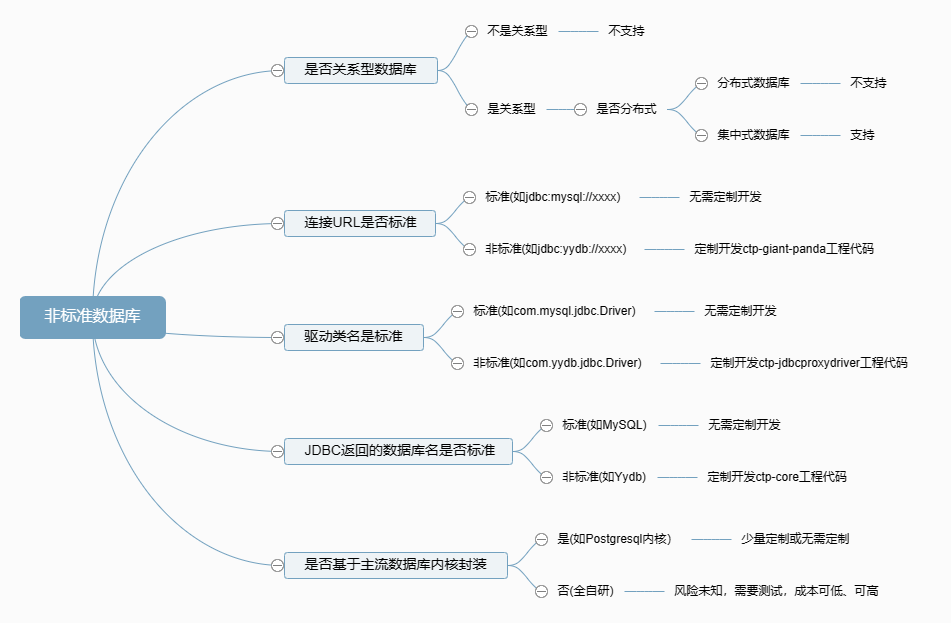
标准产品适配了很多数据库厂商,然而信创数据库厂商千千万,数据库类型层出不穷。不同客户总会选择一些非标的数据库,此时就需要评估是否进行代码适配。
首先,可以明确的是不是所有非标数据库都需要代码适配:
- 第一类:不少信创数据库只是在主流数据库基础上做了微小包装,驱动、连接方式都是用原厂的,比如OceanBase for MySQL、TDSQL for MySQL内核都是MySQL,驱动也用的MySQL,这些就当作MySQL数据库去部署即可,无需任何二次开发;
- 第二类:有的数据库则在开源数据库内核基础上做了一定的封装,比如瀚高、海量就是Postgresql的包装,但运行时可能存在一些关键字或转换报错,需要联系厂商执行一些SQL做转换适配,我们无需二次开发;
- 第三类:有的数据库厂商则是做了深度包装或大的改动,比如GaussDB for OpenGauss,就是Postgresql内核,但连接URL、驱动名都是自己的,此时我们就需要做一定的代码适配;
- 第四类:有的数据库可能是自己写的底层或做了巨大改动,SQL语法只是遵循某个主流数据库语法,但不全部遵循,比如南大通用,此类数据库需要与厂商首先确认使用哪一套通用数据库SQL语法,在遇到语法不匹配的时候,让厂商进行定制修改,此类数据库适配周期较长;
- 第五类: 是否是分布式分片数据库, 如果数据库要做分片键,则产品不支持
按照1~4类数据库厂商类型,适配成本从小到大依次是:第一类<第二类<第三类<第四类。
# 如何判断新数据库是否需要代码适配?
我们先回顾一段Java JDBC入门代码:
String url = "jdbc:mysql://localhost:3306/mydb";
String user = "root";
String password = "password";
// 加载MySQL JDBC驱动
String driverName = "com.mysql.jdbc.Driver";
Class.forName(driverName);
Connection conn = DriverManager.getConnection(url, user, password);
DatabaseMetaData metaData = conn.getMetaData();
// databaseName = MySQL
String databaseName = metaData.getDatabaseProductName();
以上JDBC连接代码最重要的有几个变量url、driverName、databaseName,万变不离其宗:新数据库厂商,也围绕这几个变量来确认适配可行性!
联系数据库厂商,让厂商提供如下问题的答案:
1、数据库连接URL是什么? 如果不是标准产品适配的这几家,则存在适配工作量。
2、数据库的JDBC驱动类名是什么? 如果不是主流数据库厂商的驱动类名,则存在适配工作量。
com.mysql.jdbc.Driver
oracle.jdbc.driver.OracleDriver
org.postgresql.Driver
com.microsoft.sqlserver.jdbc.SQLServerDriver
3、通过JDBC连接数据库获取DatabaseMetaData.getDatabaseProductName()值是什么? 如果不主流数据库厂商的名称,则存在适配工作量。
MySQL
Oracle
PostgreSQL
Microsoft SQL Server
4、当前数据库是基于哪一套主流库内核(Postgresql?MySQL?)做的二次封装?还是纯自研? 厂商如果是基于主流数据库内核做的封装,则可以使用咱们标准产品对应的数据库ALL IN ONE执行脚本初始化,以及代码也可以适配这套标准。
5、厂商是纯自研的话,那么自研数据库兼容Postgresql、MySQL、SQLServer、Oracle哪一套主流库语法? 比如厂商说完全兼容Oracle,则我们可以编写代码,让厂商库走Oracle逻辑。
6、检测指定表是否存在索引的SQL语句是否随主流库,还是自研系统表? 如果系统表与主流库厂商一致则不存在开发,如果自研系统表,则需要调整代码。
比如:虚谷遵守Oracle数据库语法标准,但检测是否存在索引的表与Oracle不同:Oracle是USER_IND_COLUMNS,虚谷是USER_TABLES, USER_COLUMNS, USER_INDEXES,则需要调整代码。
# 代码修改点
以GaussDB for OpenGuass数据库为例,存在几个非标选项,则需要做代码定制开发:
- 数据库URL是
jdbc:opengauss://127.0.0.1:30100/xxx?currentschema=pams&batchMode=false&reWriteBatchedInserts=off&blobMode=on - 数据库驱动类名是
com.huawei.opengauss.jdbc.Driver - 数据库databaseName是
Postgresql - 数据库是基于Postgresql内核做的二次封装
# 数据库连接URL适配:修改ctp-giant-panda项目(V9.0已迁移到ctp-panda项目)
注意V9.0开始已迁移到ctp-panda项目,V9.0之后从ctp-panda项目中寻找源码。
GaussDB for OpenGuass数据库URL是jdbc:opengauss://127.0.0.1:30100/xxx?currentschema=pams&batchMode=false&reWriteBatchedInserts=off&blobMode=on,没有在标准产品清单中,故需要在产品中进行注册。
1、修改ctp-giant-panda工程的com/seeyon/ctp/giant/panda/database/url/ValidateContext.java文件,增加数据库新产品名称:
public class ValidateContext {
忽略若干其它代码......
public static final String ORACLE = "oracle";
public static final String DM = "dm";
// 第一个修改点:增加opengauss常量 start
public static final String OPENGAUSS = "opengauss";
// 第一个修改点:增加opengauss常量 end
忽略若干其它代码......
public static JdbcValidateResult connectValidate(String url, Properties info) {
忽略若干其它代码......
if (urlTypeMatches(sourcesUrl,MYSQL_JDBC_TYPE)) {
jdbcUrlParamsValidate = new MysqlJdbcUrlParamsValidate(MYSQL_JDBC_TYPE);
} else if (urlTypeMatches(sourcesUrl, PG_JDBC_TYPE)) {
jdbcUrlParamsValidate = new PostgresqlJdbcUrlParamsValidate(PG_JDBC_TYPE);
} else if (urlTypeMatches(sourcesUrl, GBASE)) {
jdbcUrlParamsValidate = new JdbcUrlCommaParamsValidate(GBASE);
// 第二个修改点:判断数据库连接URL中带opengauss关键字则走opengauss通路 start
// 这里sourceUrl = jdbc:opengauss://127.0.0.1:30100/xxx?currentschema=pams&batchMode=false&reWriteBatchedInserts=off&blobMode=on
} else if (urlTypeMatches(sourcesUrl, OPENGAUSS)) {
jdbcUrlParamsValidate = new DefaultJdbcUrlParamsValidate(OPENGAUSS);
// 第二个修改点:判断数据库连接URL中带opengauss关键字则走opengauss通路 end
} else {
throw new RuntimeException("不支持的数据库类型,Url:" + sourcesUrl);
}
忽略若干其它代码.......
}
2、修改ctp-giant-panda工程的com/seeyon/ctp/giant/panda/database/url/jdbcParamsBlackWhiteList.properties文件,添加数据黑白名单,有对应key即可:
注:这里opengauss.white=中的opengauss对应的是ValidateContext.OPENGAUSS常量值
忽略若干配置......
kingbase8.white=clientEncoding,user,password
kingbase8.black=
# 修改点:增加两行opengauss的参数,等号后面的信息可以为空start
opengauss.white=
opengauss.black=
# 修改点:增加两行opengauss的参数,等号后面的信息可以为空end
注:如果ctp-giant-panda工程的com/seeyon/ctp/giant/panda/database/url目录下是vendorDriverUrlWhiteList.properties文件,也可以这样添加key:
忽略若干配置......
kingbase8=
oscar=
opengauss=
# 数据库驱动类名适配:修改ctp-jdbcproxydriver项目
GaussDB for OpenGuass数据库驱动类名是com.huawei.opengauss.jdbc.Driver,没有在标准产品清单中,故需要在产品中进行注册。
1、修改ctp-jdbcproxydriver工程com/seeyon/ctp/monitor/perf/jdbcmonitor/proxyobj/ProxyDriverList.properties文件添加驱动
忽略若干配置......
com.kingbase8.Driver=jdbc:kingbase8://127.0.0.1:54321/mydatabase
com.oscar.Driver=jdbc:oscar://127.0.0.1:2003/mydatabase
com.gbasedbt.jdbc.Driver=jdbc:gbasedbt-sqli://127.0.0.1:9088/gbasev5:GBASEDBTSERVER=mydatabase;SQLMODE=Oracle;DBDATE=Y4MD-;DB_LOCALE=zh_CN.57372;
# 修改点:增加GaussDB for OpenGuass数据库驱动类名 start
com.huawei.opengauss.jdbc.Driver=jdbc:opengauss://127.0.0.1:30100/mydatabase
# 修改点:增加GaussDB for OpenGuass数据库驱动类名 end
注:这个配置文件最重要的是要有com.huawei.opengauss.jdbc.Driver驱动类名,至于类名=等号后面的URL只是一个Demo,不用写客户真实地址
2、修改ctp-jdbcproxydriver工程src/main/resources/META-INF/services/java.sql.Driver连接池驱动代理类为如下固定参数:
注:V8.1SP1及之后的版本已经默认内置,如果发现代码中已经有此配置则无需修改本步
com.seeyon.ctp.monitor.perf.jdbcmonitor.proxyobj.JMProxyDriver
# 非标数据库databaseName适配:需要修改多处代码
# 数据库名称非标准,为什么要做多处修改?
这一段内容非常重要,请开发理解透彻,以便做好准确的适配!
如果通过JDBC连接,调用DatabaseMetaData.getDatabaseProductName()返回的数据库名称是非标准支持的库名,假设GaussDB返回的就是“GaussDB”,则意味着这个数据库是一个“黑户”,标准产品不知道这个数据库用什么Hibernate方言、也不知道用什么SQL语法兼容。
解决方案就是:让这个新数据库告知我们,他们遵守的是Oracle、SQLServer、Postgresql、MySQL主流数据库里面的哪一家SQL语法?只要遇到这个数据库时则执行主流数据库的代码逻辑。
# 非标数据库名适配点:修改ctp-core项目
假设:新数据库厂商的DatabaseMetaData.getDatabaseProductName() = GaussDB,并且厂商基于Postgresql内核做的改造,遵守PG数据库SQL语法。技术上我们需要识别到名为GaussDB数据库标识时,让其走Postgresql的代码逻辑,具体修改点如下:
1、修改ctp-core项目com/seeyon/ctp/util/JDBCAgent.java新增对应数据库的判断方法:
public final class JDBCAgent implements Closeable{
public static boolean isPostgreSQLRuntime(){
String dbType = getDBType();
if(dbType == null){
return false;
}
// 修改点:增加dbType.contains("GaussDB")判断,如果当前环境是GaussDB,则返回true,让其走PG代码逻辑 start
return dbType.contains("postgresql") || dbType.contains("GaussDB");
// 修改点:增加dbType.contains("GaussDB")判断,如果当前环境是GaussDB,则返回true,让其走PG代码逻辑 end
}
忽略若干其它代码......
}
2、修改ctp-core项目org/hibernate/dialect,在目录下新增一个方言类:
package org.hibernate.dialect;
/**新增一个方言类,继承PG方言**/
public class CTPGaussDBSQLDialect extends CTPPostgreSQLDialect{
// 内部实现可以为空,除非新库Dialect具有特殊性,否则可以完全使用PGDialect特性
}
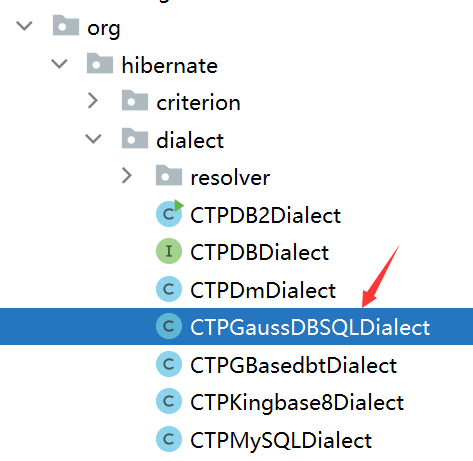
3、修改ctp-core项目org/hibernate/dialect/resolver/CTPDialectResolver.java文件,增加对应方言的实现:
public class CTPDialectResolver extends AbstractDialectResolver {
private static final Logger log = LoggerFactory.getLogger(CTPDialectResolver.class);
protected Dialect resolveDialectInternal(DatabaseMetaData metaData) throws SQLException {
String databaseName = metaData.getDatabaseProductName();
if(AppContext.getCache(GlobalNames.CACHE_DATABASE_NAME_KEY)==null) {
AppContext.putCache(GlobalNames.CACHE_DATABASE_NAME_KEY, databaseName);
AppContext.putCache(GlobalNames.CACHE_DATABASE_NAME_LOWERCASE_KEY, databaseName.toLowerCase());
initJdbcDriverBooleanConfig(databaseName);
}
if ("MySQL".equals(databaseName)) {
return new CTPMySQLDialect();
}
// 修改代码:增加新数据库的方言注册信息 start
if ("GaussDB".equals(databaseName)) {
return new CTPGaussDBSQLDialect();
}
// 修改代码:增加新数据库的方言注册信息 end
if ("PostgreSQL".equals(databaseName)) {
return new CTPPostgreSQLDialect();
}
忽略若干其它代码......
}
注:如果你嫌麻烦,可以忽略修改点2,直接进行修改点3,让程序判断数据库为GaussDB时,走CTPPostgreSQLDialect方言。有第2步的好处是方便数据库做特殊定制。
# 系统表纯自研:查询表索引适配点
产品中涉及查询数据库的系统表,比如索引记录表,用于判断是否存在索引,虚谷遵守Oracle数据库语法标准,但检测是否存在索引的表与Oracle不同:Oracle是USER_IND_COLUMNS,虚谷是USER_TABLES, USER_COLUMNS, USER_INDEXES,则需要调整代码,适配虚谷。
代码位置cap-api\src\main\java\com\seeyon\ctp\form\bean\FormTableIndexBean#searchIndexSql
/**
* 检测动态表列是否存在索引的SQL语句
*/
private String searchIndexSql(String tableName, String columnName) {
if (ReportDBUtils.isOracleRuntime()) {//oracle数据库;
String sql = null;
if(ReportDBUtils.isXuGuRuntime()) {//可以判断请求URL带xugu关键字
StringBuffer buffer = new StringBuffer();
buffer.append("SELECT USER_INDEXES.INDEX_NAME, USER_TABLES.TABLE_NAME, USER_COLUMNS.COL_NAME FROM USER_TABLES, USER_COLUMNS, USER_INDEXES ");
buffer.append("WHERE USER_TABLES.TABLE_ID = USER_COLUMNS.TABLE_ID AND USER_TABLES.TABLE_ID = USER_INDEXES.TABLE_ID");
buffer.append("and USER_TABLES.TABLE_NAME = Upper('" + tableName + "') ");
buffer.append("AND USER_COLUMNS.COL_NAME= Upper('" + columnName + "') ");
buffer.append("AND USER_INDEXES.INDEX_NAME IN (");
buffer.append(" SELECT USER_INDEXES.INDEX_NAME FROM USER_INDEXES UI, USER_TABLES UT WHERE UI.TABLE_ID = UT.TABLE_ID");
buffer.append(" AND UT.TABLE_NAME = Upper('" + tableName + "') GROUP BY UI.INDEX_NAME HAVING COUNT(*)=1");
buffer.append(")");
sql = buffer.toString();
} else {
//since 20200904 sqlserver 转达梦数据库后,索引的名称变了(如INDEX12258405396505042),已经不能通过以前的索引名称去判断 索引是否存在。应该是查询当前列是否存在 单列索引
sql = "SELECT INDEX_NAME,TABLE_NAME,COLUMN_NAME FROM USER_IND_COLUMNS WHERE TABLE_NAME = Upper('" + tableName + "') AND COLUMN_NAME= Upper('" + columnName + "')" +
" AND INDEX_NAME IN " +
"(SELECT INDEX_NAME FROM SYS.USER_IND_COLUMNS uic WHERE uic.TABLE_NAME = Upper('" + tableName + "') GROUP BY INDEX_NAME HAVING COUNT(*)=1) ";
}
LOGGER.info("searchIndexSql:"+sql);
return sql;
忽略若干其它代码......
}
# 环境运维:将新数据库URL注册到OA系统中
以上完成后,除了编译打补丁到OA环境下,还需要在OA配置相关数据库信息:
如果是X86系统,默认Tomcat中间件,直接修改base下数据库连接base\conf\datasourceCtp.properties文件,确保存在如下信息:
信创下根据对应中间件做配置
ctpDataSource.driverClassName=com.huawei.opengauss.jdbc.Driver
ctpDataSource.url=jdbc:opengauss://127.0.0.1:30100/pamsdbsit?currentschema=pams&batchMode=false&reWriteBatchedInserts=off&blobMode=on
ctpDataSource.username=数据库帐号
ctpDataSource.password=数据库密码(建议通过SeeyonConfig随意选一个数据库设置密码后保存生成)
另外增加druid连接空闲检测和keepalive保活参数是必须的:修改base下数据库连接base\conf\datasourceCtp.properties文件:
# 连接空闲检测
ctpDataSource.druid.timeBetweenEvictionRunsMillis=60000
ctpDataSource.druid.validationQuery=select 1
ctpDataSource.druid.validationQueryTimeout=10
ctpDataSource.druid.testOnBorrow=true
# 从连接池重用一个空闲连接时,会根据连接的空闲时间决定是否执行 validationQuery 去判断连接的有效性
ctpDataSource.druid.testWhileIdle=true
# 获取连接时最大等待时间,单位毫秒,5分钟
ctpDataSource.druid.maxWait=300000
# 连接保持空闲而不被驱逐的最小时间 3分钟
ctpDataSource.druid.minEvictableIdleTimeMillis=180000
# 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。
ctpDataSource.druid.keepAlive=true
# 查询超时时间 - 单位是秒 默认不限时,设置最大时间30分钟
ctpDataSource.druid.queryTimeout=1800
备注:ctpDataSource.druid.validationQuery不同数据库的探活SQL参考:
Oracle: select 1 from dual
Oscar(神州通用): select 1
MySQL: select 1
Microsoft SqlServer: select 1
Postgresql select 1
DM jdbc:dm select 1
KingBase(人大金仓): select 1
GBase (南大通用): select 1 from dual
openGuess高斯数据库: select 1
# 非必须:修改ctp-log-elasticsearch项目
如何确认是否需要修改ctp-log-elasticsearch项目:参考前文JDBCAgent实现,如果是在JDBCAgent下新增了一个is新数据库Runtime方法则必然要修改ctp-log-elasticsearch项目,如果只是基于JDBCAgent#isPostgreSQLRuntime等现有方法做了修改,则不需要动ctp-log-elasticsearch项目。
1、修改ctp-log-elasticsearch项目com.seeyon.ctp.log.jdbc.common.DatabaseType.java新增对应数据库类型:
public enum DatabaseType {
// 修改代码:增加新数据库 start
GAUSSDB {
@Override
public String getValue() {
return "gaussdb";
}
},
// 修改代码:增加新数据库 end
ORACLE {
@Override
public String getValue() {
return "oracle";
}
},
忽略其它代码......
}
2、修改ctp-log-elasticsearch项目com.seeyon.ctp.log.jdbc.sql.create包目录下,增加新数据库的实现:
/**新增实现类GaussDBCreateTableSqlBuilder**/
public class GaussDBCreateTableSqlBuilder extends AbstractCreateTableSqlBuilder {
@Override
protected DatabaseType getDatabaseType() {
return DatabaseType.GAUSSDB;
}
}
3、修改ctp-log-elasticsearch项目com.seeyon.ctp.log.jdbc.sql.create.CreateTableSqlBuilders.java文件,增加新数据库的Builder注册接口:
public class CreateTableSqlBuilders {
// 修改代码:增加GaussDB注册接口 start
public static CreateTableSqlBuilder gaussdb() {
return new GaussDBCreateTableSqlBuilder();
}
// 修改代码:增加GaussDB注册接口 end
public static CreateTableSqlBuilder oracle() {
return new OracleCreateTableSqlBuilder();
}
public static CreateTableSqlBuilder mysql() {
return new MysqlCreateTableSqlBuilder();
}
忽略其它代码......
}
4、修改ctp-log-elasticsearch项目com.seeyon.ctp.log.jdbc.sql.dialect包目录,增加新数据库的方言实现类:
由于前面假设了GaussDB走的PG内核,故我们可以extends PostgresDialect
package com.seeyon.ctp.log.jdbc.sql.dialect;
import com.seeyon.ctp.log.jdbc.sql.create.CreateTableSqlBuilders;
import java.util.List;
class GaussDBDialect extends PostgresDialect {
@Override
public List<String> ddlOf(String table) {
// 重写ddlOf,让其实现走GaussDB自己的Builder
return CreateTableSqlBuilders.gaussdb().build(table);
}
}
5、修改ctp-log-elasticsearch项目com.seeyon.ctp.log.jdbc.sql.dialect.SqlDialects.java,增加新数据库的调用方法:
public class SqlDialects {
// 修改代码:增加新方言的调用方法 start
public static SqlDialect gaussdb() {
return new GaussDBDialect();
}
// 修改代码:增加新方言的调用方法 end
public static SqlDialect oracle() {
return new OracleDialect();
}
public static SqlDialect mysql() {
return new MySQLDialect();
}
忽略其它代码......
}
6、修改ctp-log-elasticsearch项目com.seeyon.ctp.log.jdbc.spi目录新增新数据库JDBCLogger的实现:
package com.seeyon.ctp.log.jdbc.spi;
/**由于我们假设GaussDB是PG内核,故可以extends PostgresLogger,否则需要extends AbstractJDBCLogger并参考其它代码编写内部实现**/
public class GaussDBLogger extends PostgresLogger {
private static final Log log = LogFactory.getLog(GaussDBLogger.class);
public GaussDBLogger(SqlSessionFactory sqlSessionFactory) {
super(sqlSessionFactory);
}
@Override
public SqlDialect getDialect() {
return SqlDialects.gaussdb();
}
}
7、修改ctp-log-elasticsearch项目com.seeyon.ctp.log.LoggerBeanAutoConfiguration.java的
public class LoggerBeanAutoConfiguration {
private Logger getOtherJDBCLogger() {
SqlSessionFactory sessionFactory = SqlSessionFactorys.getSqlSessionFactory();
// 修改代码:新数据库走新的Logger注册start
if (JDBCAgent.新数据库())
return new GaussDBLogger(sessionFactory);
// 修改代码:新数据库走新的Logger注册end
if (JDBCAgent.isDMRuntime())
return new DMLogger(sessionFactory);
if (JDBCAgent.isKingBaseesRunTime())
return new KingBaseLogger(sessionFactory);
忽略其它代码......
}
忽略其它代码......
}
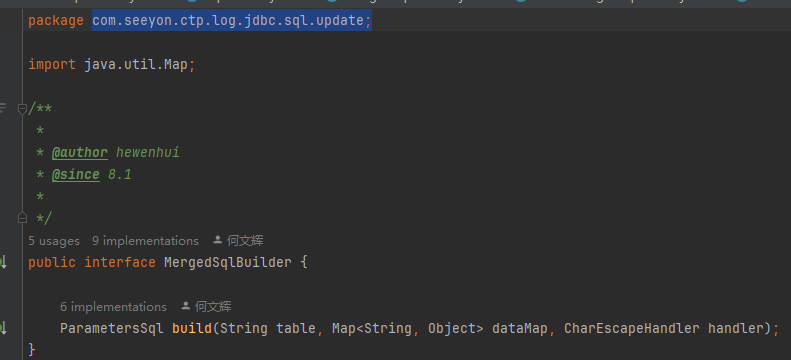
8、修改ctp-log-elasticsearch项目com.seeyon.ctp.log.jdbc.sql.update包模块需要做对应的实现,如新增Builder,以及在MergedSqlBuilder.java中提供Builder的实现,以及在SqlDialect#dmlOfmerged实现中调用该builder:
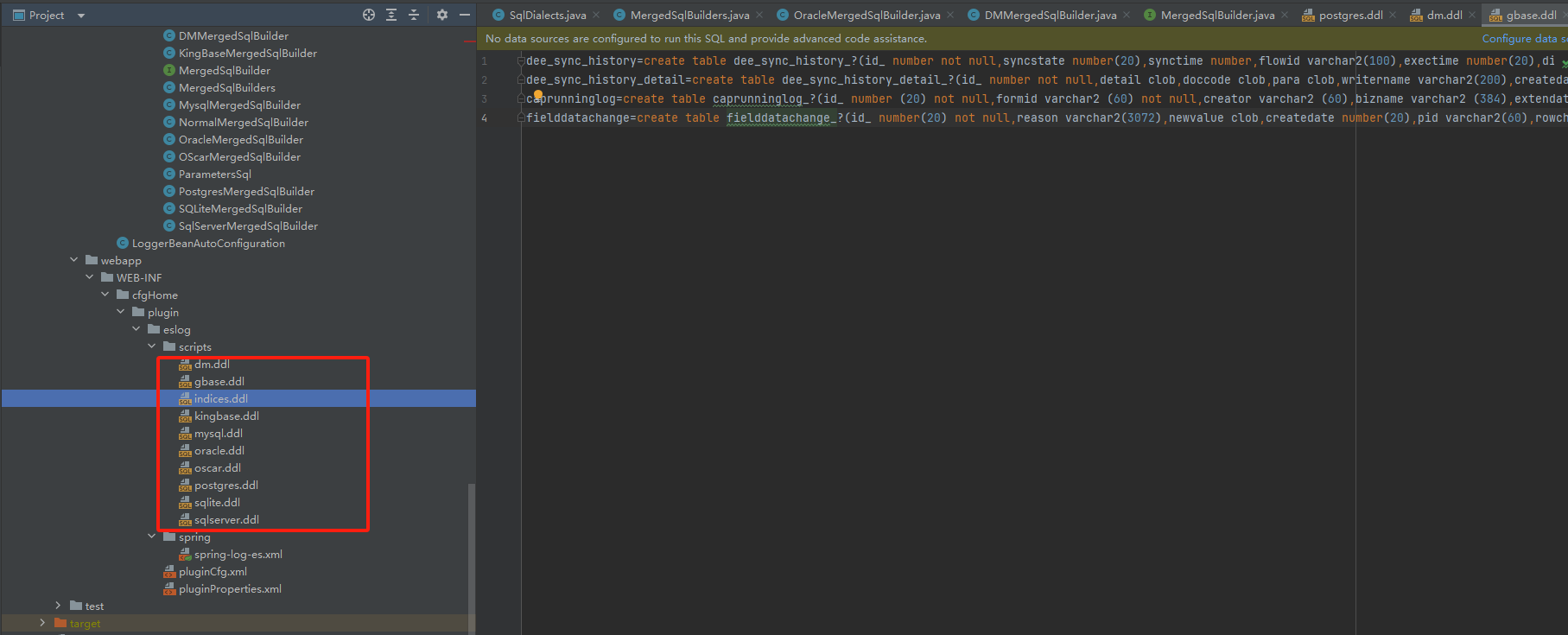
9、修改webapp/WEB-INF/cfgHome/plugin/eslog/scripts 增加对应数据库的建表语句
# 非必须:仅链路追踪组件需要
这一批代码99.999%的客户都无需适配,仅用于有项目化适配链路追踪的客户需求加这些代码:
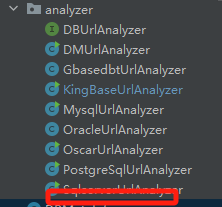
1、修改ctp-jdbcproxydriver工程com/seeyon/ctp/monitor/perf/jdbcmonitor/proxyobj/trace/analyzer下新增一个url的analyzer:
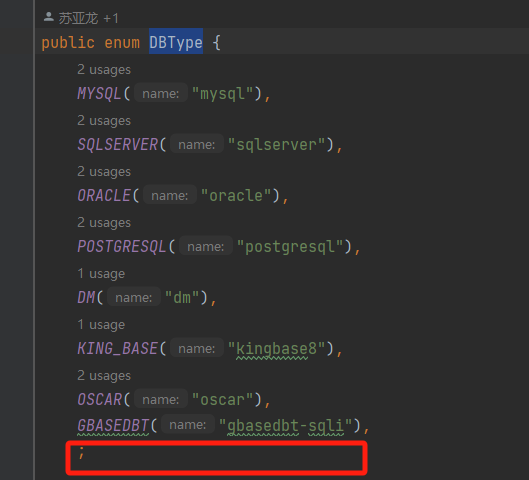
2、修改ctp-jdbcproxydriver工程DBType新增枚举
3、修改ctp-jdbcproxydriver工程DBMateInfo新增static里map设置
快速跳转
← 统一待办降版本适配手册 致信开发教程 →
