# V5压力测试工具和常见问题
# 压测工具下载
V5产品线压测工具、脚本、全套手册请访问:https://support.seeyon.com/cbo_cptjxx.html?id=1784406928019128321 (opens new window)
# 压测问题基本排查方法
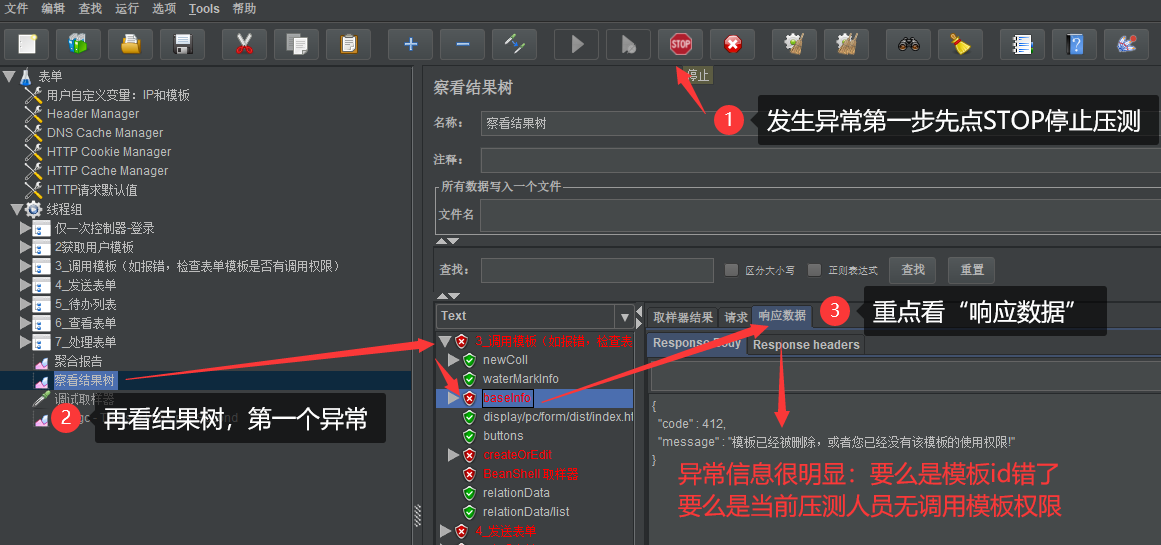
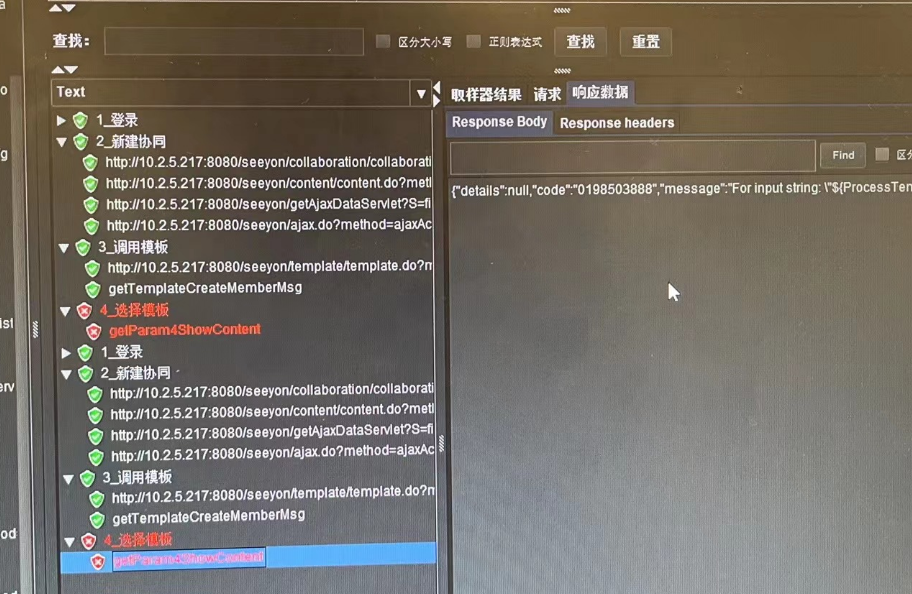
遇到压测报错,把查看结果树里面的"仅错误日志"取消勾选,再运行,点击报错的接口查看"响应数据"
然后参考如下方式获取压测错误信息:
# 1 压测登录报错
# 1-1 所有账号压测都登录报错(V9.0SP1)
V9.0SP1版本如果压测出现登录错误,第一步就参考本方案检查解决:
找到压测脚本中的说明,里面有一个V9.0SP1登录必打补丁,按照补丁说明打到OA中,再重启OA压测。
注意,压测完需要删除刚才打的补丁,并重启OA。
# 1-2 所有账号压测都登录报错(V10.0版本以上)
V10.0及以上版本如果压测出现登录错误,第一步就参考本方案检查解决:
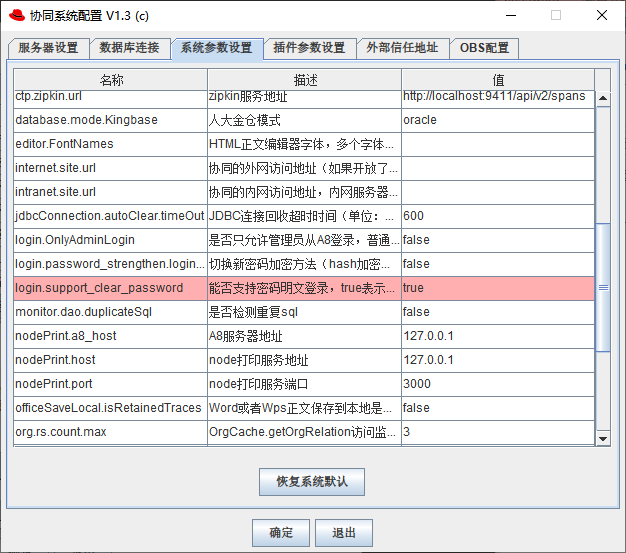
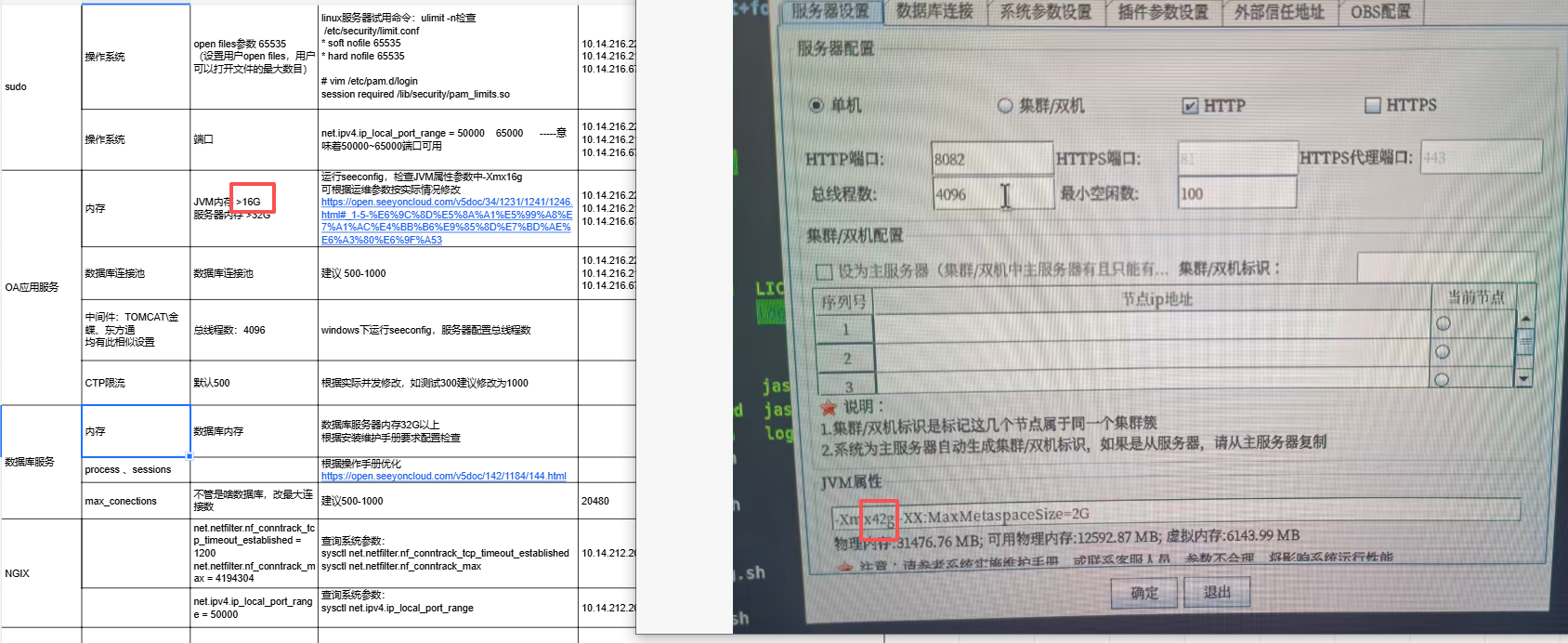
运行 SeeyonConfig,进入"系统参数设置"页签,将 login.support_clear_password 的值改成 true,参照下图,重启OA进行压测。
压测完成后,记得将其还原为false,确保密码以更安全的手段传输。
# 1-3 响应数据显示__LOGOUT
原因:登录用户名、密码不对导致__LOGOUT
解决方式:检查账号是否有空格、回车,检查密码是否正确!
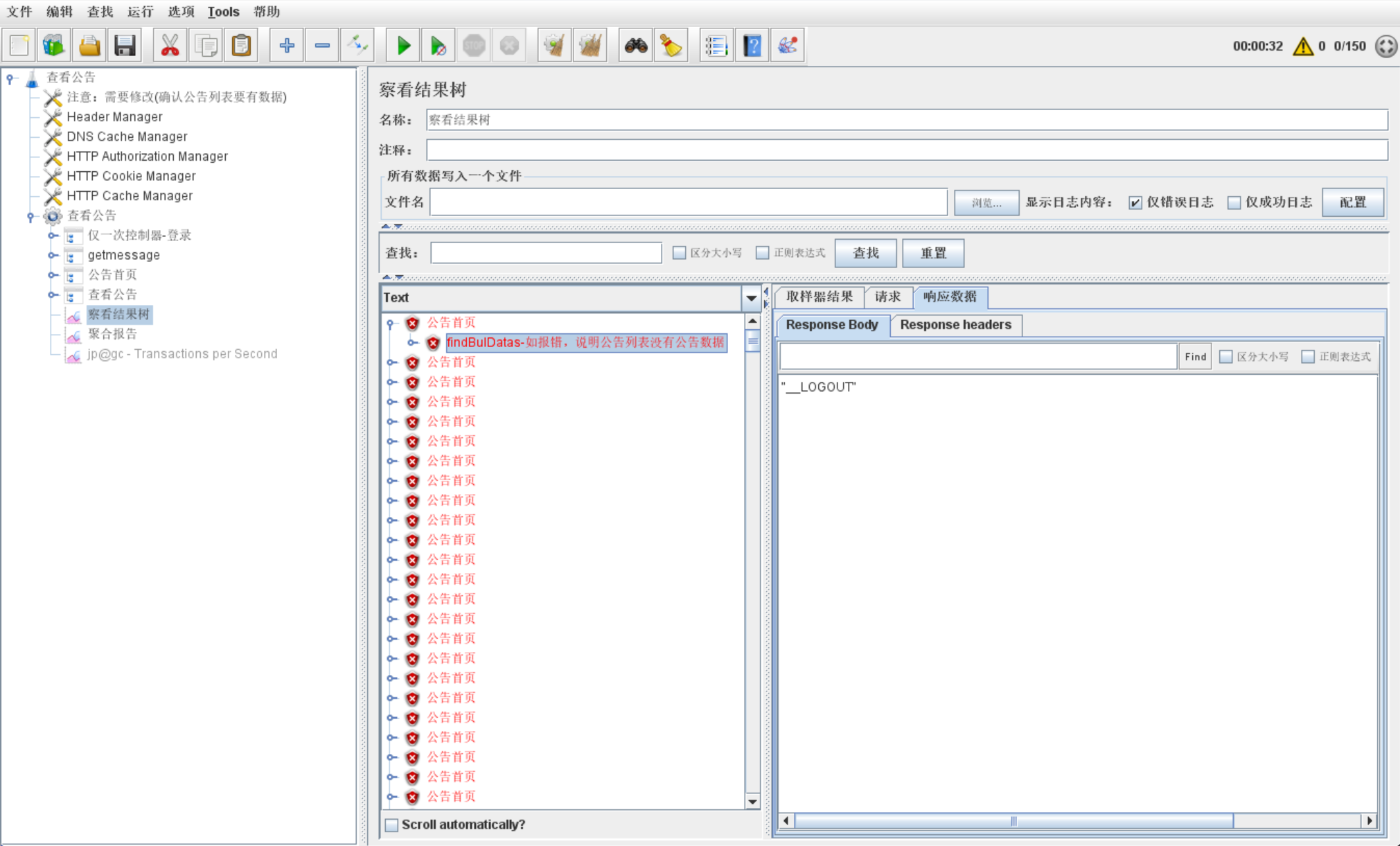
OA的日志会显示如下信息:

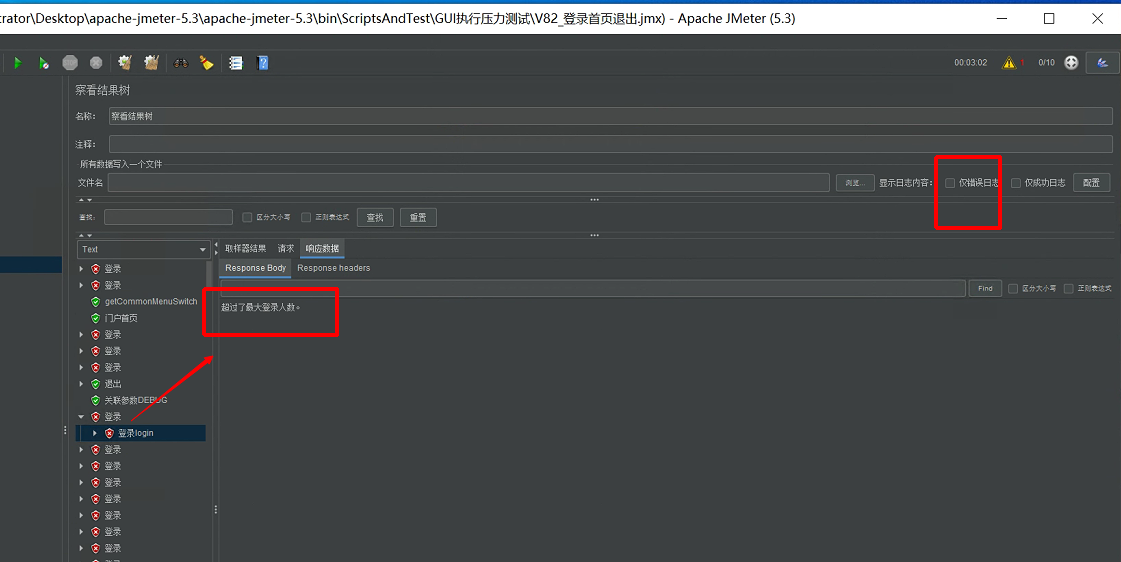
# 1-4 登录接口报错,提示超过了最大登录人数
解决方式:测试环境使用开发狗,并发数不够才提示登录报错,需要换成软加密狗,并发数 > 压测并发数
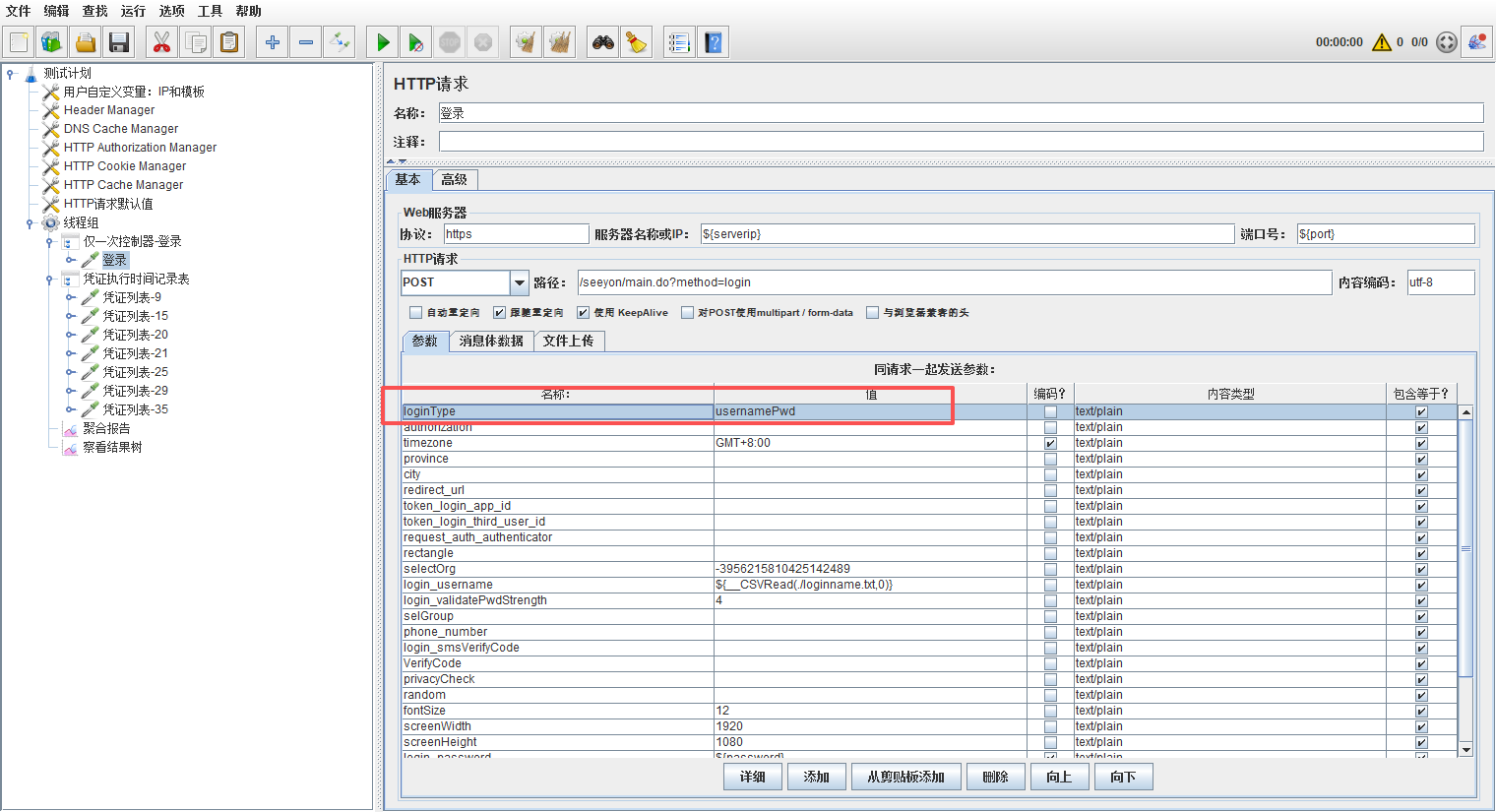
# 1-5 压测必打补丁 (登录接口补丁) 不兼容(G6-N9.0sp1)
G6-N9.0sp1 打上补丁后仍然不能登录,脚本增加 loginType 参数解决
# 1-6 其他登录报错可能原因
1、项目做了登录的定制开发,登录默认走了三方认证导致异常,需要客开关闭登录的客开代码,走标准产品的登录
2、项目开启了csrf——需要取后台关闭 csrf
# 2 表单公文报错
# 2-1 所有表单公文模板都报错
解决方式:
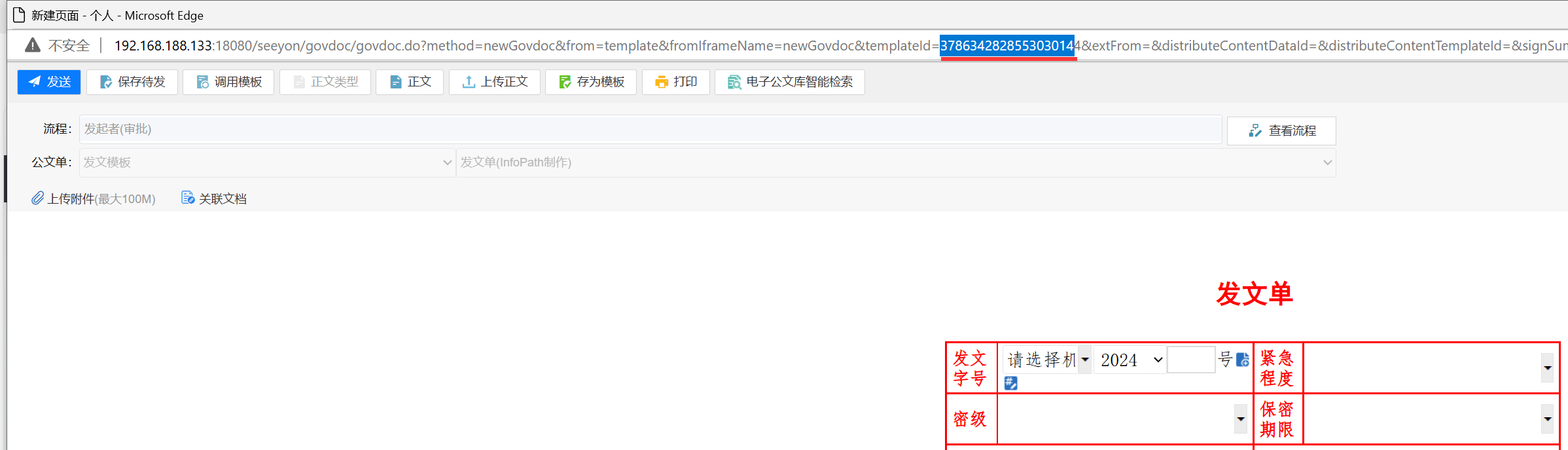
一般都是测试账号没有调用表单模板的权限,或填写模板的ID错误,测试人员误把模板后台的code编号当目标ID了!
取浏览器URL地址上面的templateId=后面的数字,更新到用户自定义变量配置中的模板ID上:
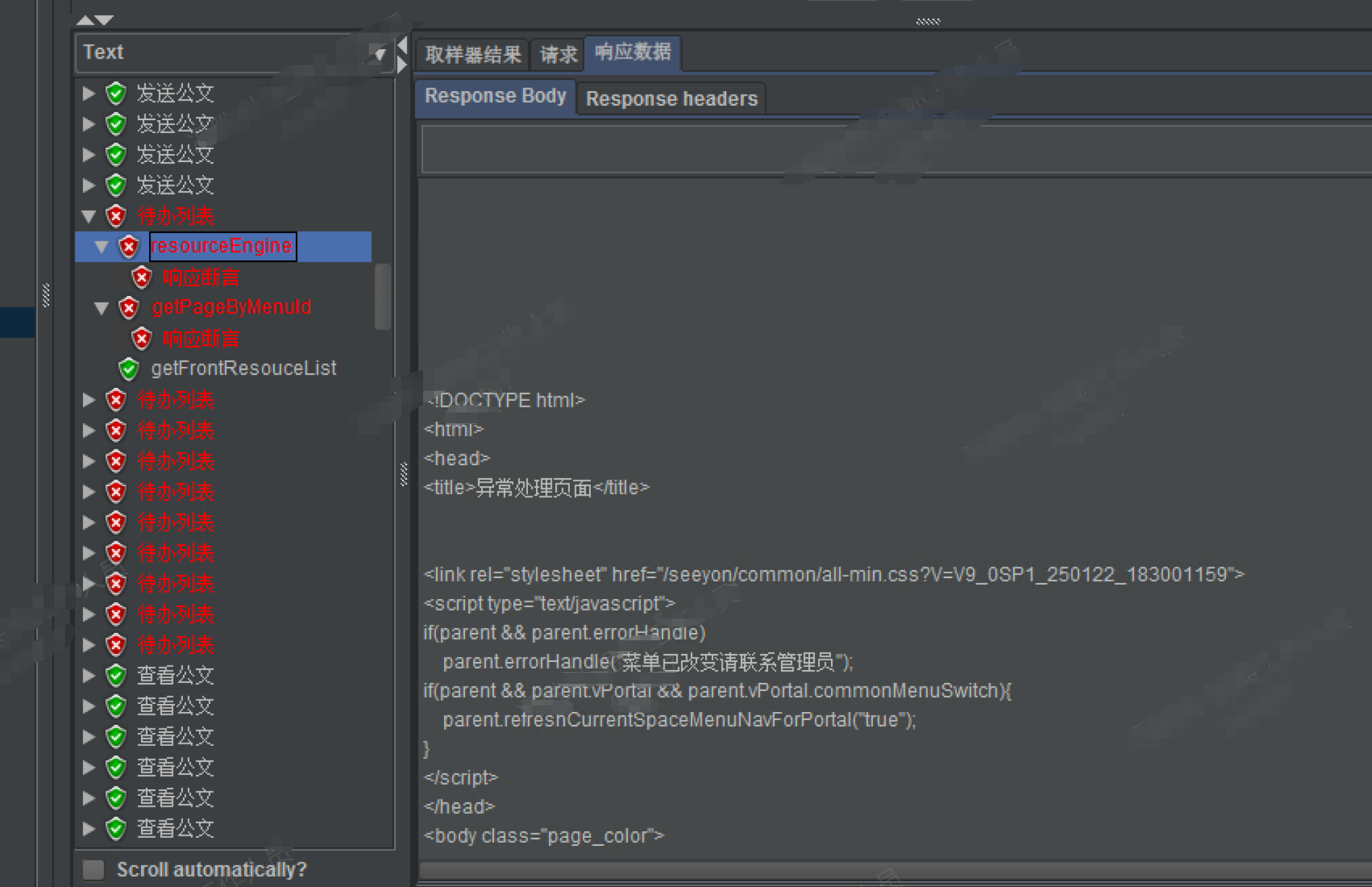
# 2-2 公文待办菜单报错-菜单已改变请联系管理员
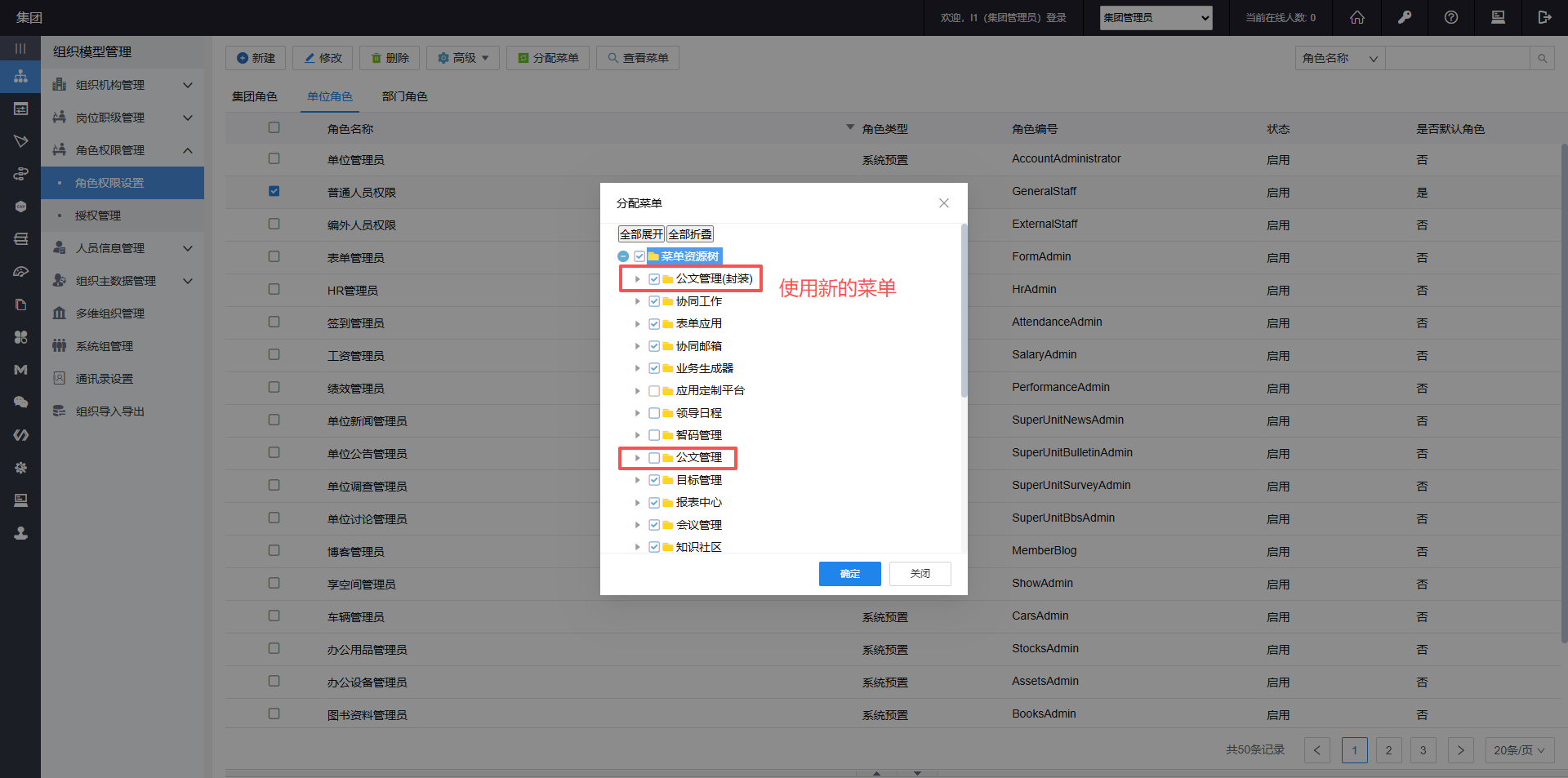
此问题出现在V9.0SP1,升级到V9.0SP1版本公文菜单不是新菜单,用最新的那套菜单就能解决问题,新版本压测的是最新菜单的脚本。
使用集团管理员登录,进入角色权限设置,切换到单位角色,将与公文管理相关的角色重新分配菜单。例如:普通人员权限、公文管理员、发文拟文人员、快速发文人员、单位公文送文员等。
V10.0及以上版本实测即便使用老的公文菜单,脚本也是可以执行通过。不存在上述问题,无需调整菜单。
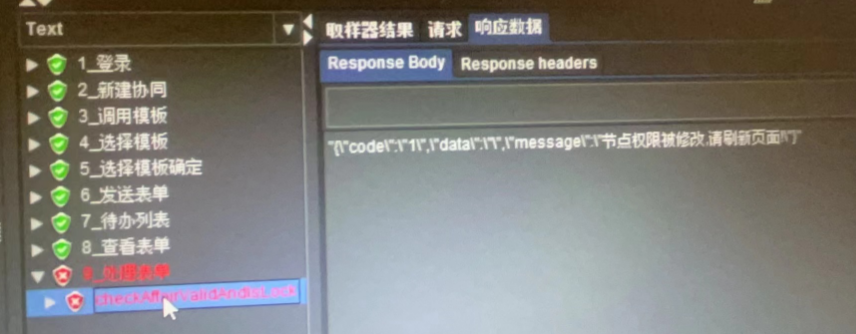
# 2-3 提示节点权限被修改 请刷新页面
解决方式:
没按照 ppt 来操作,流程模板第二个节点权限必须设置成发起者!
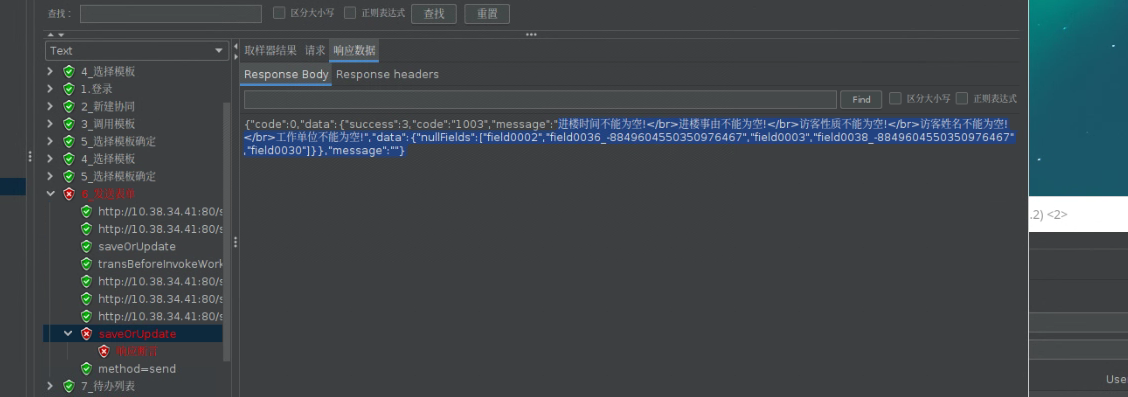
# 2-4 发送表单报错-xx不能为空
解决方式:修改表单模板,取消所有必填校验。压测所有节点要求字段非必填。
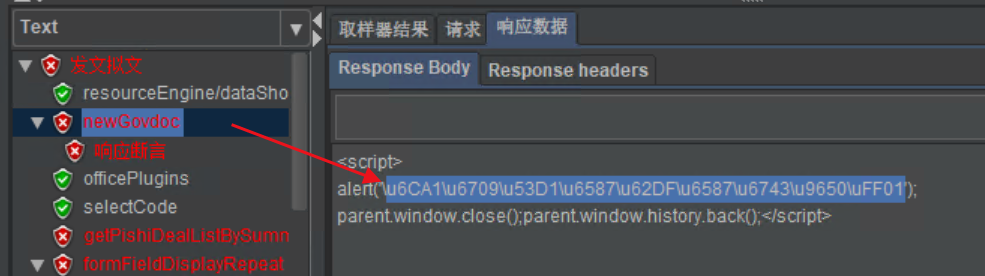
# 2-5 发文拟文报错
取Unicode 转码工具解析,发现返回错误是:没有发文拟文权限。
解决方案
问题已经很明确:某一个帐号,或多个压测帐号没有发文拟文权限。按照产品功能介绍,通过授权发文拟文角色就能获得对应权限。
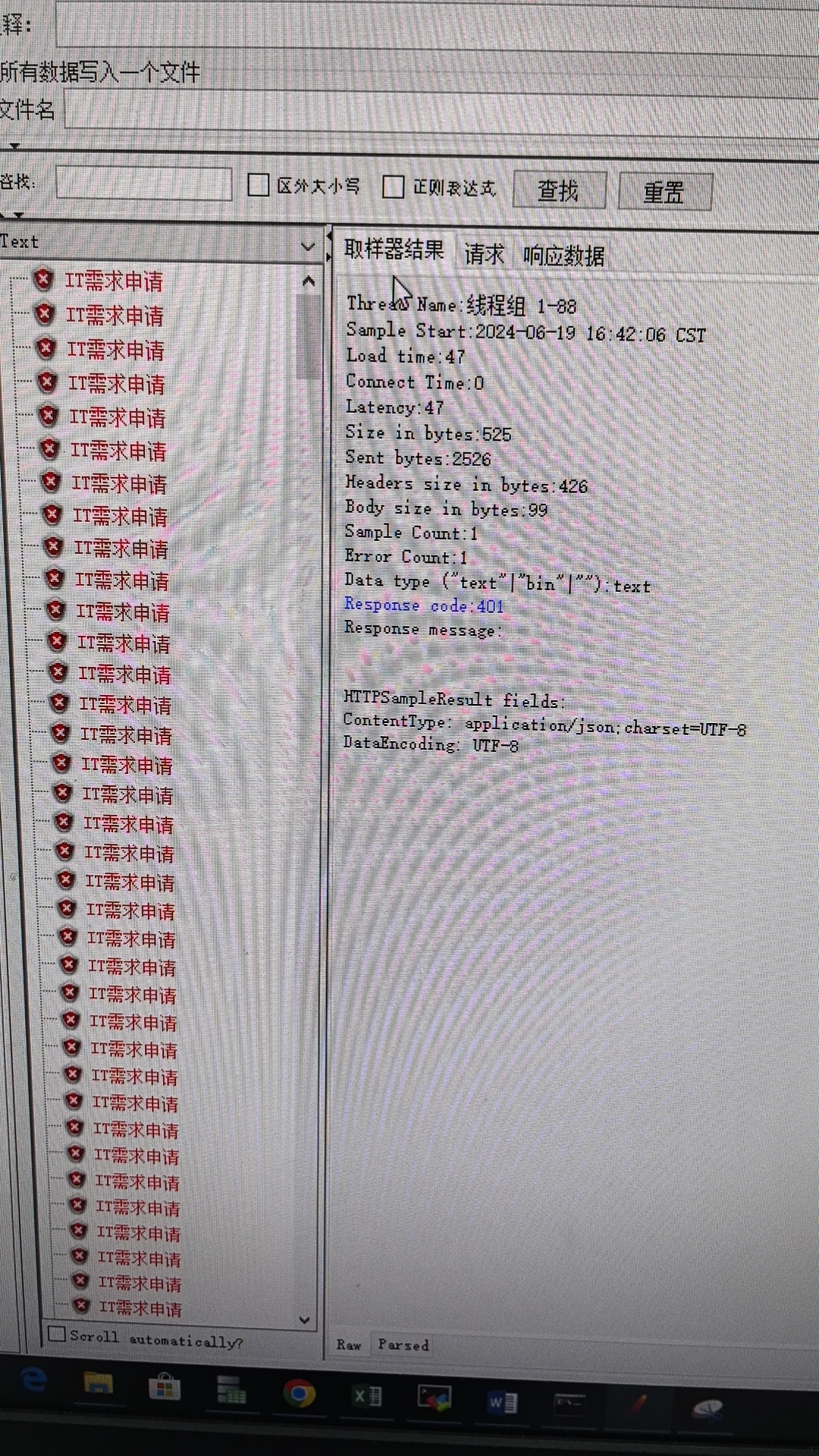
# 2-6 提示 401 错误
401 表示用户身份无权限,这种问题一般两种情况:
1、压测需要先进行登录,模拟登录获取用户身份后,再访问别的业务
2、压测的这个帐号没有访问对应业务的权限,本次问题是这个:压测时用了一个普通用户访问 CAP4 应用设计师角色才能访问的页面,被系统返回 401 拒绝
# 2-7 表单获取用户模板耗时非常久
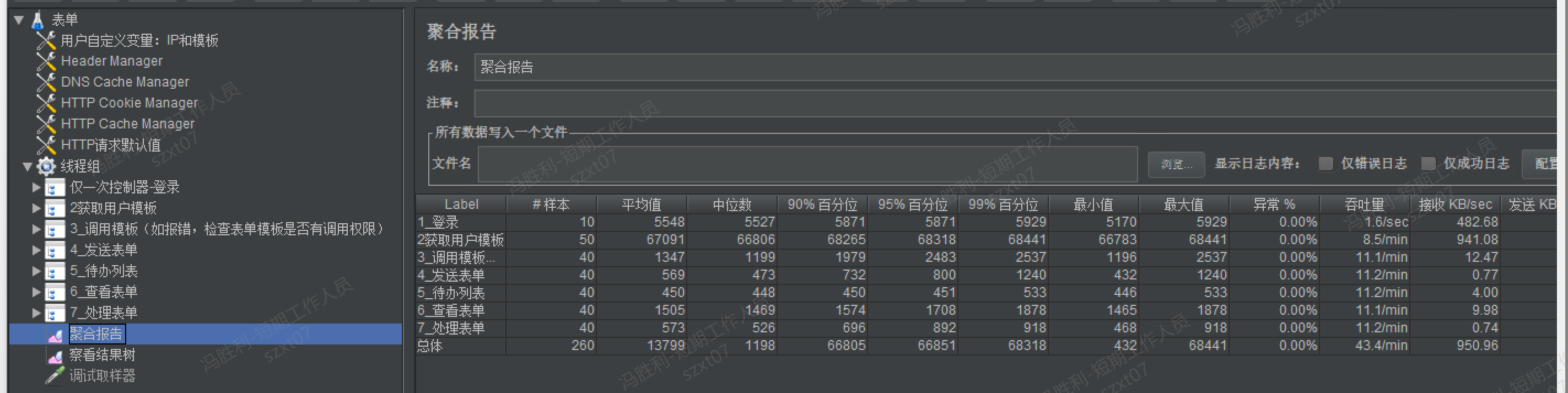
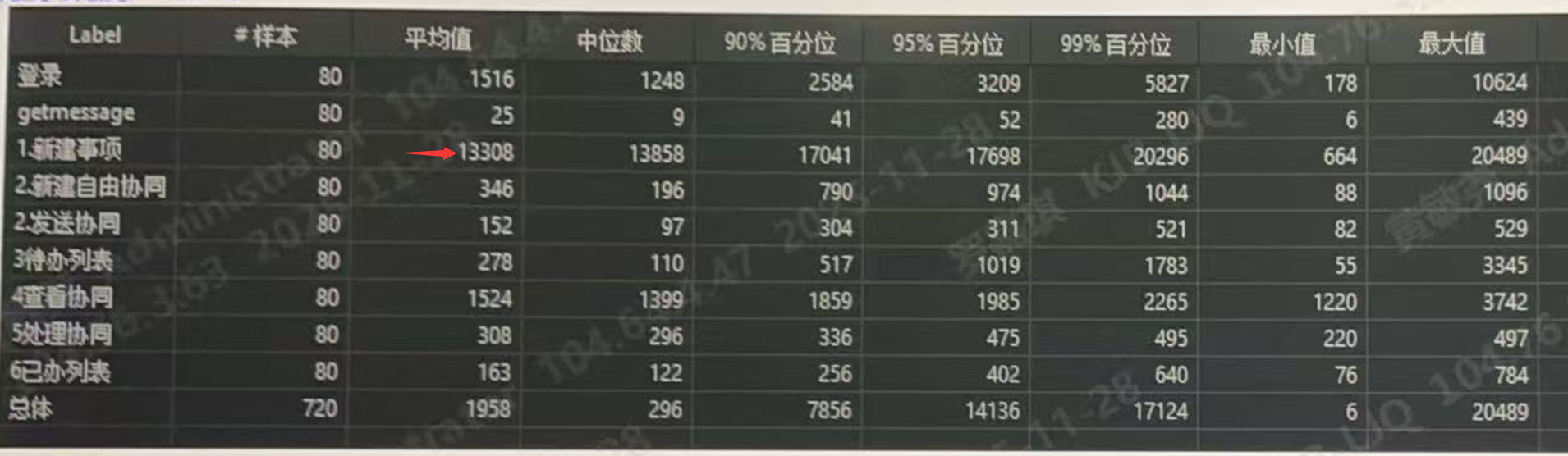
解决方案
通过后台抓取 Thread Dump 未见此线程的耗时,通过 capability.log 日志分析获取 myTemplate 模板耗时也非常短,在 1 秒以内。
尝试用当前电脑浏览器直接登录,查看我的模板页面,未见异常。
F12 清空缓存,重新打开我的模板,肉眼可见的加载缓慢。
再通过 NetWork 网络页签查看 myTemplate 获取我的模板请求,发现:我的模板数据 7M 以上,慢在下载数据场景。
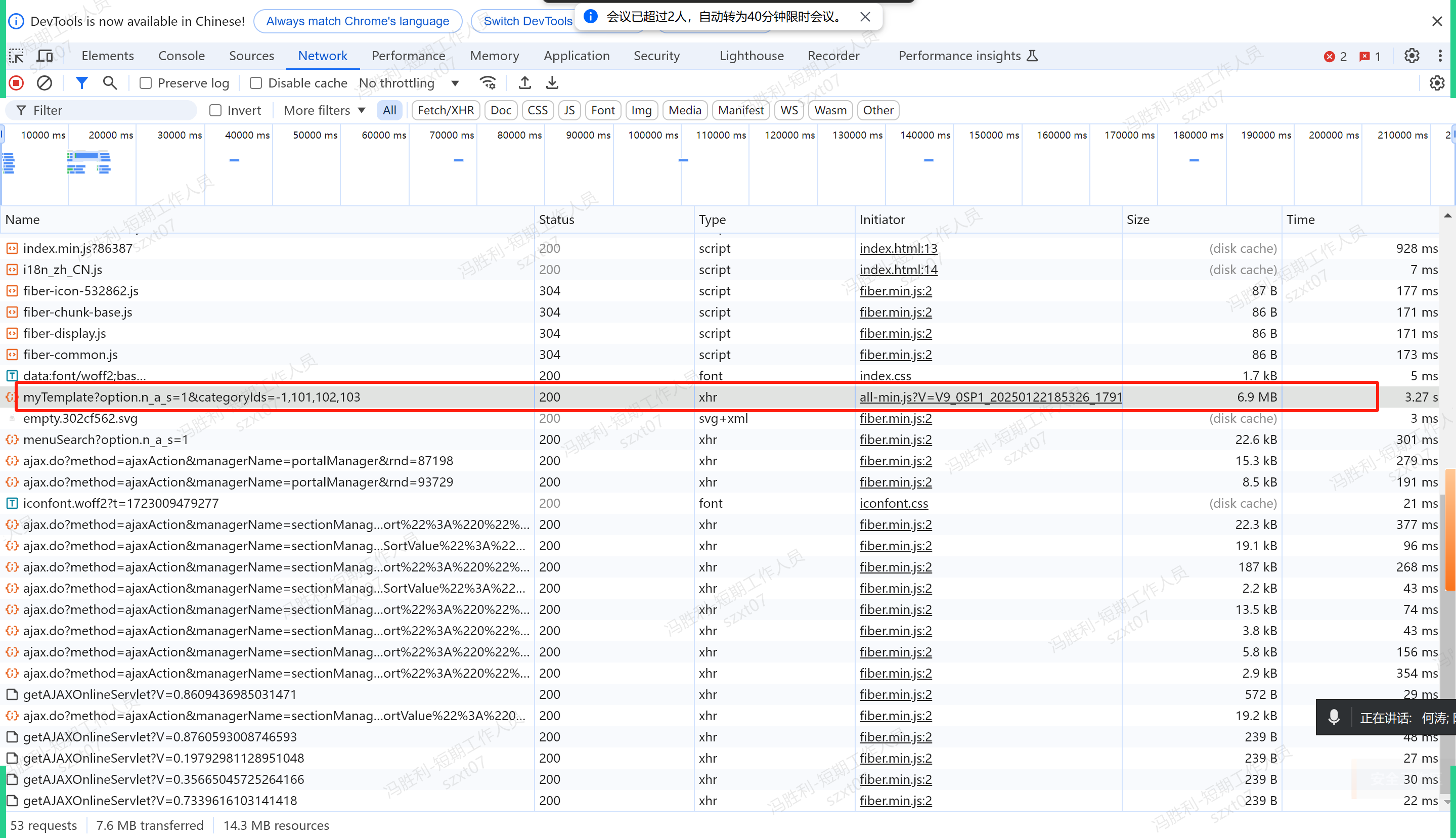
问题原因确认:是因为我的模板数据量过大,卡在 JMeter 压测工具下载数据场景。
对比正常业务系统,我的模板数量仅仅 100KB 左右,而当前环境数量动辄 7M 以上,经过分析,发现此问题是在特殊数据场景下的程序 BUG,通过 BUG 修复再压测就 OK 了。
关联单号:JSFW-2025-01802

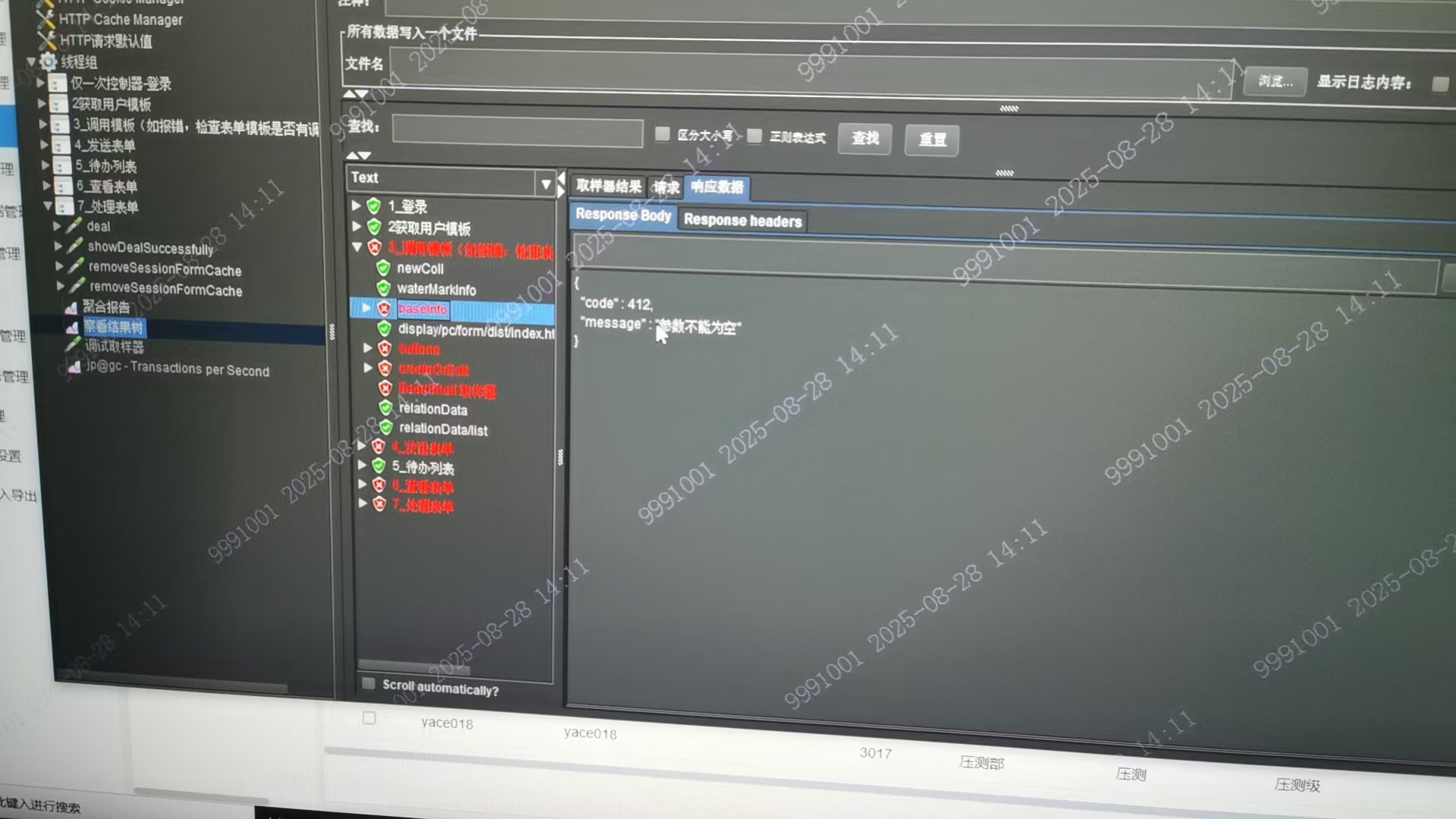
# 2-8 无调用模板权限 请联系公文管理员
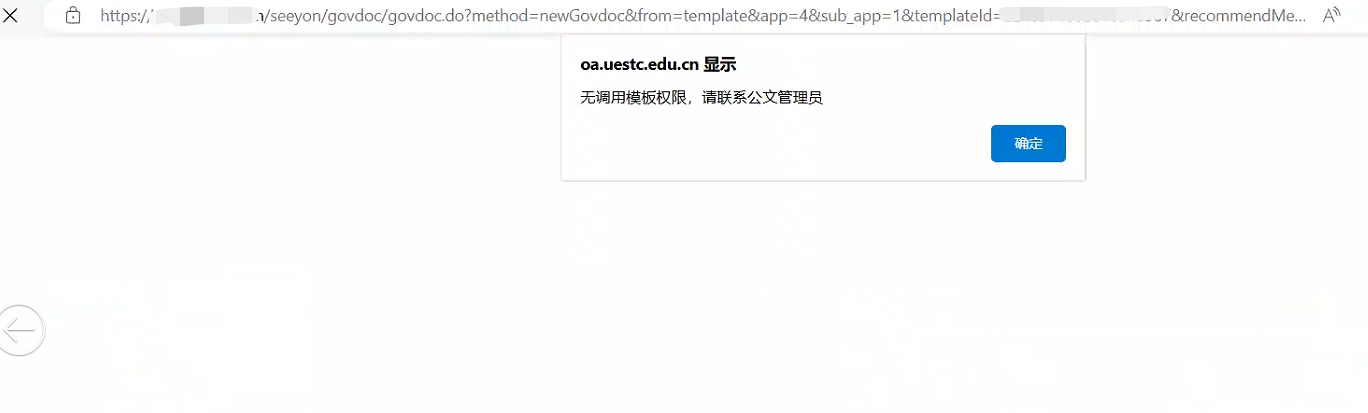
1、进入公文应用功能设置页面,修改 发文 的拟文节点权限
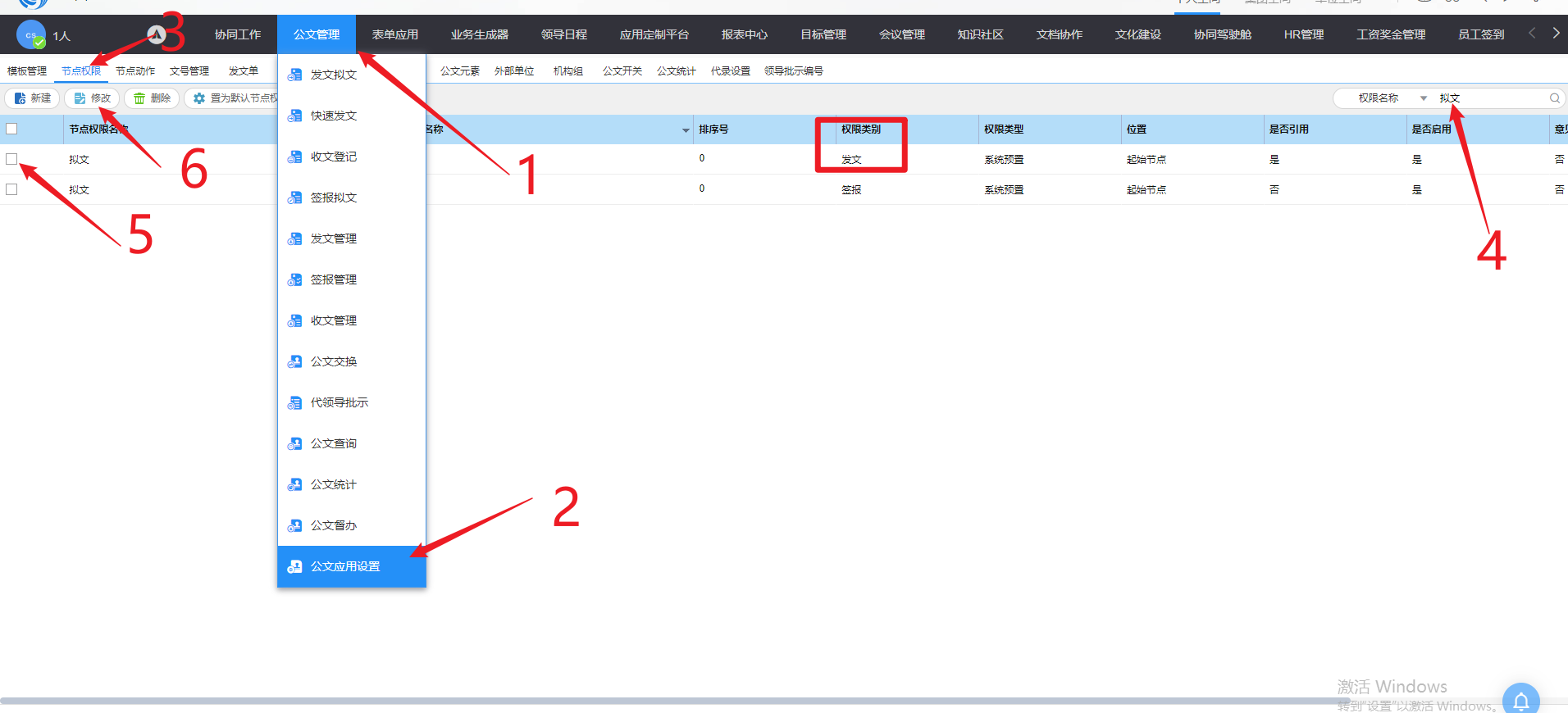
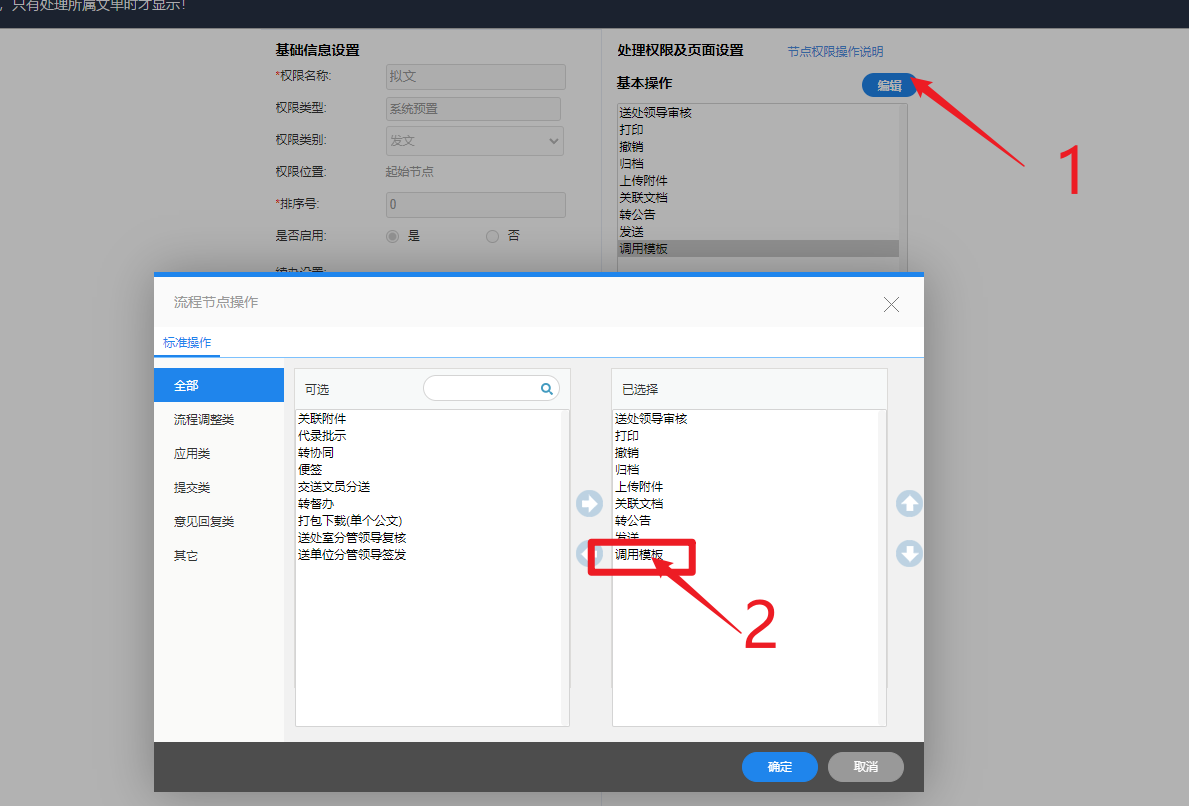
2、编辑页面添加 调用模板 的动作
# 3 其他常见问题
# 3-1 java.net.SocketException: Connection reset
jmeter 压测时出现 java.net.ConnectException: Connection timed out: connect 错误通常是由于目标服务器无法响应请求或网络连接问题导致的。
Ping ip -t,看是否有丢包。如果有,证明网络有问题,找客户网管检查。
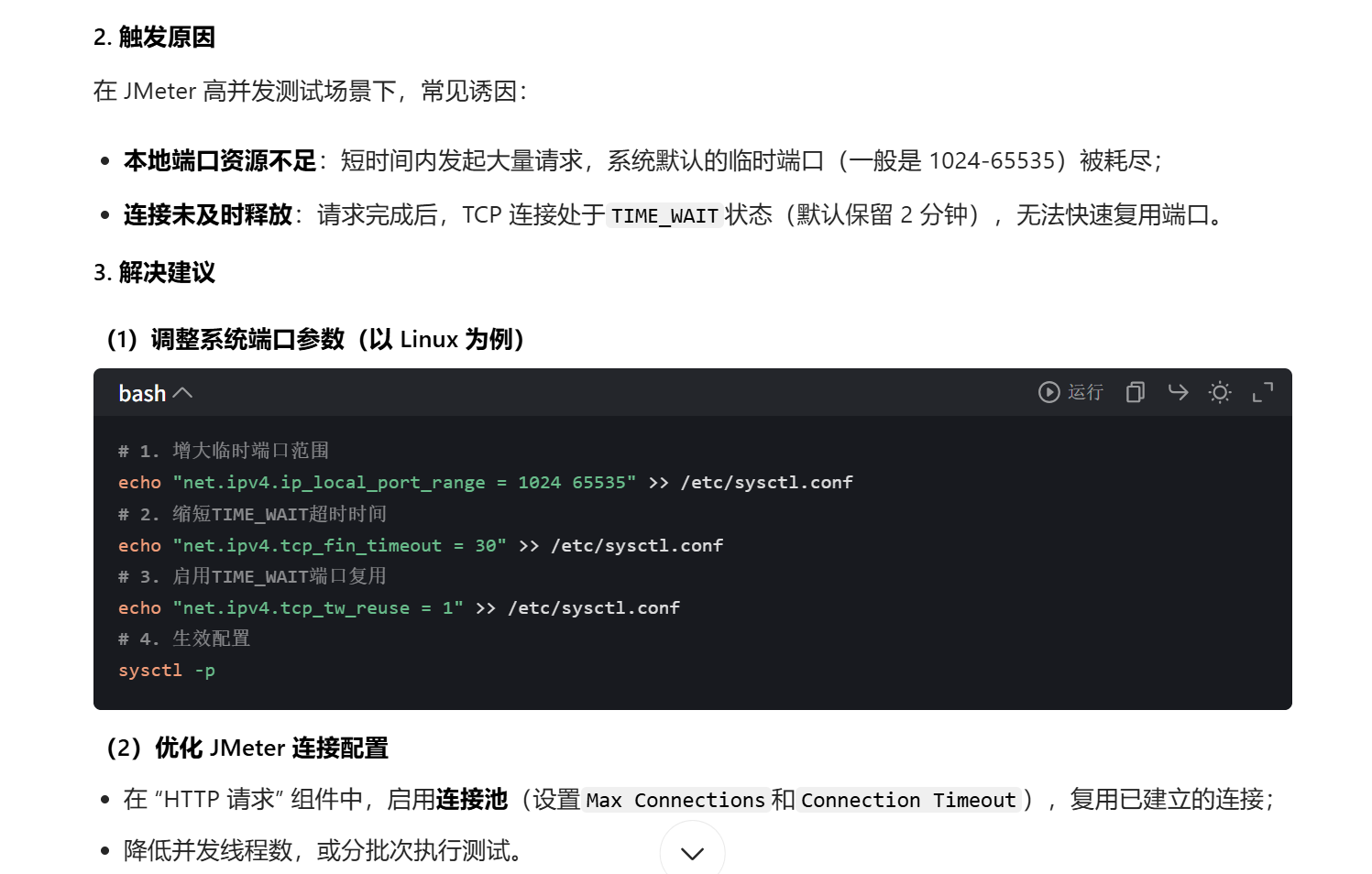
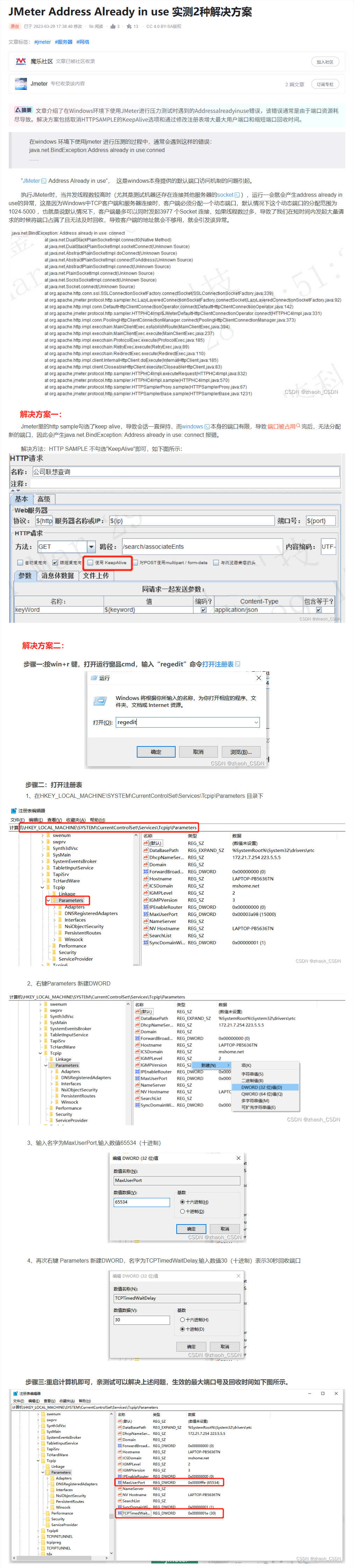
# 3-2 Address already in use
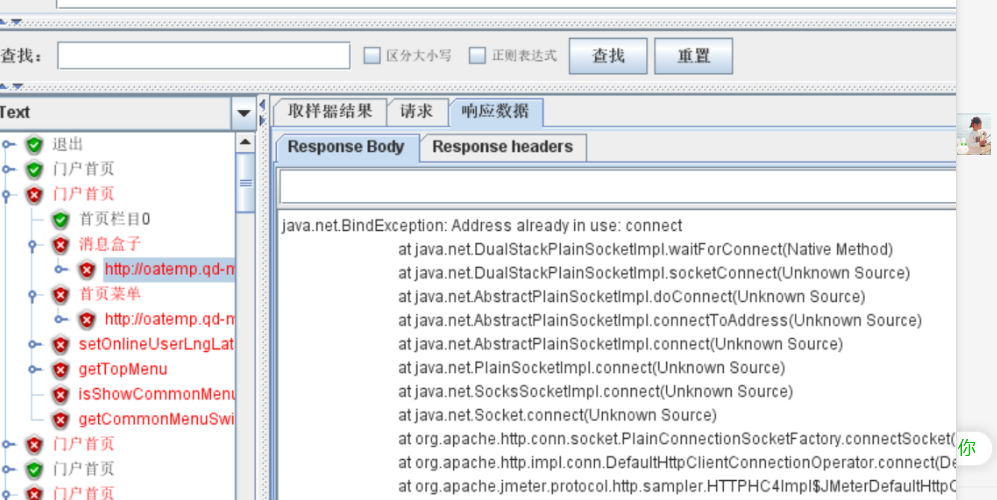
JMeter Address Already in use 实测 2 种解决方案-CSDN 博客 (opens new window)
根据网页上方案 2 进行修改
# 3-3 http 改成 https 后,访问总会访问 http 导致报错
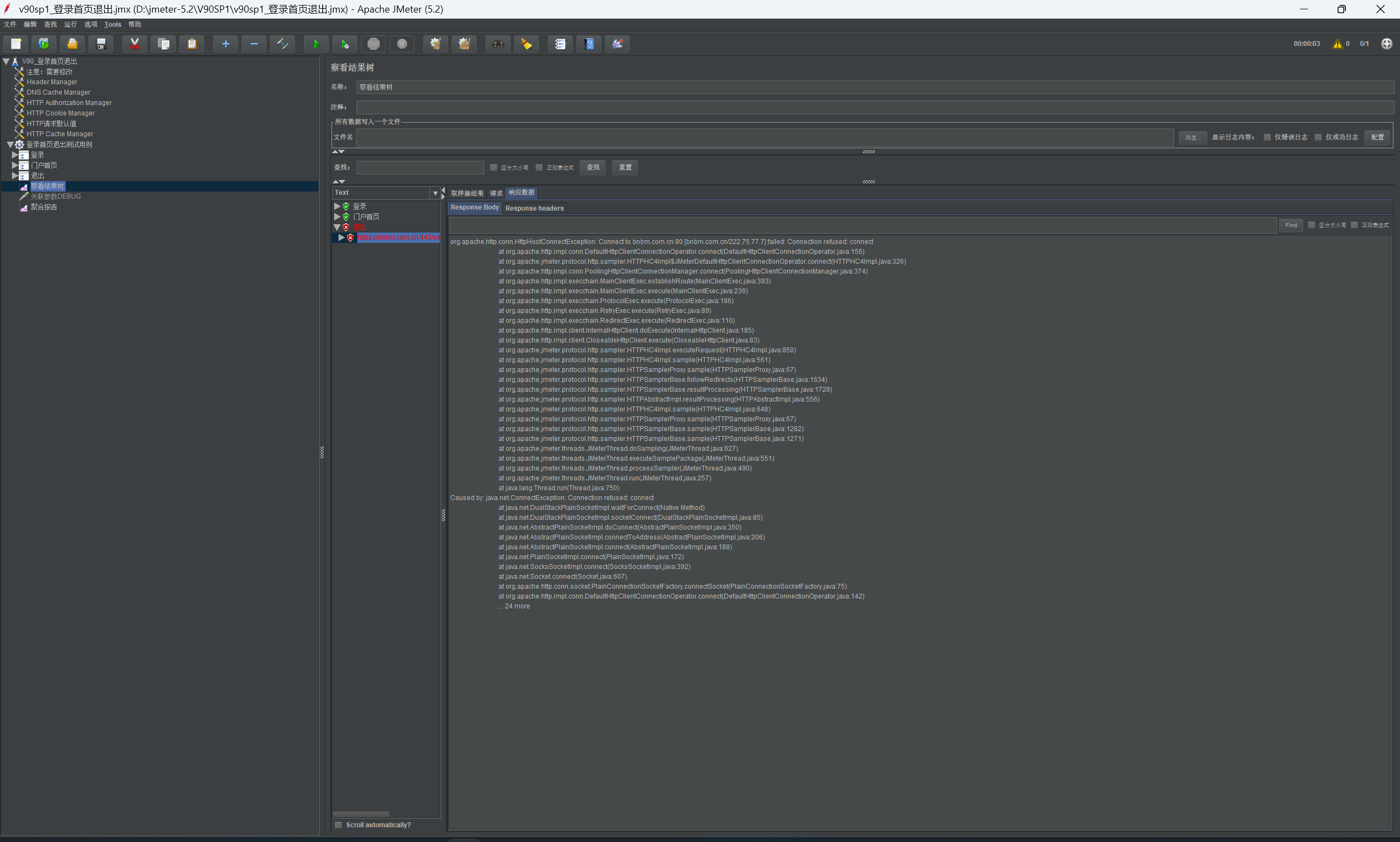
请求设置 https,执行时跑了 http 和 https 两次
请求设置 post,执行时跑了 post 和 get 两次
解决方式:
取消勾选"跟随重定向"
响应断言请求头,且忽略状态
# 3-4 socket closed
java.net.SocketException: socket closed
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
at java.net.SocketInputStream.read(SocketInputStream.java:171)
at java.net.SocketInputStream.read(SocketInputStream.java:141)
at org.apache.jmeter.util.SlowInputStream.read(SlowInputStream.java:53)
at org.apache.http.impl.io.SessionInputBufferImpl.streamRead(SessionInputBufferImpl.java:137)
at org.apache.http.impl.io.SessionInputBufferImpl.fillBuffer(SessionInputBufferImpl.java:153)
at org.apache.http.impl.io.SessionInputBufferImpl.read(SessionInputBufferImpl.java:205)
at org.apache.http.impl.io.ChunkedInputStream.read(ChunkedInputStream.java:188)
at org.apache.http.conn.EofSensorInputStream.read(EofSensorInputStream.java:135)
at org.apache.http.conn.EofSensorInputStream.read(EofSensorInputStream.java:148)
at org.apache.jmeter.protocol.http.sampler.HTTPSamplerBase.readResponse(HTTPSamplerBase.java:1906)
at org.apache.jmeter.protocol.http.sampler.HTTPAbstractImpl.readResponse(HTTPAbstractImpl.java:477)
at org.apache.jmeter.protocol.http.sampler.HTTPHC4Impl.sample(HTTPHC4Impl.java:588)
at org.apache.jmeter.protocol.http.sampler.HTTPSamplerProxy.sample(HTTPSamplerProxy.java:67)
at org.apache.jmeter.protocol.http.sampler.HTTPSamplerBase.sample(HTTPSamplerBase.java:1282)
at org.apache.jmeter.protocol.http.sampler.HTTPSamplerBase.sample(HTTPSamplerBase.java:1271)
at org.apache.jmeter.threads.JMeterThread.doSampling(JMeterThread.java:627)
at org.apache.jmeter.threads.JMeterThread.executeSamplePackage(JMeterThread.java:551)
at org.apache.jmeter.threads.JMeterThread.processSampler(JMeterThread.java:490)
at org.apache.jmeter.threads.JMeterThread.run(JMeterThread.java:257)
at java.lang.Thread.run(Thread.java:750)
# 3-5 Address is invalid on local machine, or port is not valid on remote machine
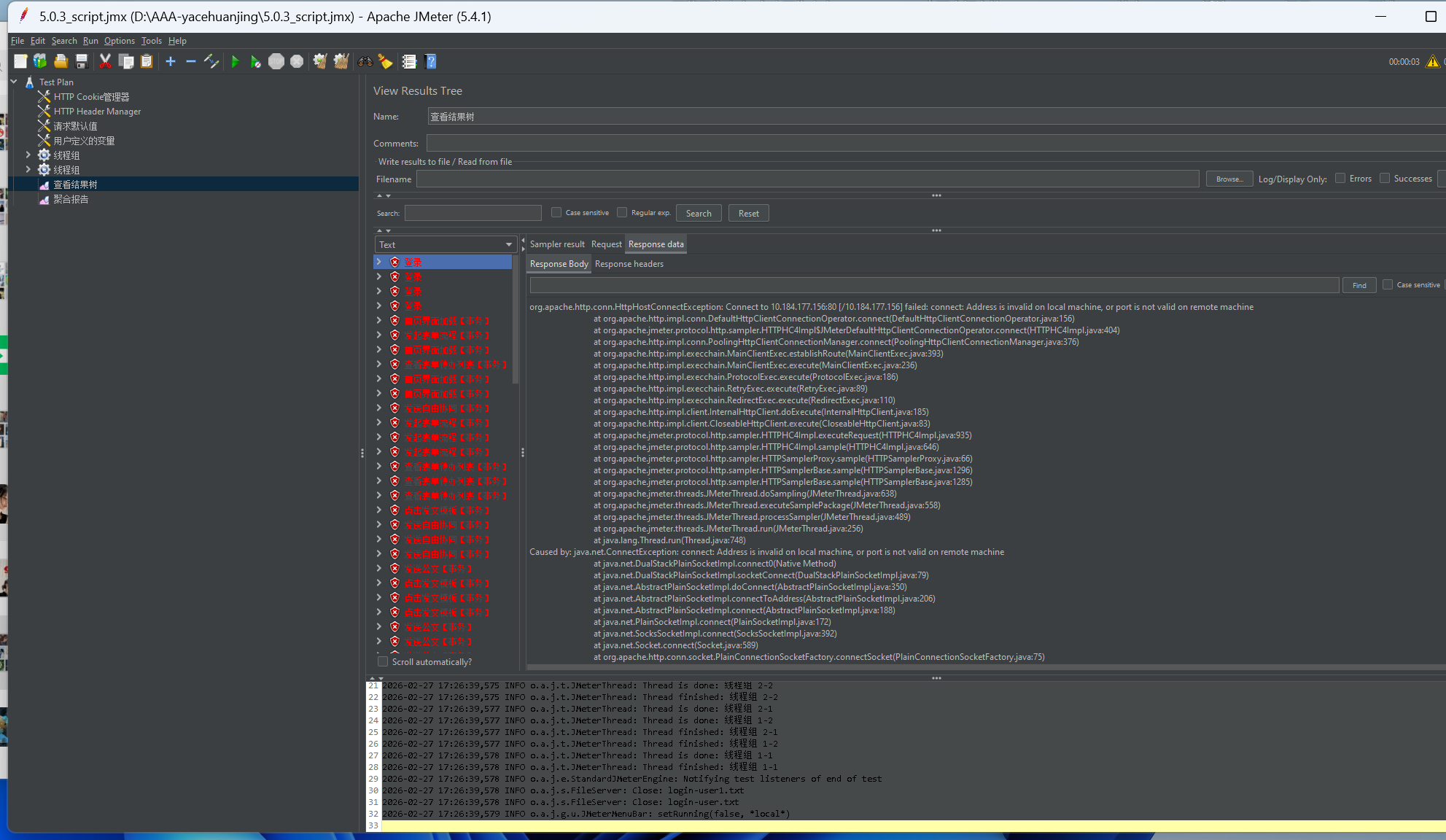
原因: 网络访问到虚拟网卡,导致无法访问服务器地址;
解决方案: 强制使用 ipv4 网络;
找到 JMeter 安装目录下的 bin 文件夹,打开 system.properties 文件,在文件末尾添加:
java.net.preferIPv4Stack=true
保存文件后,重启 JMeter 即可生效。
# 3-6 100 并发压测稳定,到 200 之后 Cannot open connection
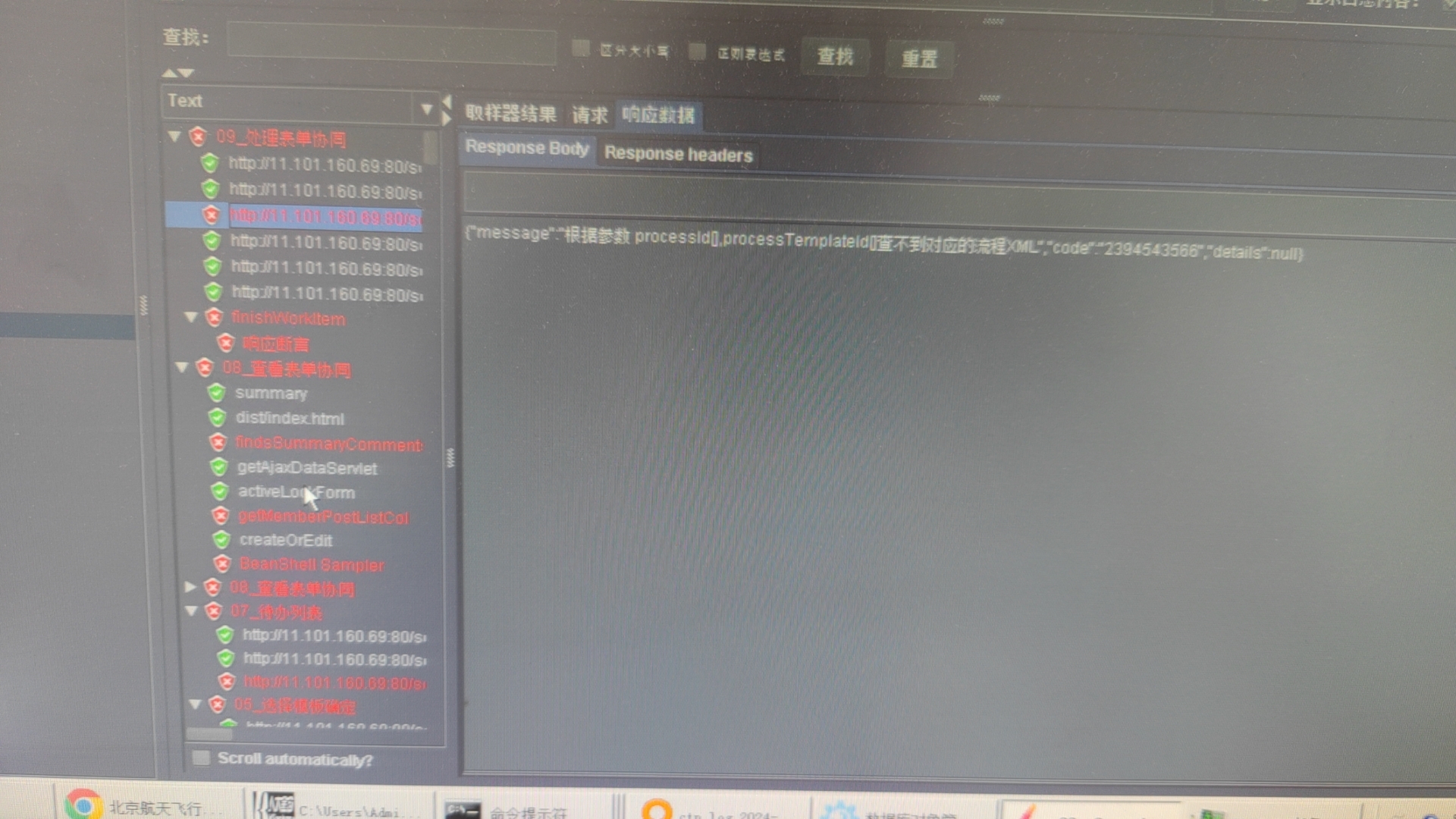
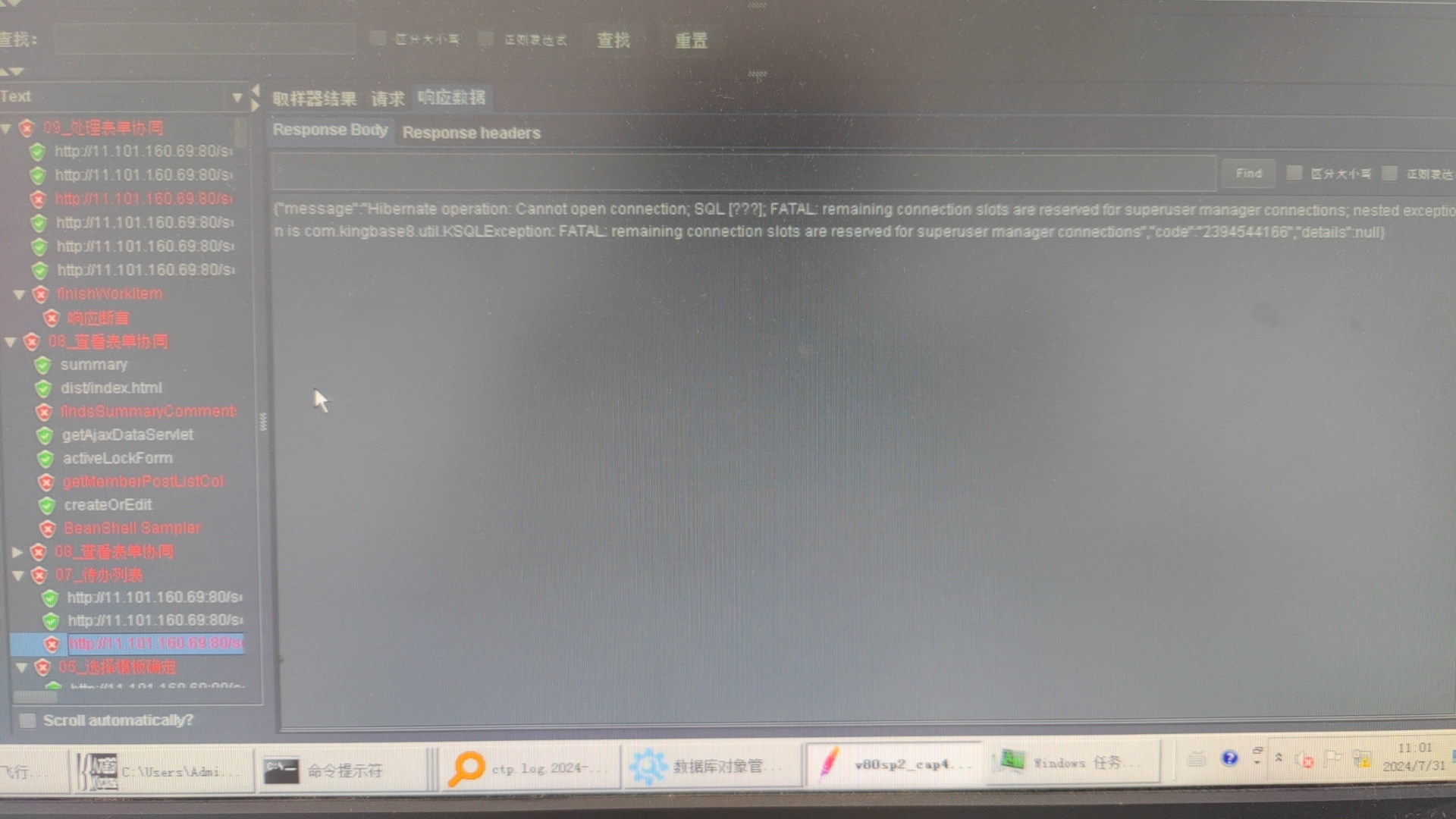
尽量去找最早发生异常的请求,看下请求报什么错,根据日志分析下图所示的错误最可能引起失败:
Hibernate operation: Cannot open connection;
再进一步查看数据库配置:最大连接数只有 100,问题原因初步可以定性是:数据库连接不够,程序获取不到连接导致异常。
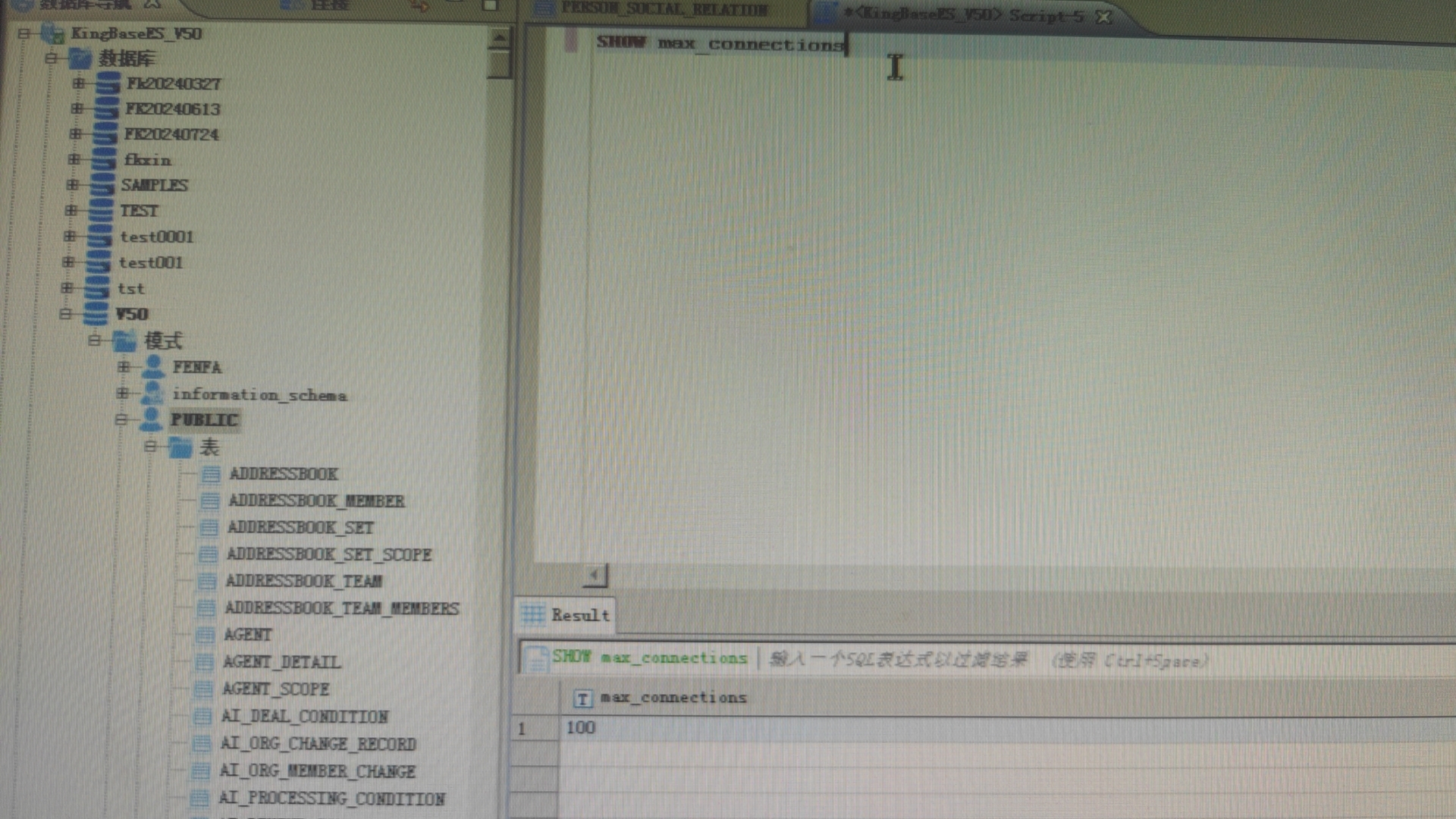
解决方案
需要扩大数据库的最大连接,比如扩大到 500;
需要调整 OA 中间件侧的最大连接数,比如通过 SeeyonConfig 应用配置将最大连接设置为 500;
如果压测数据要求更高,则扩大数据库连接。
# 3-7 Too many open files
由于操作系统(特别是 Linux)对单个进程可打开文件句柄数的限制所致。当大量并发请求压测时,OA 的 Java 进程会同时打开大量网络连接和文件,如果超出默认限制,就会导致"Too many open files"错误,进而影响 OA 服务。
步骤一:调整 OA 应用的中间件配置
如果确认是限制过低(例如 ulimit -n 显示为 1024),需要永久性调高。这需要系统管理员权限操作。
修改系统全局限制:编辑 /etc/sysctl.conf 文件,在末尾添加或修改以下配置,数值可以根据服务器性能适当增大(如 1048576):fs.file-max = 1048576 保存后,执行 sysctl -p 命令使配置生效。
修改用户级(OA 应用启动用户,通常是 root 或 seeyon)的限制:编辑 /etc/security/limits.conf 文件,在末尾添加以下配置(假设 OA 进程以 seeyon 用户启动):
seeyon soft nofile 655360
seeyon hard nofile 655360
* soft nproc 65536
* hard nproc 65536
注意:seeyon 需要替换为实际的用户名。
步骤二:调整 OA 应用的中间件配置
仅仅提高操作系统限制还不够,还需要让 Tomcat 等中间件"感知"到这个更高的限制,并调整其自身的连接池等参数。
在 OA 启动脚本中设置句柄数: 找到并编辑 OA 的启动脚本 startup.sh(通常在 ApacheJetspeed/bin/ 目录下)。在脚本中设置 JVM 参数,通常可以在 JAVA_OPTS 变量后追加:
# 例如,在原有配置基础上增加
export JAVA_OPTS="$JAVA_OPTS -Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 -XX:-UseGCOverheadLimit"
# 或者将 ulimit -n 的调整命令也放在脚本中
ulimit -n 655360
调整 Tomcat 连接器(Connector)参数: 编辑 ApacheJetspeed/conf/server.xml 文件,找到处理 HTTP 请求的 <Connector> 节点,调整以下参数以应对高并发:
<Connector port="80" protocol="HTTP/1.1"
maxThreads="1000" <!-- 最大线程数,根据压测需求调整 -->
minSpareThreads="100" <!-- 最小空闲线程数 -->
acceptCount="1000" <!-- 等待队列长度 -->
connectionTimeout="20000"
maxConnections="10000" <!-- 最大连接数 -->
...
/>
注意:maxThreads 和 maxConnections 的值需要根据压测并发量和服务器硬件性能(尤其是 CPU 核心数)进行合理设置。
步骤三:重启并验证
完成以上所有配置修改后,需要重启 OA 服务才能生效。重启后,重复步骤一中的命令,确认新的句柄数限制已生效。
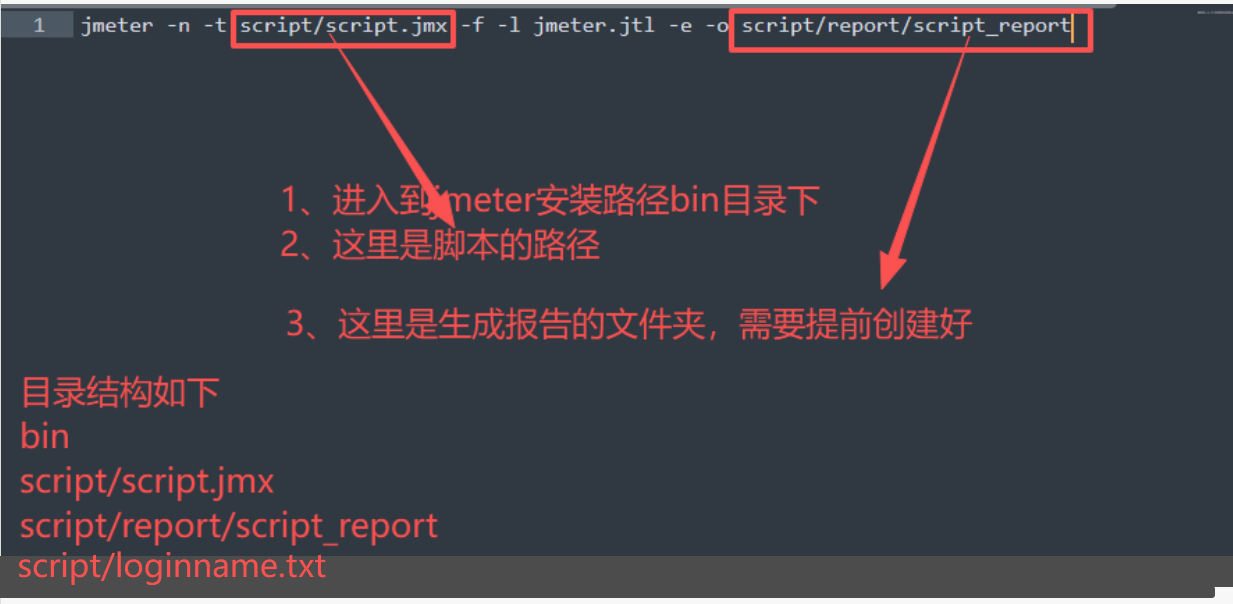
# 4 命令执行
./jmeter -n -t script/script.jmx -f -l jmeter.jtl -e -o script/report/script_report_600 并发_1