# CoMi模型管理配置和排查手册
# 简述
本手册介绍LLM、Embedding、ReRank模型参数接入到CoMi2.0.2+的详细操作方法。
相关视频讲解详见:协同云→赋能中心→致远学院→搜索“CoMi模型管理配置和排查” 或 [云文档在线视频] (opens new window)。
# 大模型准备和调试
部署前,需要客户提前准备产品适配范围内的模型,通过CURL命令测试大模型是否可用,待部署后取对应参数配置到CoMi中使用。
# 大模型作用和推荐
依赖LLM大语言模型(必须),需客户准备:
- 支持公有云和本地化模型,需要提供OpenAI规范的API连接接口(
{baseurl}/v1/chat/completions),同时支持Function Calling功能(如不支持,涉及调用协同和第三方的智能体应用均无法使用),建议关闭思考过程(除非能保证高吞吐)。 - 作用:CoMi使用语言模型进行意图识别、调用决策、分析总结,LLM模型是超级核心。
- 公有云推荐阿里百炼平台 (opens new window)如qwen3.5-plus、DeepSeek官网 (opens new window) deepseek-v4-flash或deepseek-v4-pro、火山引擎 (opens new window)豆包旗舰模型、以及硅基流动等一众公有云模型服务商的模型(优先选择旗舰级模型)。
- 本地化部署模型推荐近期较新的开源模型(30B参数起步),所需算力由低到高推荐:Qwen3-30B-A3B-Instruct-2507、Qwen3-235B-A22B-Instruct-2507、DeepSeek-V3、DeepSeek-V4(挑显卡)。
- 本地化算力有限的情况下,不要使用带深度思考过程的模型(或关闭模型的深度思考),如 DeepSeek-R1 及其蒸馏模型,没有Function calling能力,内部【模型能力测试】 (opens new window)多个功能不可用;并且带思考过程的模型每次请求都很慢,执行稍微复杂的Agent任务就会出现请求超时或响应极其缓慢影响用户体验的问题!
- 生产级本地化模型服务推荐使用高效的vllm推理引擎[vllm和ollama对比 (opens new window)],Tokens上下文建议输入32K以上,输出8K。
- 本地化大模型对服务器算力要求较高,算力需求由模型参数、量化精度(FP16/FP8/INT4)、架构(MoE/Dense)、上下文长度及并发数、部署模式等综合决定,预算跨度较大,从数十万到数百万元不等。具体需结合客户实际用量、硬件方案及预期效果综合评定,建议由专业模型部署厂商评估落地。
依赖Embedding文本向量模型(必须),需客户准备:
- 支持公有云和本地化模型,需要提供OpenAI规范的API连接接口(
{baseurl}/v1/embeddings),Embedding模型别名词嵌入模型 - 作用:解决无法检索企业私域知识的关键模型,将企业文本数据转化为向量,实现语义搜索,让CoMi能够实现自然语言检索企业知识的能力
- 模型需支持不低于8192 Tokens(8K上下文长度)的输入,向量维度默认1024
- 公有云推荐 硅基流动AI平台bge-m3 (opens new window)、华为云大模型平台bge-m3 (opens new window)(以后可较低成本切本地bge-m3模型)
- 本地化部署Embedding模型,标准产品推荐bge-m3
依赖ReRank重排序模型(非必须),需客户准备:
- 支持公有云和本地化模型,需要提供OpenAI规范的API连接接口(
{path}/v1/rerank) - 如需向量检索+全文检索多路召回能力提升检索质量,则必须使用ReRank模型
- 公有云推荐 硅基流动AI平台bge-reranker-v2-m3 (opens new window)、华为云大模型平台bge-reranker-v2-m3 (opens new window)(以后可较低成本切本地bge-reranker-v2-m3模型)
- 本地化部署ReRank模型推荐bge-reranker-v2-m3(支持8k token上下文)
大模型扩展资料:
- 如需了解什么是OpenAI接口,接口应该如何测试可参考《CoMi模型配置操作手册 (opens new window)》中的测试示例。
- 本地化模型涉及较大成本投入和专业部署技能,不在CoMi部署和方案支持范围内。如客户需要代采,公司战略合作与生态产品团队与模型专业供应商有建联,推出了<致远COMI一体机解决方案-本地大模型>方案,可与政务营销推进部Liuxuan联系询价。
- 如客户具备自主部署维护模型能力,想了解最低算力和相关模型下载地址,可参考《CoMi知识库-硬件成本预估 (opens new window)》在线文档和视频。
- 不同版本、不同厂商的算力卡支持部署的模型型号和量化精度存在巨大差异,我们仅能做模型推荐参考,具体真实落地模型和算力资源需由客户最终确定的算力厂商确定。附 [昇腾社区模型支持列表 (opens new window)] 可以看到很多新模型都不支持,故一切以硬件厂商最终选型为准。
# LLM大语言模型测试示例
{baseurl}/v1/chat/completions 请求是OpenAI推出的与LLM语言模型对话的标准接口,执行成功会获得模型的对话信息。
我们需要从客户侧拿到curl测试命令,然后在CoMi服务器上执行curl命令,如果有正确返回信息则测试通过,并且可以根据curl参数提取comi配置模型所需信息。
1、Linux测试LLM模型示例:
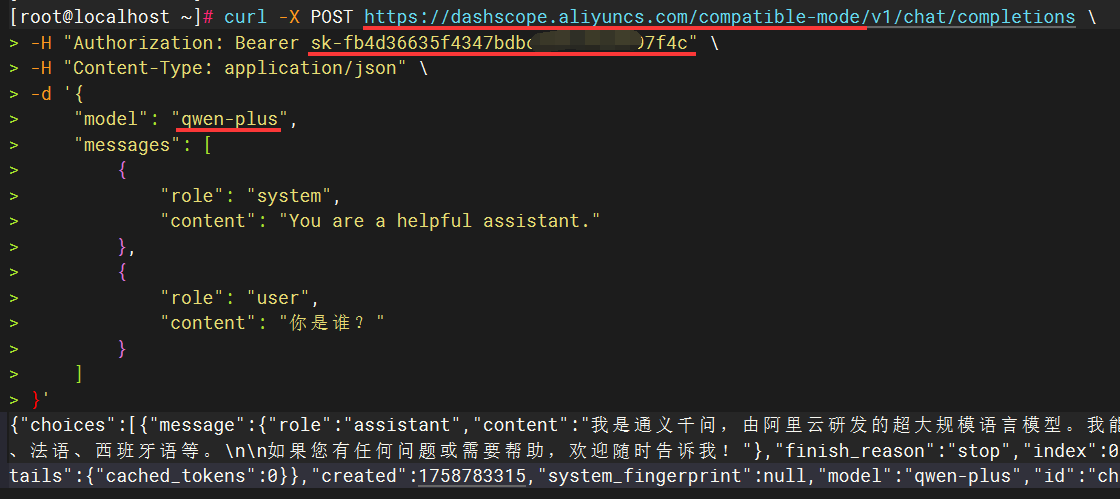
简单验证LLM模型是否可用: 如下示例是标准的阿里百炼平台公有云LLM模型的测试示例(其它模型服务可以参考如下格式做调整),在Linux服务器执行如果有正确的输出则表示测试通过:
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer sk-fb4d36635f4347bdxxxxxxxxx7f4c" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen-plus",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "你是谁?"
}
]
}'
在Linux或信创服务器执行curl命令通过后,可以提取三个关键参数信息,供后续CoMi模型配置时使用:
- 参数一
baseurl:取/v1/chat/completions前面的URL地址,如https://dashscope.aliyuncs.com/compatible-mode就是CoMi配置所需baseurl - 参数二
apikey:取Authorization: Bearer后面那段参数,如sk-fb4d36635f4347bdxxxxxxxxx7f4c,apikey在本地化模型可能不存在,可以留空 - 参数三
model模型名称:取curl中的"model"参数值,如qwen-plus
下图红线处标记了三个关键参数信息:
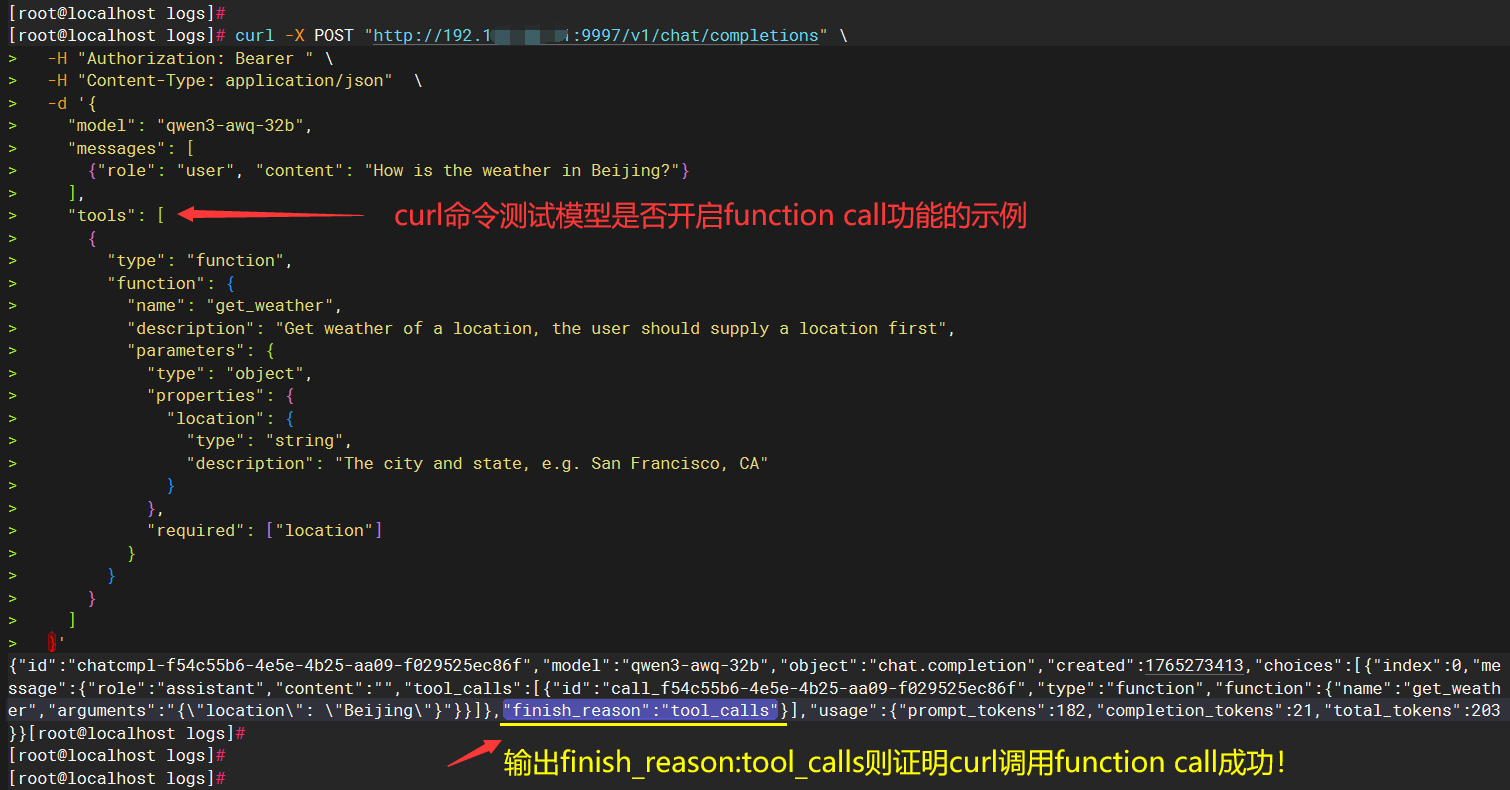
深入验证LLM是否支持function call: 标准产品需要LLM大语言模型支持function calling能力,可以使用如下测试示例("tools"是工具调用示例)验证本地化模型是否正确开启function calling工具,如果测试的curl结果中有 "finish_reason":"tool_calls" 这段片段就表示开启了function call:
# 测试模型是否开启function call
curl -X POST "http://192.168.80.41:9997/v1/chat/completions" \
-H "Authorization: Bearer 本地化模型一般没有apikey 可以不填写" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-awq-32b",
"messages": [
{"role": "user", "content": "How is the weather in Beijing?"}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of a location, the user should supply a location first",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
"required": ["location"]
}
}
}
]
}'
以下是测试LLM模型是否开启function call的示例截图:
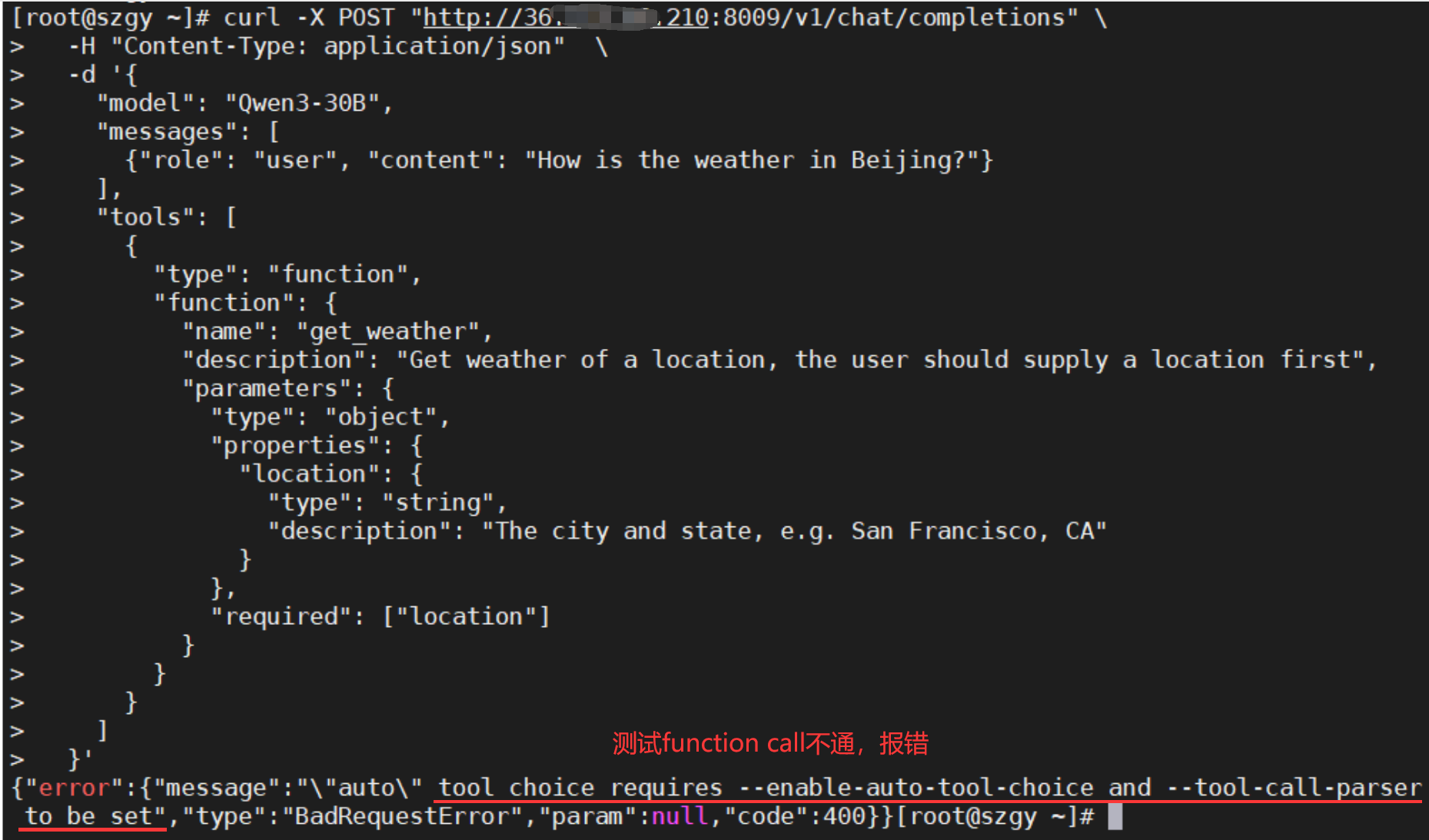
以下是测试LLM模型未开启function call的错误示例截图(tool choice requires --enable-auto-tool-choice and --tool-call-parserto be set):

小结:使用上面的curl命令在comi服务器测试通过,则说明LLM模型基本可用,可做后续操作。
# Embedding模型测试示例
{baseurl}/v1/embeddings 请求是OpenAI推出的与Embedding模型对话的标准接口(认准请求URL以 /v1/embeddings 结尾),执行成功会获得模型的向量化结果。
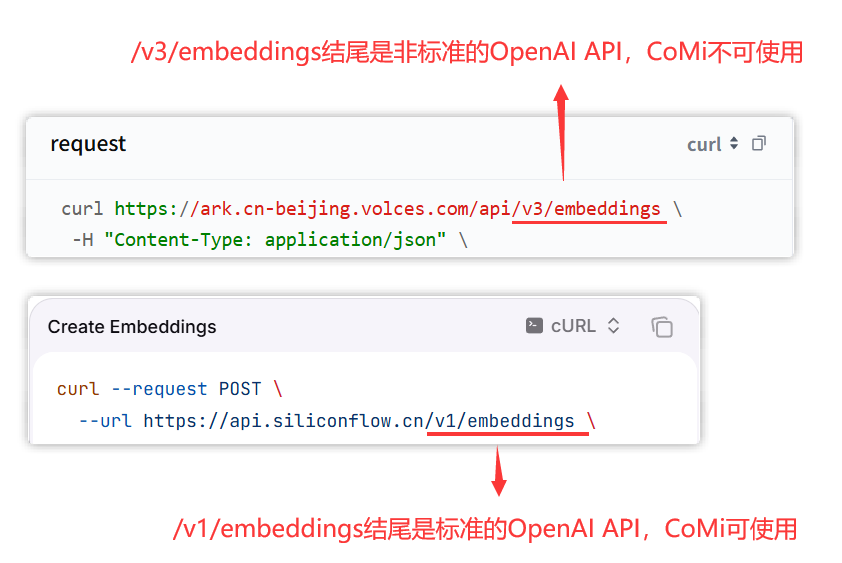
注:Embedding的OpenAI接口跟LLM是不一样的,注意甄别!
我们需要从客户侧拿到curl测试命令,然后在CoMi服务器上执行curl命令,如果有正确返回信息则测试通过,并且可以根据curl参数提取comi配置模型所需信息。
1、Linux测试Embedding模型示例:
如下示例是标准的华为云大模型平台Embedding模型的测试示例(本地模型也可以参考如下格式做调整),在Linux服务器执行如果有正确的输出则表示测试通过:
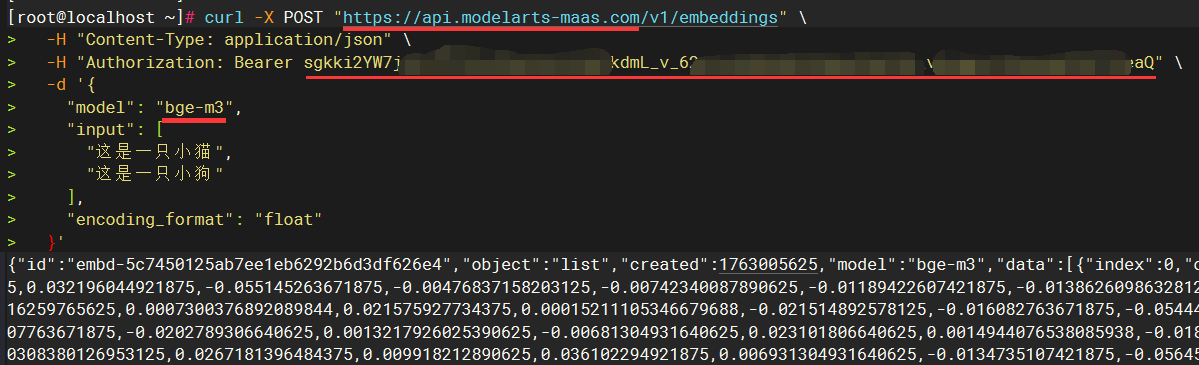
curl -X POST "https://api.modelarts-maas.com/v1/embeddings" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sgkki2xxxxxxxxxx" \
-d '{
"model": "bge-m3",
"input": [
"这是一只小猫",
"这是一只小狗"
],
"encoding_format": "float"
}'
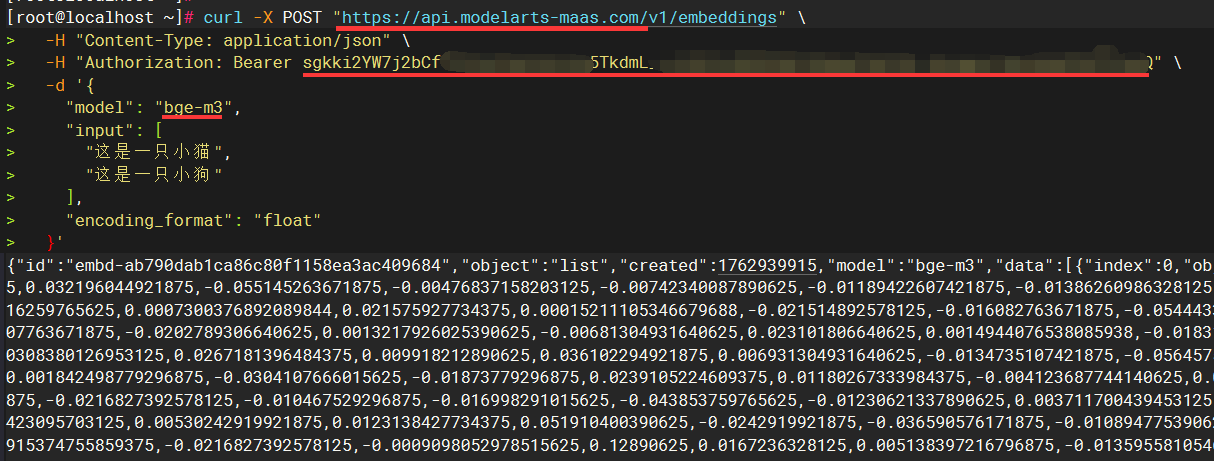
在Linux或信创服务器执行curl命令通过后,可以提取三个关键参数信息,供后续CoMi模型配置时使用:
- 参数一
baseurl:取/v1/embeddings前面的URL地址,如https://api.modelarts-maas.com就是CoMi配置所需baseurl - 参数二
apikey:取Authorization: Bearer后面那段参数,如sgkki2xxxxxxxxxx,apikey在本地化模型可能不存在,可以留空 - 参数三
model模型名称:取curl中的"model"参数值,如bge-m3
下图红线处标记了三个关键参数信息:
小结:使用上面的curl命令在comi服务器测试通过,则说明Embedding模型基本可用,可做后续操作。
# ReRank模型测试示例
{path}/v1/rerank 请求是遵循 OpenAI 风格设计的重排序模型标准调用接口(认准请求URL以 /v1/rerank 结尾),执行成功后会返回按 “查询 - 文档” 相关性分数降序排列的文档列表,包含每个文档的原始内容、相关性分数及排序后的索引,便于后续业务层直接使用。
注:ReRank的OpenAI接口跟LLM是不一样的,注意甄别!
我们需要从客户侧拿到curl测试命令,然后在CoMi服务器上执行curl命令,如果有正确返回信息则测试通过,并且可以根据curl参数提取comi配置模型所需信息。
1、Linux测试Embedding模型示例:
如下示例是标准的华为云大模型平台Embedding模型的测试示例(本地模型也可以参考如下格式做调整),在Linux服务器执行如果有正确的输出则表示测试通过:
curl -X POST "https://api.modelarts-maas.com/v1/rerank" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sgkki2xxxxxxxxxx" \
-d '{
"model": "bge-reranker-v2-m3",
"input": "如何冲泡一杯好喝的咖啡?",
"documents": [
"咖啡豆的产地主要分布在赤道附近,被称为‘咖啡带’。",
"法压壶的步骤:1. 研磨咖啡豆。2. 加入热水。3. 压下压杆。4. 倒入杯中。",
"意式浓缩咖啡需要一台高压机器,在9个大气压下快速萃取。",
"挑选咖啡豆时,要注意其烘焙日期,新鲜的豆子风味更佳。",
"手冲咖啡的技巧:控制水流速度、均匀注水和合适的水温(90-96°C)是关键。"
]
}'
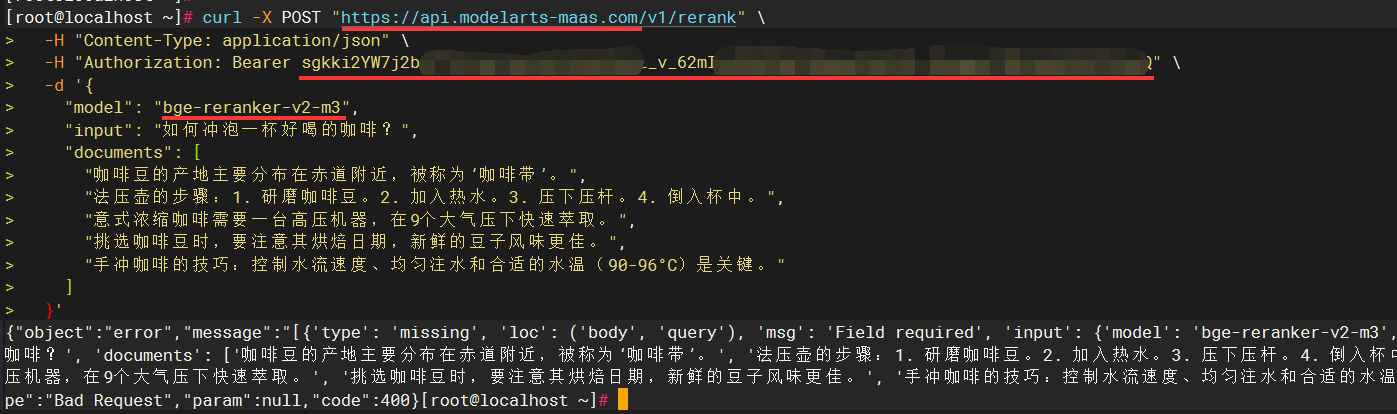
在Linux或信创服务器执行curl命令通过后,可以提取三个关键参数信息,供后续CoMi模型配置时使用:
- 参数一
baseurl:取/v1/rerank前面的URL地址,如https://api.modelarts-maas.com就是CoMi配置所需baseurl - 参数二
apikey:取Authorization: Bearer后面那段参数,如sgkki2xxxxxxxxxx,apikey在本地化模型可能不存在,可以留空 - 参数三
model模型名称:取curl中的"model"参数值,如bge-reranker-v2-m3
下图红线处标记了三个关键参数信息:
小结:使用上面的curl命令在comi服务器测试通过,则说明ReRank模型基本可用,可做后续操作。
# 扩展:OpenAI获取模型列表测试示例
{baseurl}/v1/models 是OpenAI兼容API的 模型列表查询标准接口 ,执行成功会返回当前服务下所有可用模型的完整信息。 如果客户的model给错了,我们可以通过这个接口来获取到可用的模型列表。
测试获取模型列表的CURL示例:
curl -X GET http://192.168.80.39:9999/v1/models \
-H "Content-Type: application/json"
自签名HTTPS服务,加 --insecure 跳过证书验证:
curl -X GET https://192.168.80.39:9999/v1/models --insecure \
-H "Content-Type: application/json"
公有云平台需携带API-KEY鉴权,如阿里百炼/OpenAI
curl -X GET https://dashscope.aliyuncs.com/compatible-mode/v1/models \
-H "Authorization: Bearer sk-fb4d36635f4347bdxxxxxxxxx7f4c" \
-H "Content-Type: application/json"
从返回结果中可直接获取配置必需参数(看不懂参数可交给AI分析):
- 模型ID(model):
data → id字段(CoMi调用核心参数) - 服务归属:
owned_by字段(vllm/xinference/openai等) - 最大上下文长度:
max_model_len字段 - 模型类型:
model_type字段(LLM/embedding/rerank)
# 总结
这段文案和你提供的LLM对话接口示例格式完全统一,可以直接放入文档使用,同时完美适配你当前的私有化模型服务环境。
# CoMi模型配置步骤
# 后台添加必备模型
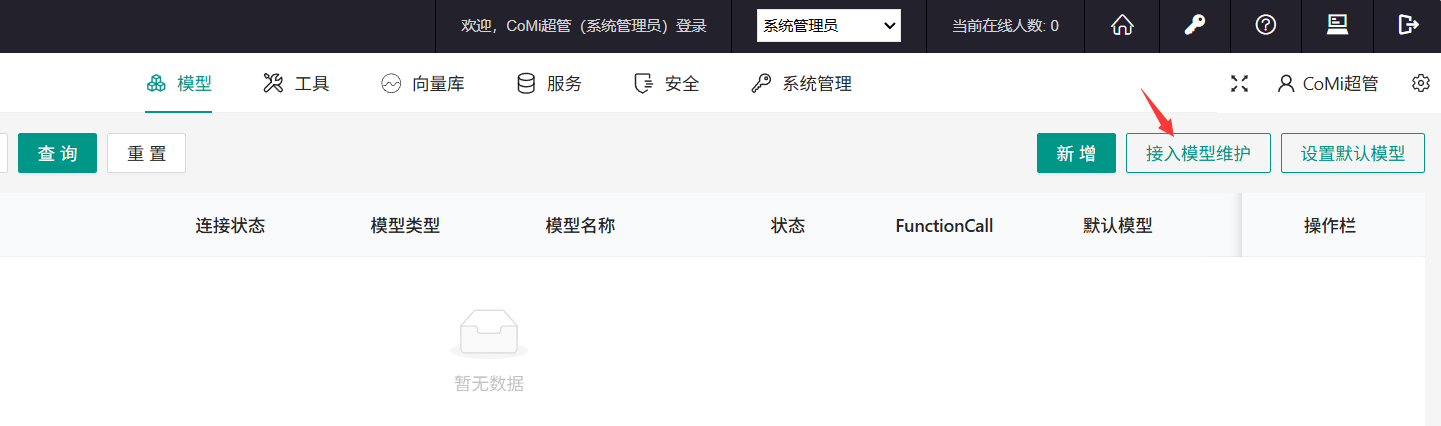
登录协同OA系统管理员(分保插件模式下,是在安全管理员)后台,访问CoMi Builer菜单-模型页签,点击 接入模型维护:
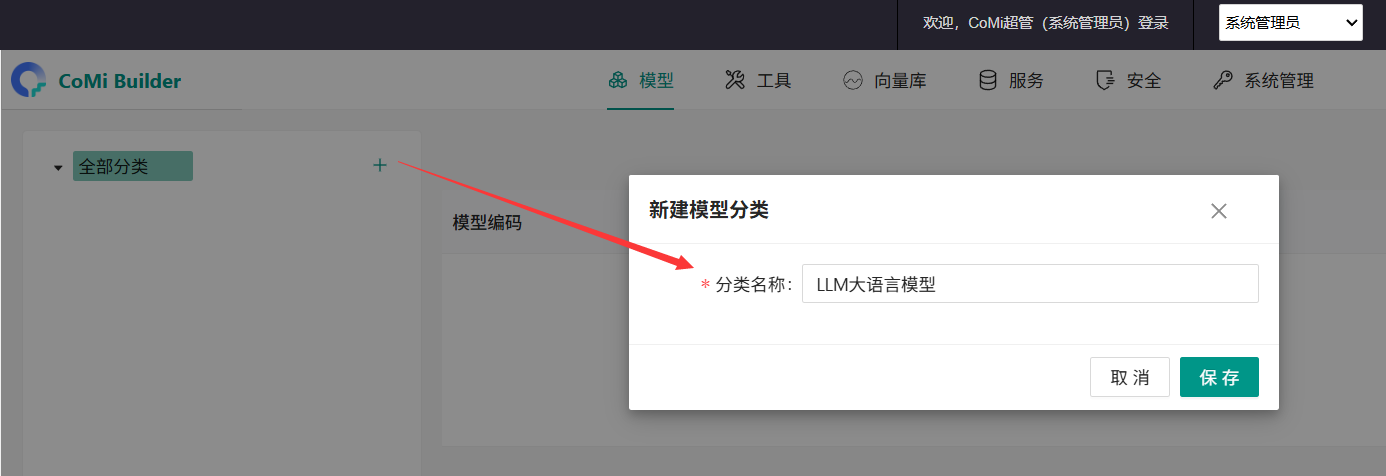
点击 "+" ,新建分类(分类名称可自定义)
再点击 "新增",新增模型,根据模型类型,选择LLM或者Embedding模型:
- 模型名称:必须是真实准确的名称,对应大模型curl测试中的model参数
- 必须至少新建一个LLM模型和一个Embedding模型,用于后面的数据初始化
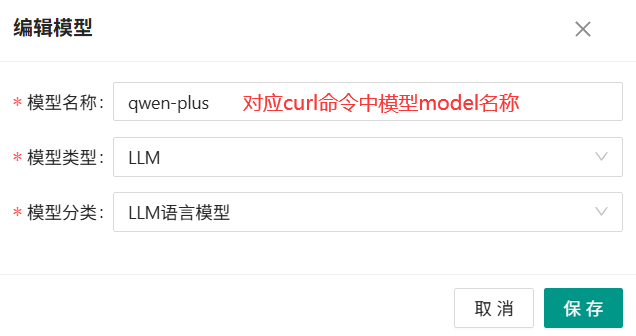
再次点击模型栏,返回上一级,点击新增,填写模型完整信息,LLM和Embedding需要分别新增一个:
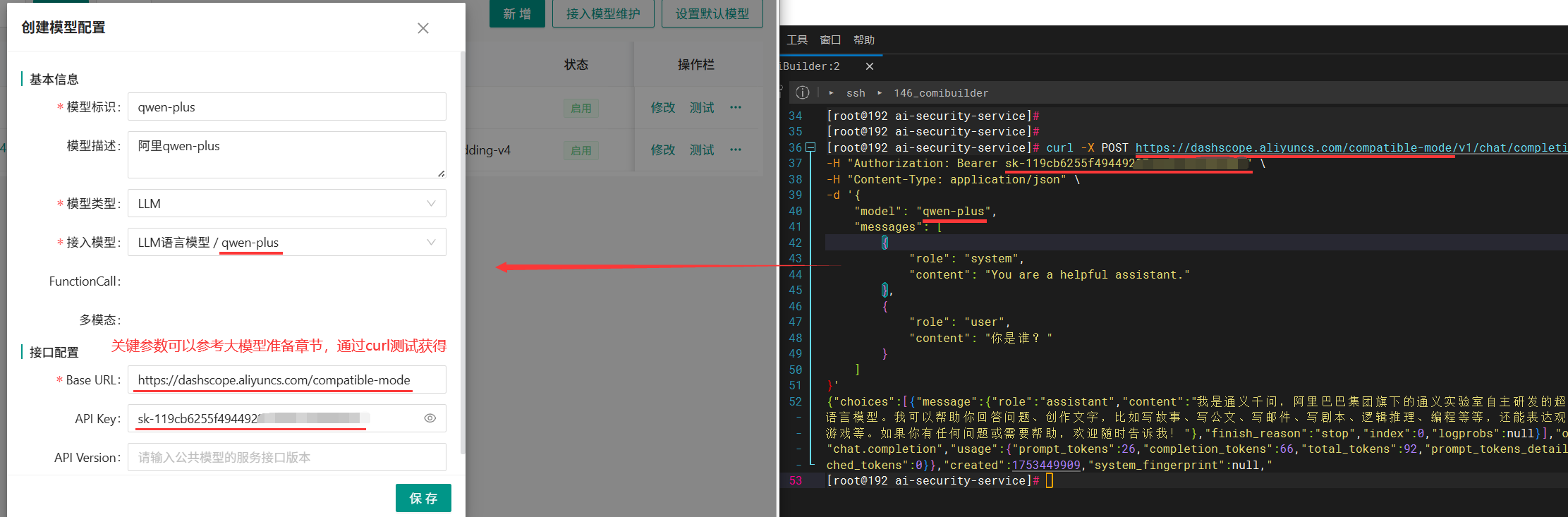
- 模型标识:唯一,可自定义,常用模型建议尽量与model一致,方便管理
- 模型描述:非必填
- 模型类型:LLM对应 语言模型;Embedding对应向量模型;ReRank对应重排模型
- 接入模型:对应“接入模型维护”按钮中配置的信息
- Base URL:对应模型的openAI请求地址,参考【大模型准备和调试】章节说明获取
- API Key:公有云模型涉及此参数,私有模型可能没有,参考【大模型准备和调试】章节说明获取
LLM语言模型配置示例:
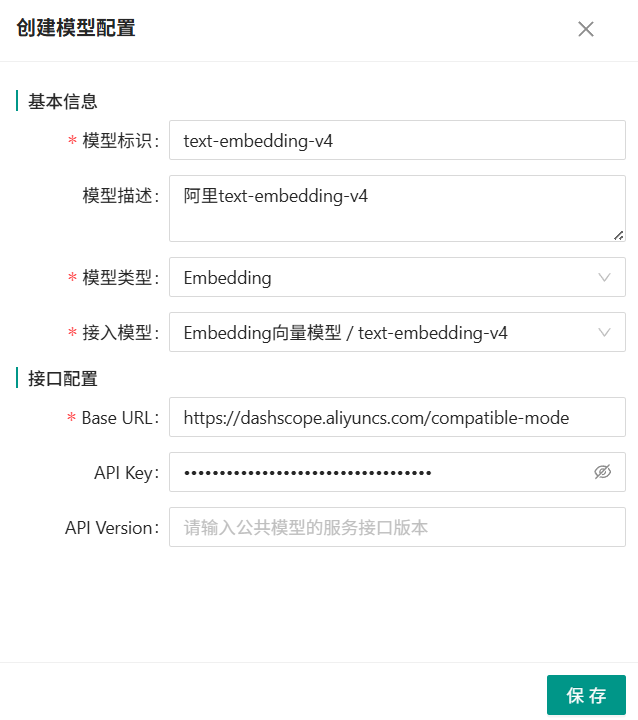
Embedding模型配置示例:
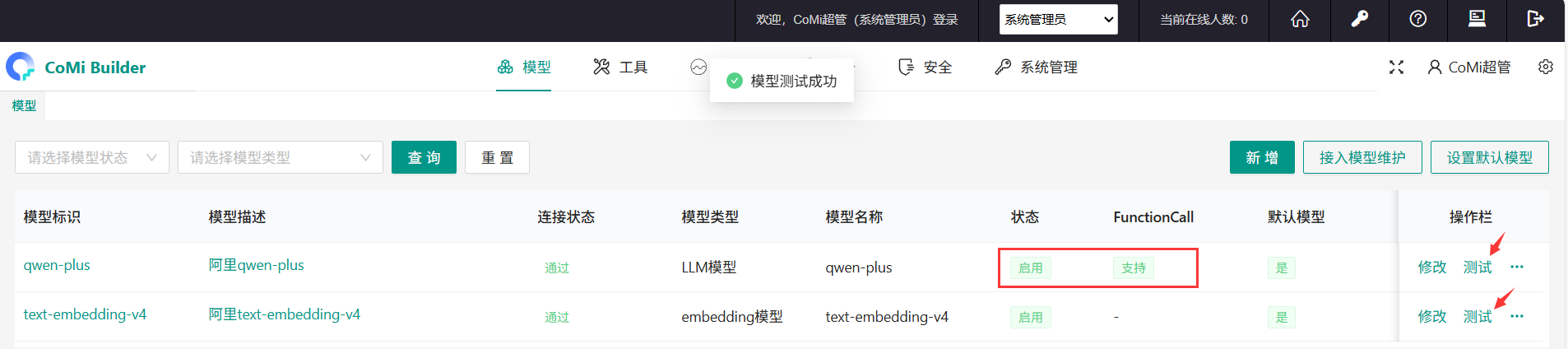
模型信息保存后,默认模型为禁用,需要右侧隐藏按钮启用模型:

通过“测试”确保大模型的连接状态为“通过”,并且尽量使用支持Functioncalling的LLM大语言模型:
如大语言模型不支持FunctionCalling会导致所有涉及调用协同OA工具的Agent无法使用
# 模型测试不通过排查方法
1、首先,需要客户提供CURL测试命令,然后必须在CoMi服务器上执行CURL,测试有结果才能继续,【大模型准备和调试】章节有说明 2、然后,检查CURL测试命令的参数,确认该请求是OpenAI格式的请求,什么是OpenAI同样参考【大模型准备和调试】章节有说明 3、最后,如果确认是OpenAI的请求,提取CURL中的参数放到CoMI模型管理中配置并测试,尤其注意baseURL不要带CURL测试url中的 /v1/xxx 这段后缀!
[模型配置常见问题]章节提供了常见问题和排查思路,可做参考!
[模型配置常见问题]章节提供了常见问题和排查思路,可做参考!
[模型配置常见问题]章节提供了常见问题和排查思路,可做参考!
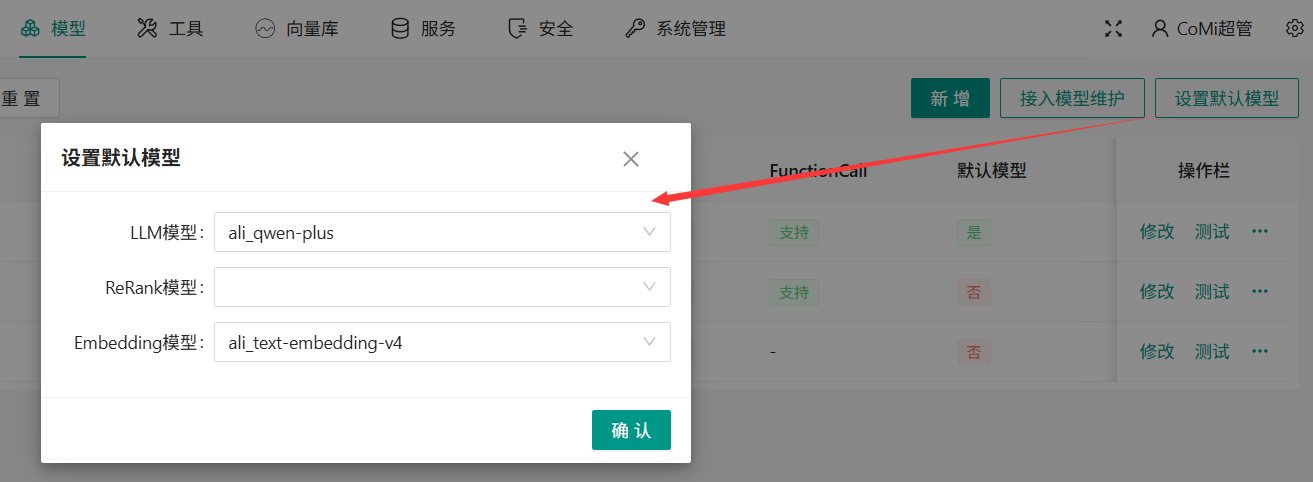
# 后台设置默认模型
模型页签,点击“设置默认模型”按钮,选择默认运行的模型:
- LLM大语言模型,必须
- ReRank模型,非必须
- Embedding模型,必须,选择质量较好的Embedding文本向量模型,默认Embedding模型一旦配置不允许修改!
为什么Embedding文本向量模型一旦配置不允许修改?因为不同文本向量模型算法不一,如混合使用会导致向量数据库错乱,无法给出高质量的数据
# 数据初始化和应用授权
首次部署或升级CoMi,需要到后台去初始化应用:系统管理员 → CoMiBuilder → 系统管理 → 数据初始化。此处在安装部署手册有详细说明,本文档不再赘述。
完成初始化之后,就可以用集团管理员或企业版单位管理员到CoMi应用授权,将初始化的应用授权给普通用户使用。这一步操作手册也有说明,本文档不再赘述。
# 模型对话-测试模型可用性
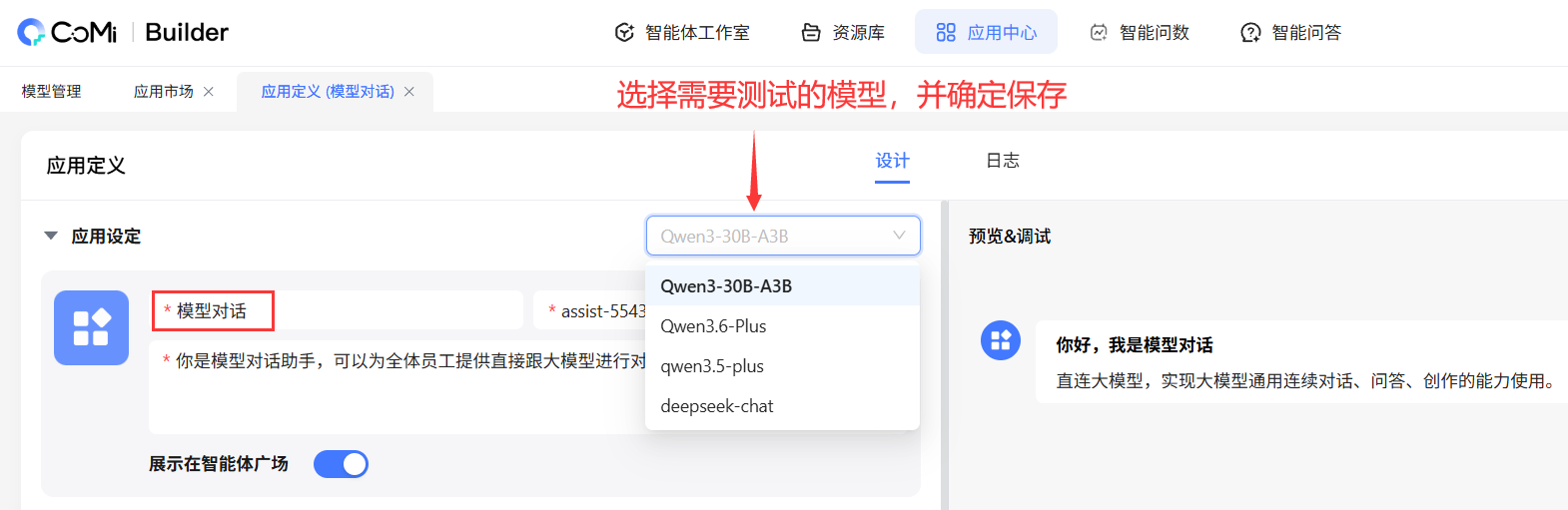
当模型配置完成、应用初始化和授权之后,我们需要测试模型的真实可用性,最推荐使用“模型对话”这个应用:
集团管理员或企业版单位管理员 → CoMiBuilder → 应用中心 → 搜索进入“模型对话” → 下拉修改需要测试的模型,确定保存后,即可在后台测试。 如果跟模型对话一直没有输出,那肯定是配置有问题或模型有问题。
# 公有云模型平台配置示例
# 华为云大模型平台模型配置
[华为云大模型中心] (opens new window) 提供了大量可调用的模型(按Tokens使用量计费),并且遵守OpenAI接口规范,尤其华为云提供的Embedding和ReRank模型是CoMi标准产品推荐的模型,使用公有云模型的客户可以选择华为云平台:
提醒:由于公有云平台较多,模型种类很丰富,CoMi无法充分测试每种模型的兼容性,故需要项目上配置之后自行做好充分的测试。
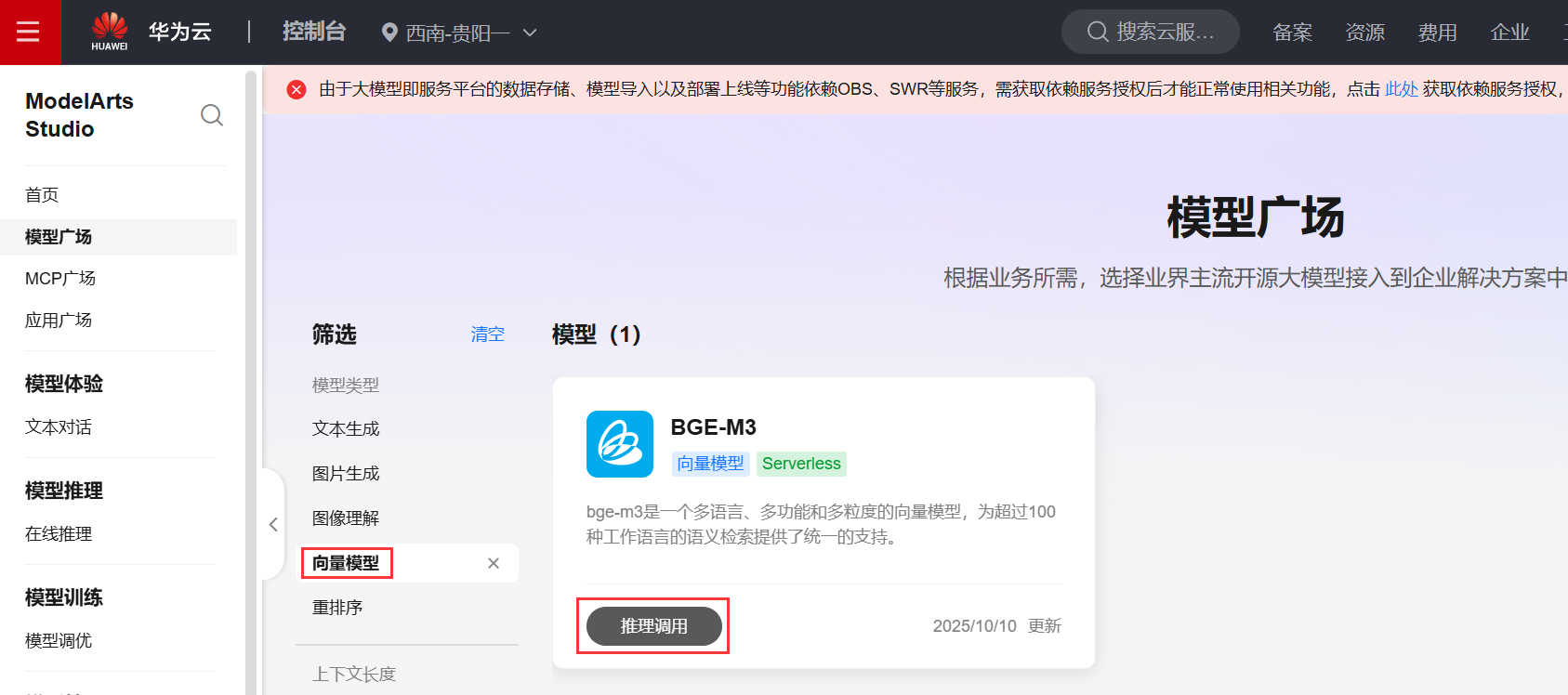
1、模型广场选择需要使用的模型,以向量模型为例,可以选择CoMi产品推荐的bge-m3
2、在调用说明中,按照引导创建API Key,并且复制CURL命令:
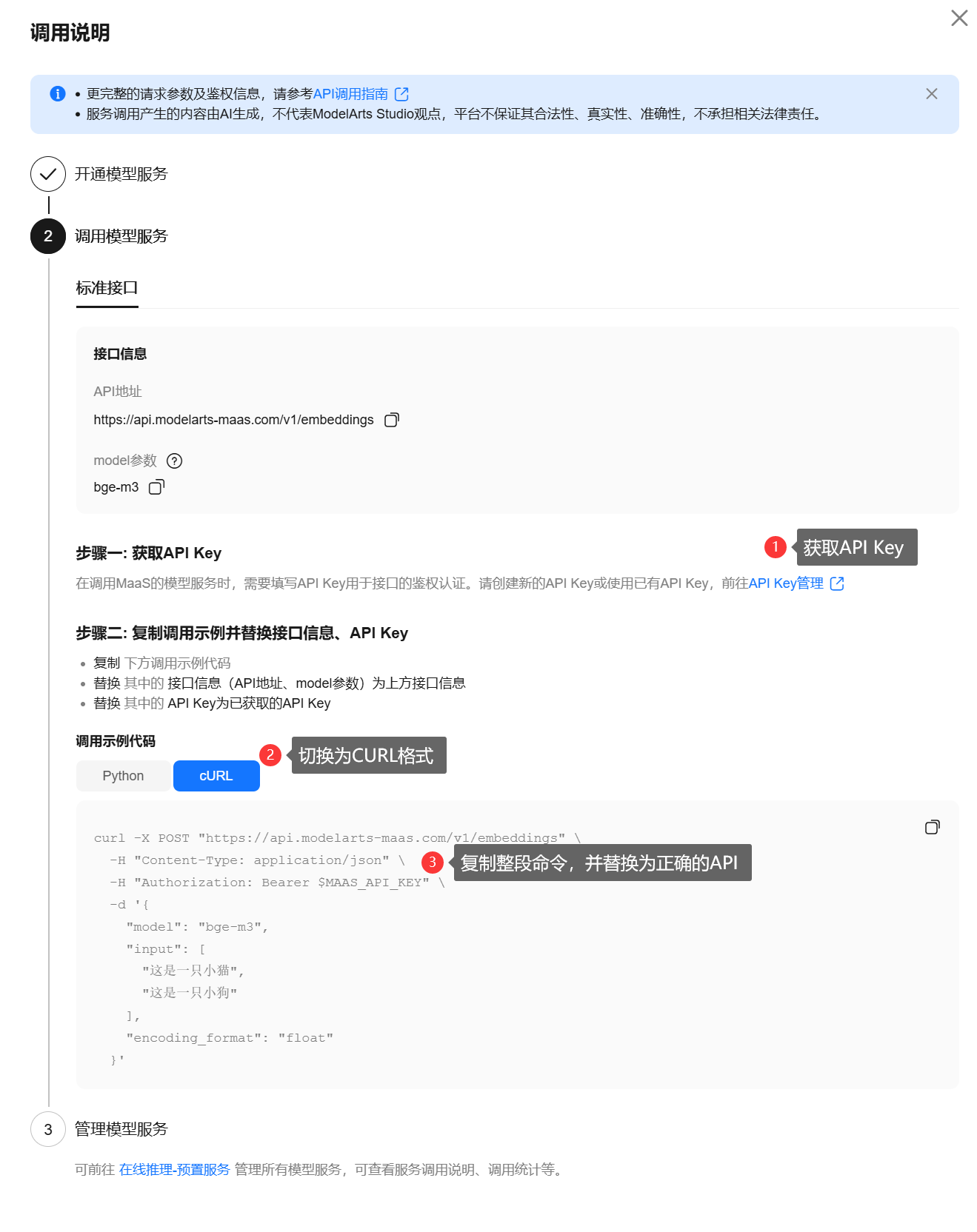
3、到CoMi服务器执行CURL测试命令,如果有向量数组结果则说明测试通过,随后提取模型配置到CoMi去配置模型
4、新建CoMi模型配置并测试启用模型:
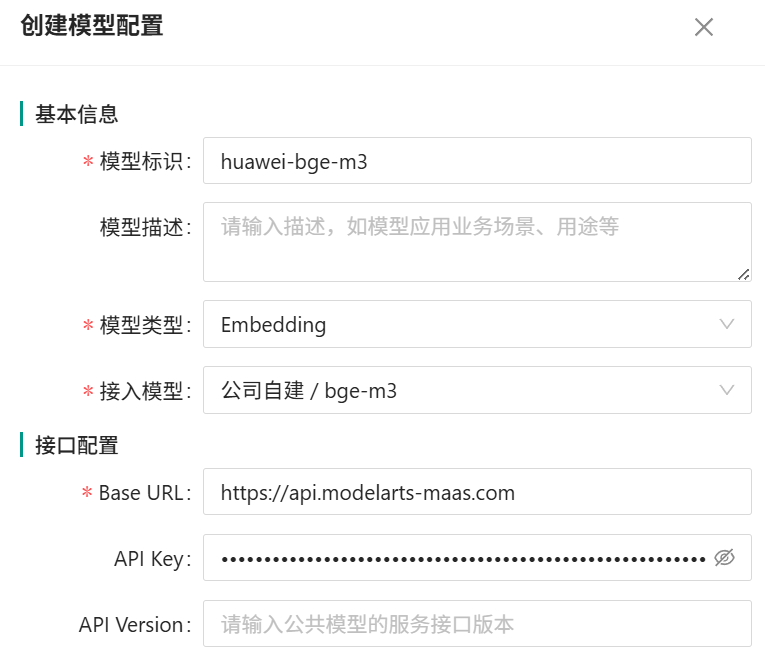

其它语言模型和ReRank模型也可以参照做配置,注意接口调用需要付费,请提前充值少量测试金额(如10元),避免CoMi初始化时因余额不足而失败。
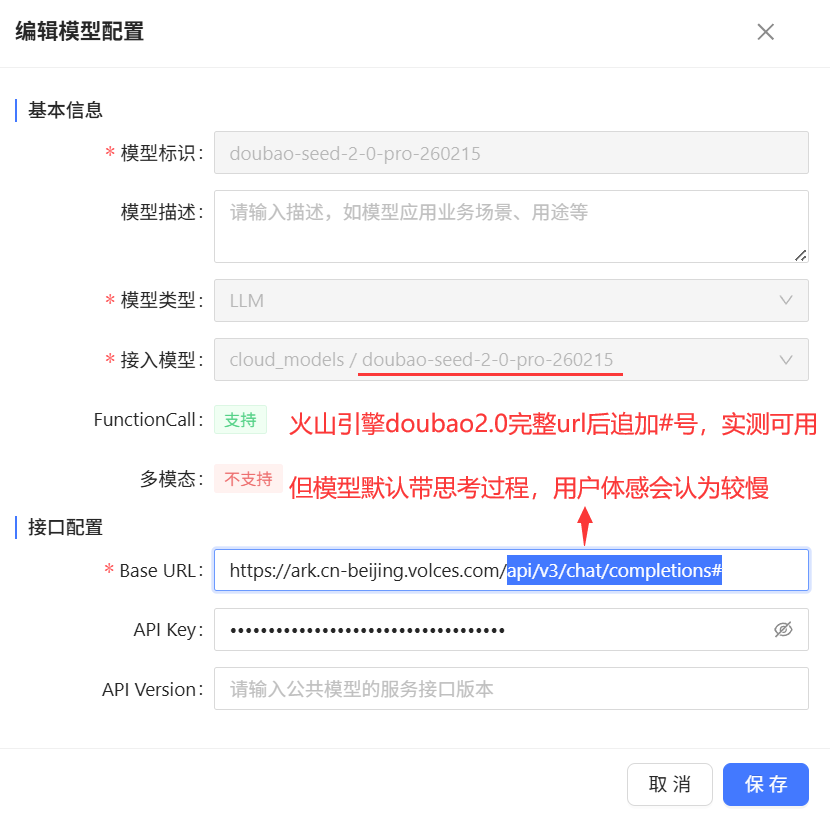
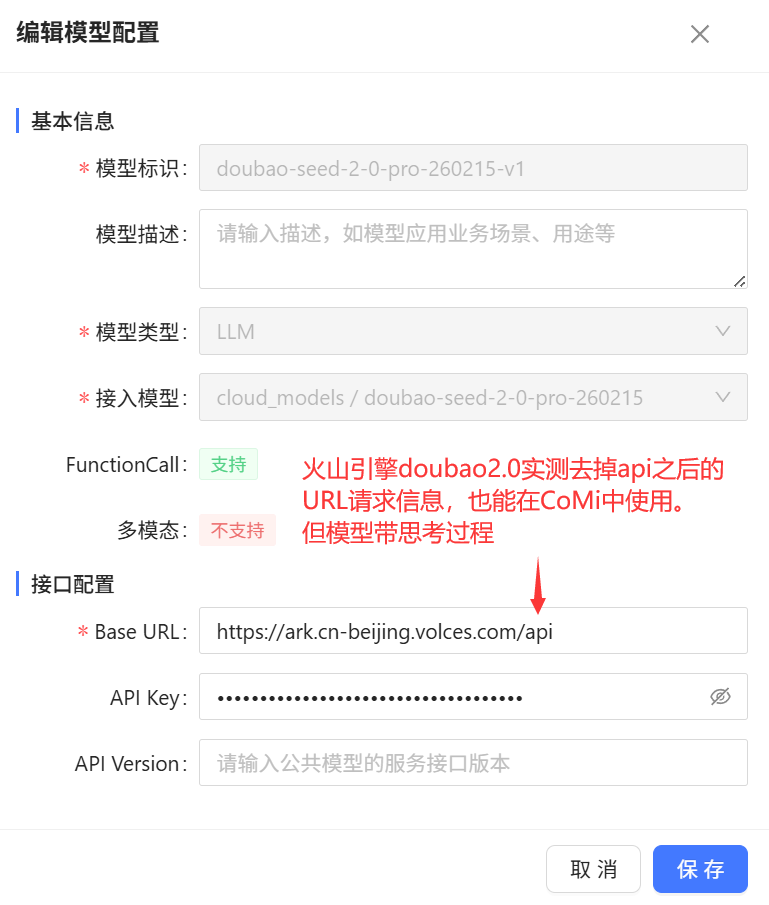
# 火山引擎公有云模型配置
提醒:由于公有云平台较多,模型种类很丰富,CoMi无法充分测试每种模型的兼容性,故需要项目上配置之后自行做好充分的测试。
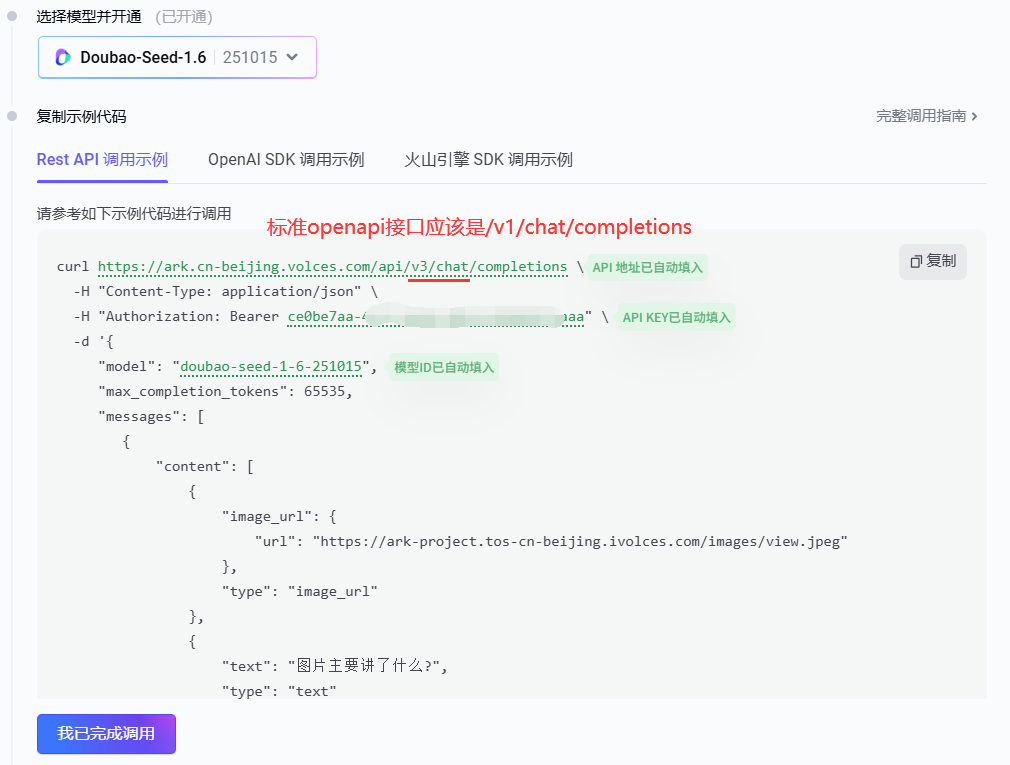
[火山引擎公有云] (opens new window) 的接口并非标准的OpenAI请求URL,如果按照火山引擎提供的 https://ark.cn-beijing.volces.com/api/v3/chat/completions 配置,CoMi无法使用,需要在URL后面加一个 # 号(CoMi产品内置规则),即 https://ark.cn-beijing.volces.com/api/v3/chat/completions# 可以使用。另外URL去掉api后面的 /v3/chat/completions 实测也可用。
火山引擎提供的LLM语言模型,实测可用。 但火山引擎提供的Embedding模型实测无法使用,故Embedding模型需要寻找其它公有云模型厂商替代。
# DeepSeek官方模型配置
截止2025年12月, [DeepSeek官网API平台] (opens new window) 仅提供了最新的LLM语言模型DeepSeek-V3.2调用(按Tokens计费)。
提醒:由于公有云平台较多,模型种类很丰富,CoMi无法充分测试每种模型的兼容性,故需要项目上配置之后自行做好充分的测试。
1、用户需要注册帐号,并进行适当的充值(调用接口涉及token费用)。
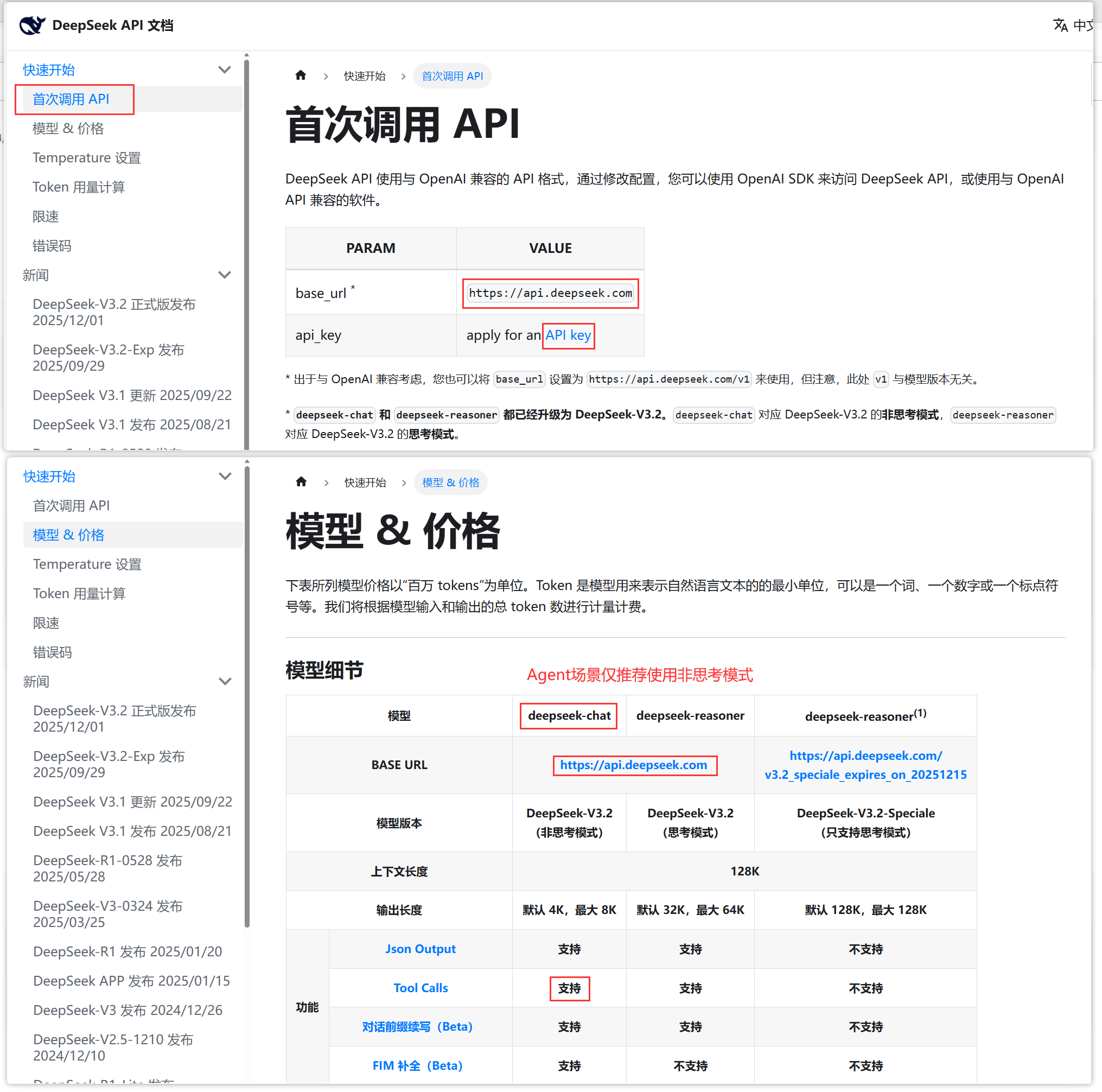
2、参考官网API平台的手册,可以获取DeepSeek最新版本的LLM模型信息如下:
- base url对应
https://api.deepseek.com - api key参考文档链接创建
- model设置为非思考模式
deepseek-chat(思考模式deepseek-reasoner虽然官宣支持tools,但comi下实测不兼容)
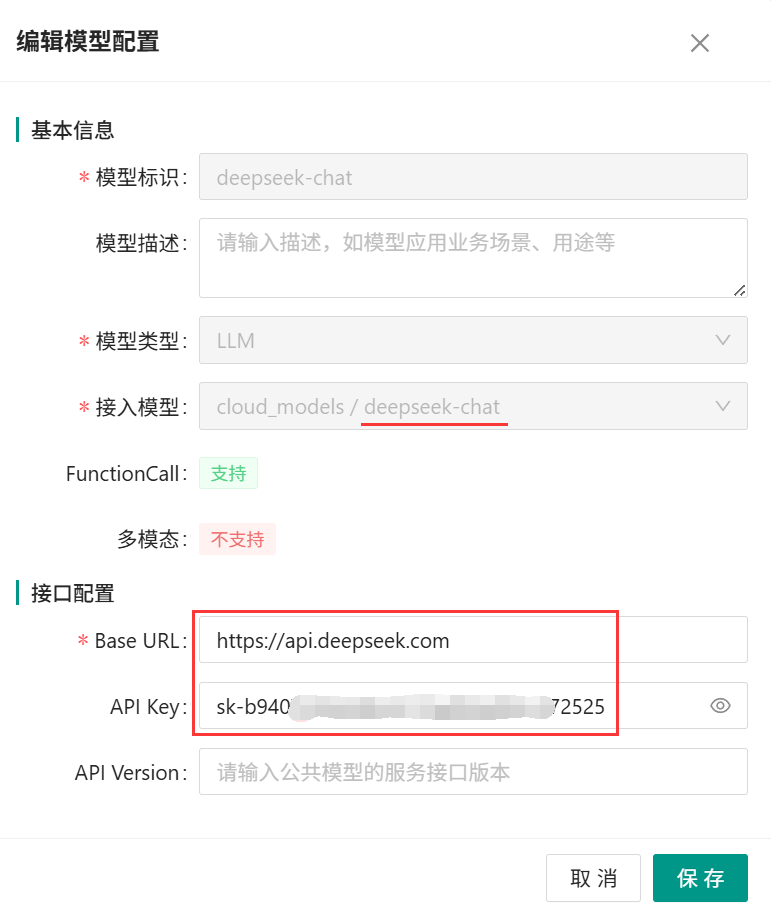
3、协同OA系统管理员CoMiBuilder模型管理后台成功配置DeepSeek LLM模型示例如下:
# 阿里云百炼平台模型配置
[阿里百炼平台] (opens new window) 同样提供了大量模型调用(按Tokens计费),该平台主要以通义大模型为主。
提醒:由于公有云平台较多,模型种类很丰富,CoMi无法充分测试每种模型的兼容性,故需要项目上配置之后自行做好充分的测试。
1、用户需要使用阿里系列帐号登录,建议进行适当的充值(调用接口涉及token费用)。
2、在模型广场,可以选择合适的模型,比如LLM模型可以选择 qwen-plus ,然后进入 API参考 页面进行调用测试:
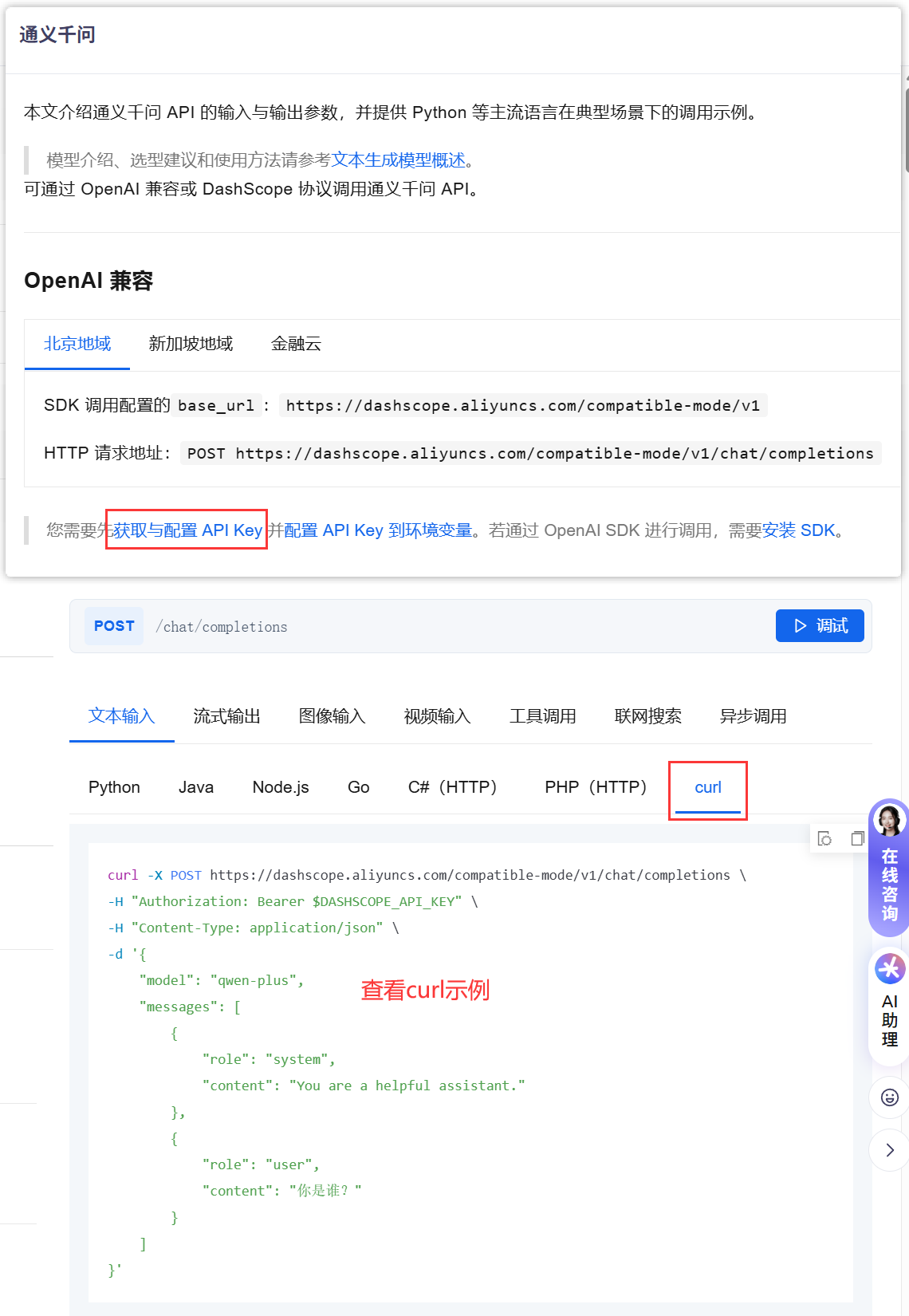
3、API参考页面 按照引导获取API KEY 和 测试使用的URL,以qwen-plus模型为例,模型信息如下:
- base url对应
https://dashscope.aliyuncs.com/compatible-mode - api key参考文档链接创建
- model设置为
qwen-plus
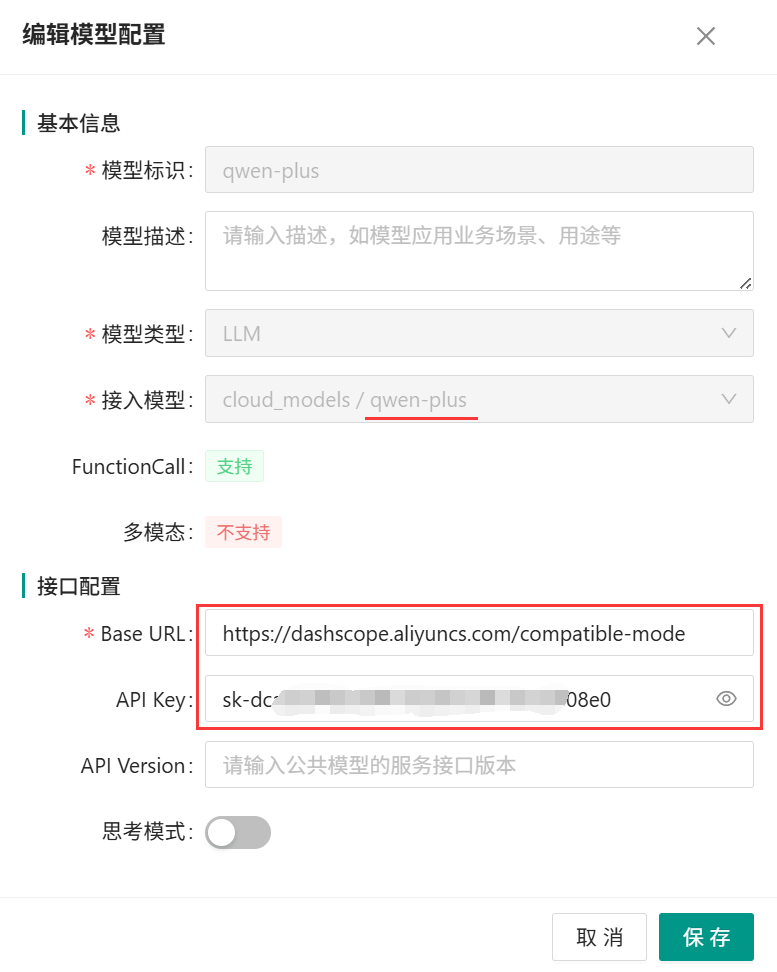
4、协同OA系统管理员CoMiBuilder模型管理后台成功配置qwen-plus模型示例如下:
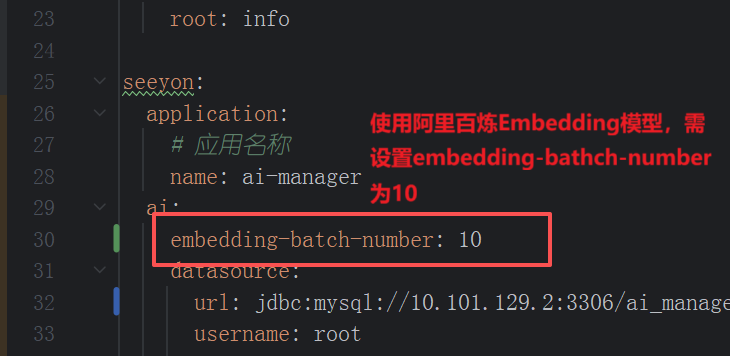
阿里百炼平台Embedding文本向量模型注意事项: 阿里百炼平台提供了Embedding模型,但有几个点需要注意:
- 1)研发推荐bge-m3作为标配模型,阿里百炼平台Embedding模型测试较少,可能存在BUG。替换方案:(截止2025年12月)华为云模型平台、硅基流动均提供了bge-m3公有云模型调用。
- 2)如果客户计划前期使用公有云Embedding模型,后期需要迁移到本地化Embedding模型,则不推荐阿里百炼平台Embedding模型,公有云切本地化模型如果model型号不一致,所有向量数据需要重新初始化。
- 3)已知阿里百炼Embedding模型向量化batch有限制,协同知识通过全文检索推送到CoMi向量库会失败,需要在Comi的ai-manager/application.yaml设置
embedding-batch-number: 10
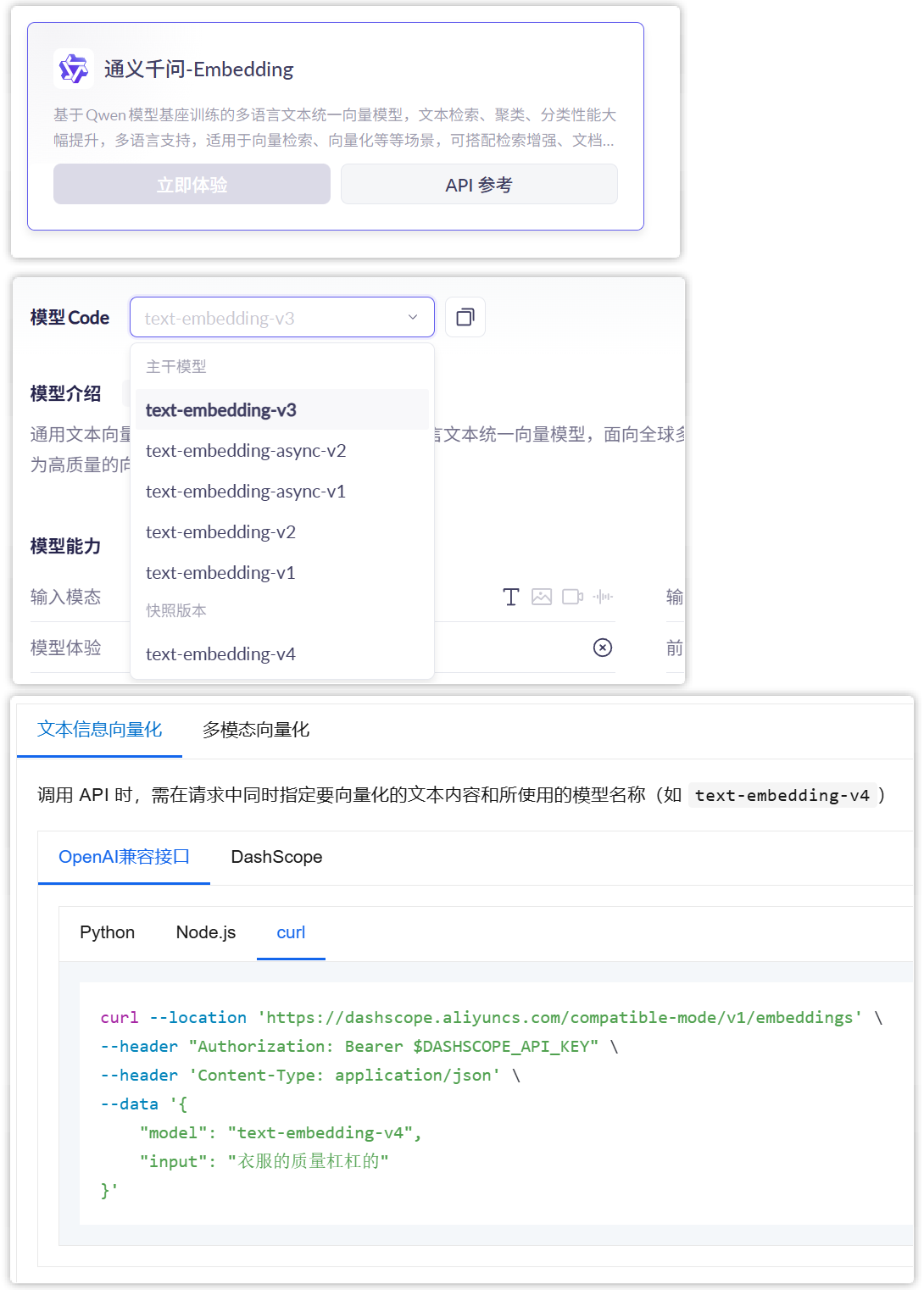
vim ai-manager/application.yaml
在seeyon.ai下新增一行参数embedding-batch-number: 10
以上配置修改后,重启ai-manager服务生效
# 硅基流动SiliconCloud平台模型配置
[硅基流动] (opens new window) 的SiliconCloud平台提供了大量开源模型的API调用,该平台提供的模型服务与华为云模型平台比较类似,但硅基流动提供的模型比华为云模型平台多 -- 以Embedding嵌入模型和ReRank模型为例,硅基流动提供了10多种型号的模型,华为云仅2种。硅基流动的Embedding(bge-m3)和ReRank模型(bge-reranker-v2-m3)是CoMi标准产品推荐的模型,使用公有云模型的客户也可以选择硅基流动平台。
提醒:由于公有云平台较多,模型种类很丰富,CoMi无法充分测试每种模型的兼容性,故需要项目上配置之后自行做好充分的测试。
1、用户需要注册并登录,建议进行适当的充值(调用接口涉及token费用)。
2、调用模型都需要API KEy,在模型广场页面创建一个个人的API密钥:
3、进入硅基流动模型广场 → 展开筛选器 → 选择需要使用的模型(LLM模型选择“对话”,Embedding模型选择“嵌入”,ReRank模型选择“重排序”)
4、查看对应模型详细介绍,确认无误后,进入API文档页面:
5、API手册页面,可以直接进入在线调试:
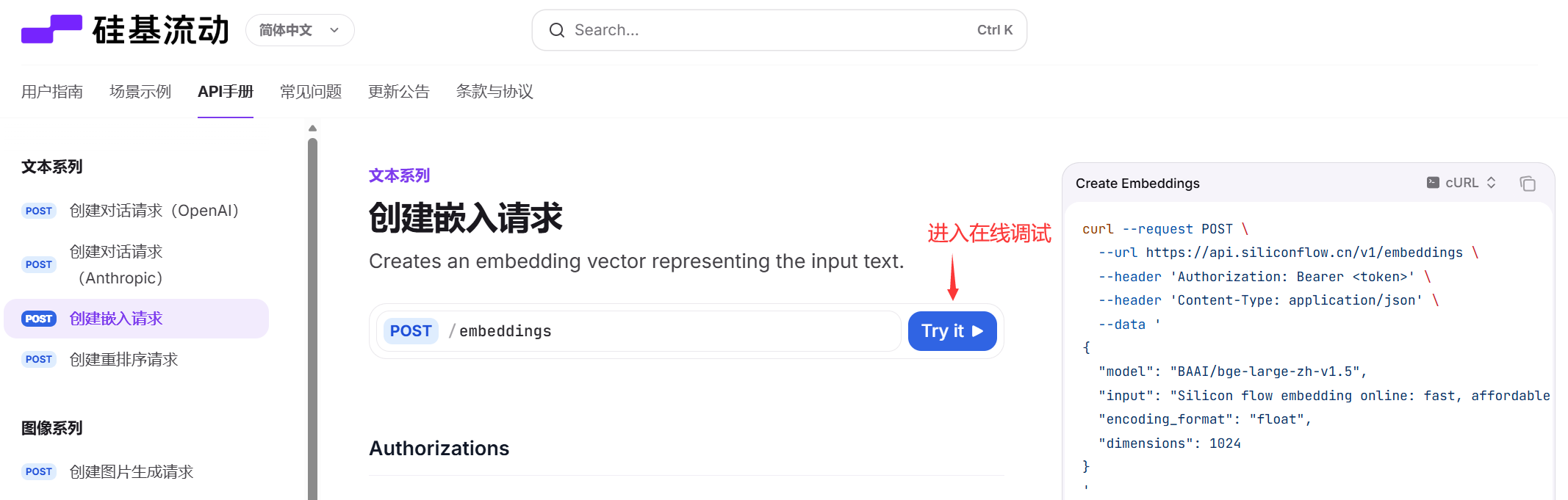
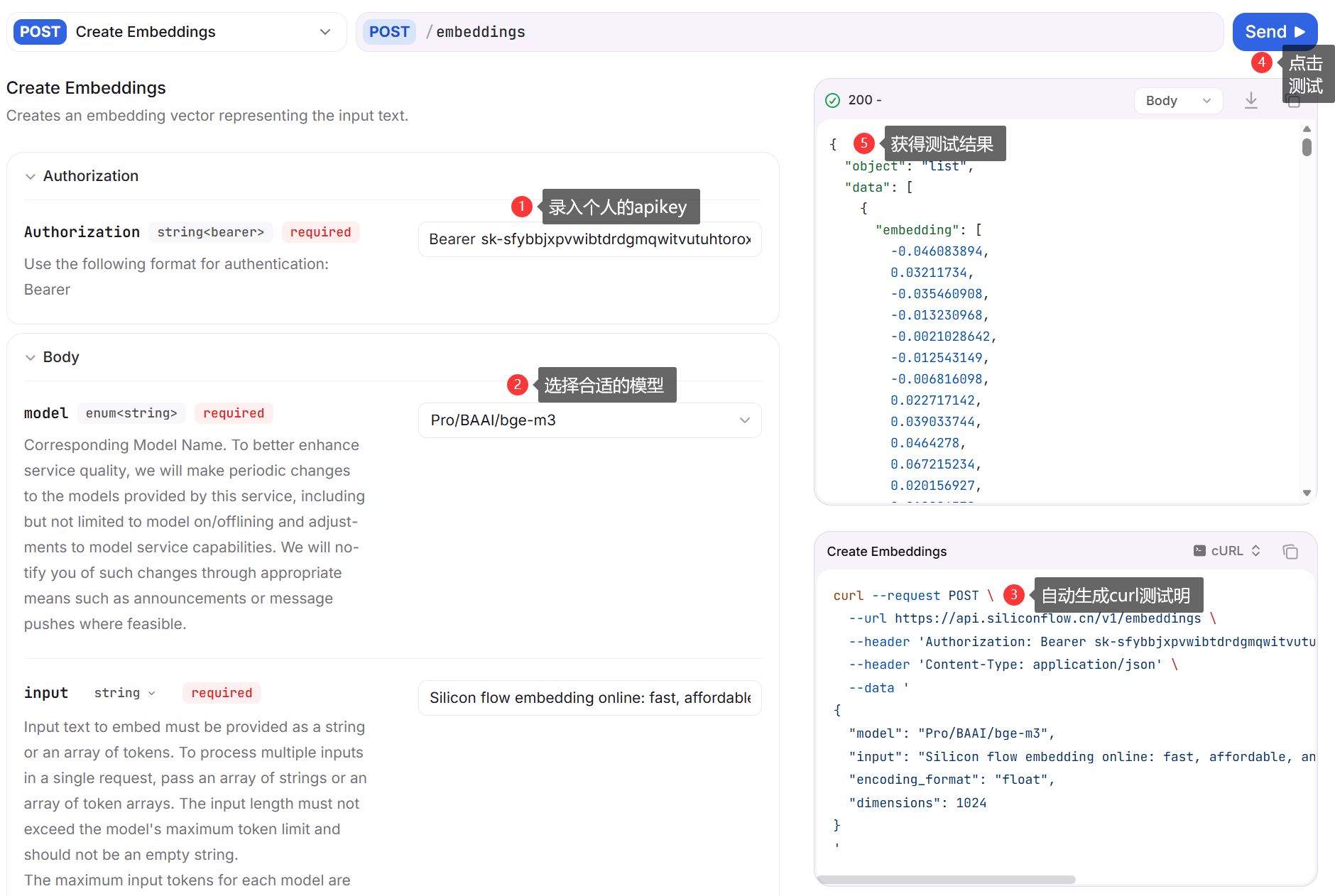
6、可以录入前面申请的API密钥,以及选择合适的模型,硅基流动API平台会自动生成curl测试命令,并且支持在线测试。如按照下图配置,模型信息如下:
- base url对应
https://api.siliconflow.cn - api key对应前面申请的API密钥
- model设置为
Pro/BAAI/bge-m3
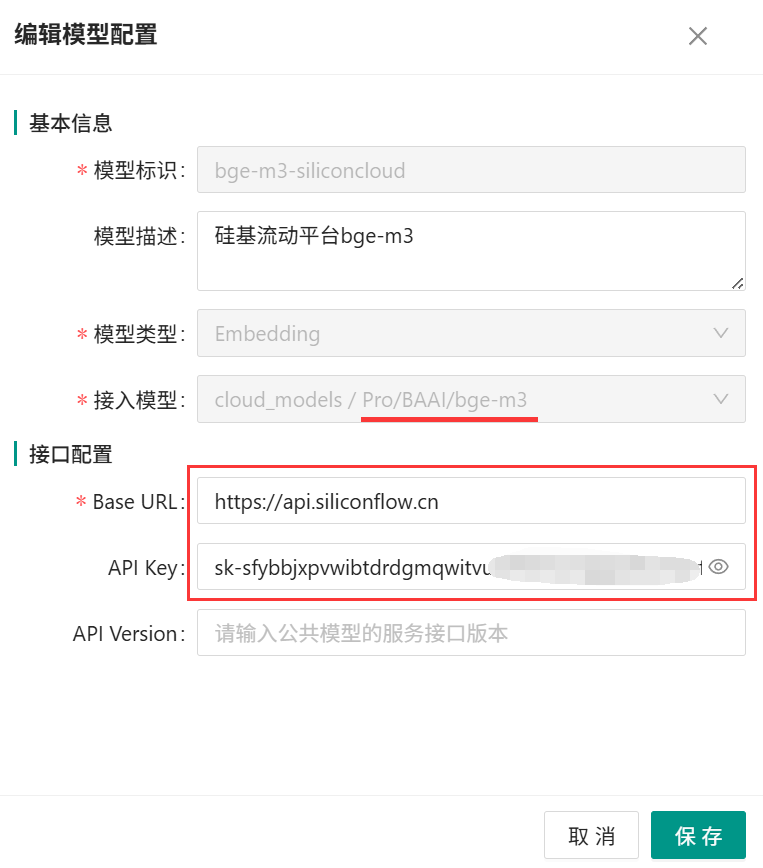
7、协同OA系统管理员CoMiBuilder模型管理后台成功配置硅基流动bge-m3模型示例如下:
# 阿里百炼Codingplan模型配置
随着AI的爆火,许多个人用户大量开始依赖大模型的tokens算力,为了让用户能体验到便宜好用的模型,各平台纷纷推出了Coding Plan订阅服务,旨在让用户用较低的成本使用到公有云模型。 Coding Plan模式是否可以被CoMi接入,判断方法不变:接口是否遵守OpenAI?模型是否具有Function calling?具备就可以使用。
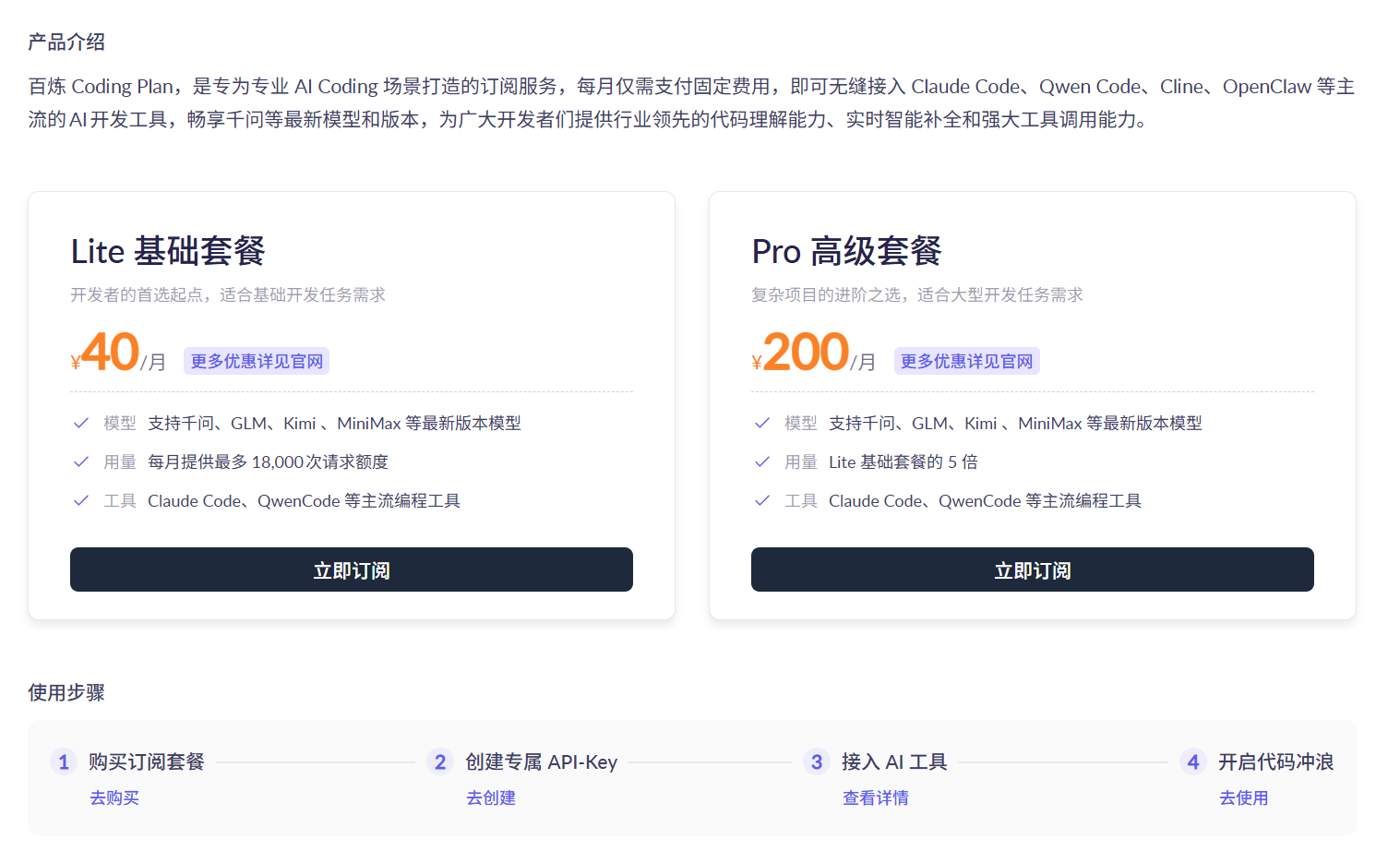
本章以阿里百炼平台Coding Plan为例,提供CoMi接入配置方法:
1、自行到平台付费订阅Coding Plan:
2、付费订阅后,再订阅面板可以获取Coding Plan的API KEY、模型连接BaseURL 以及 支持的模型:
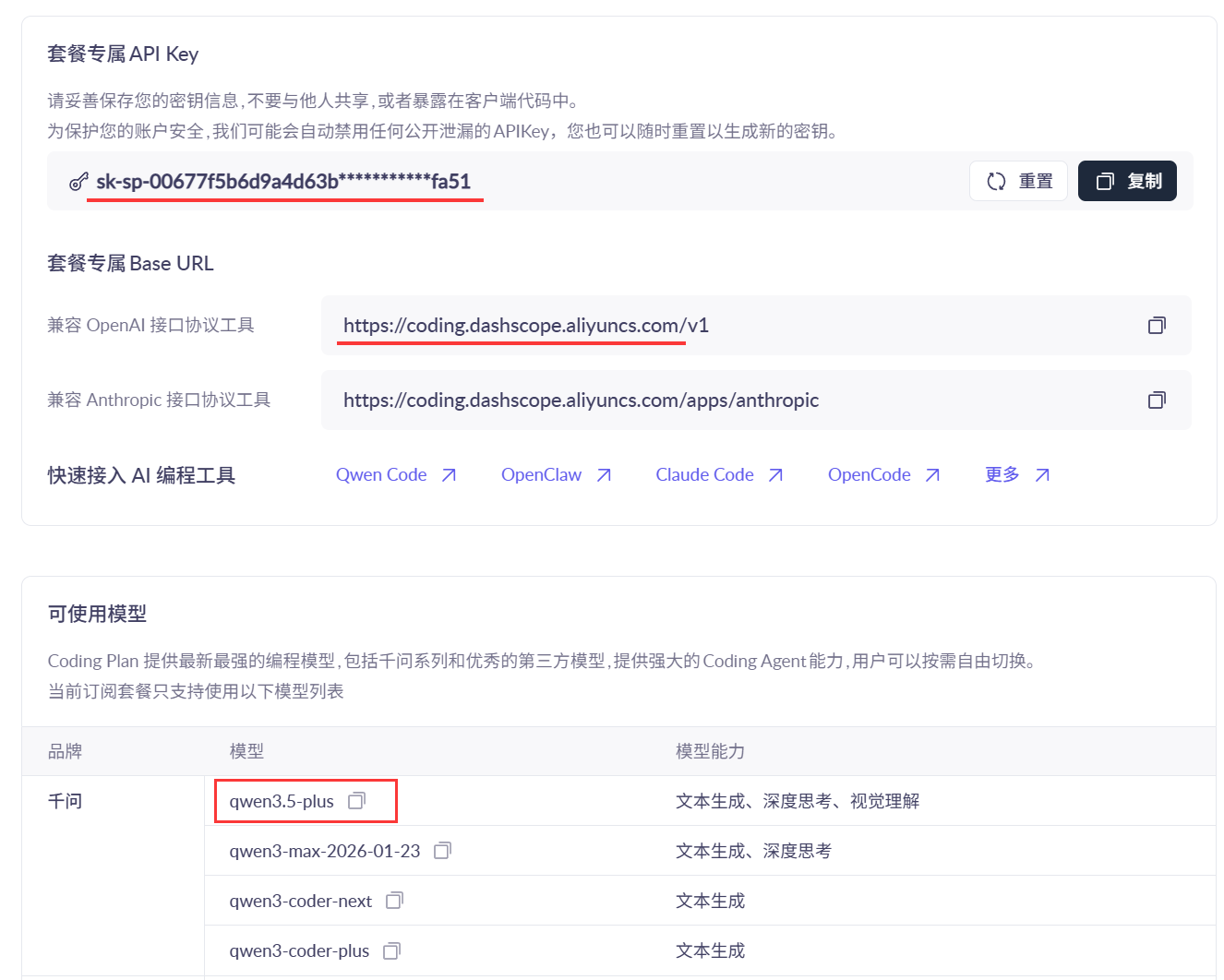
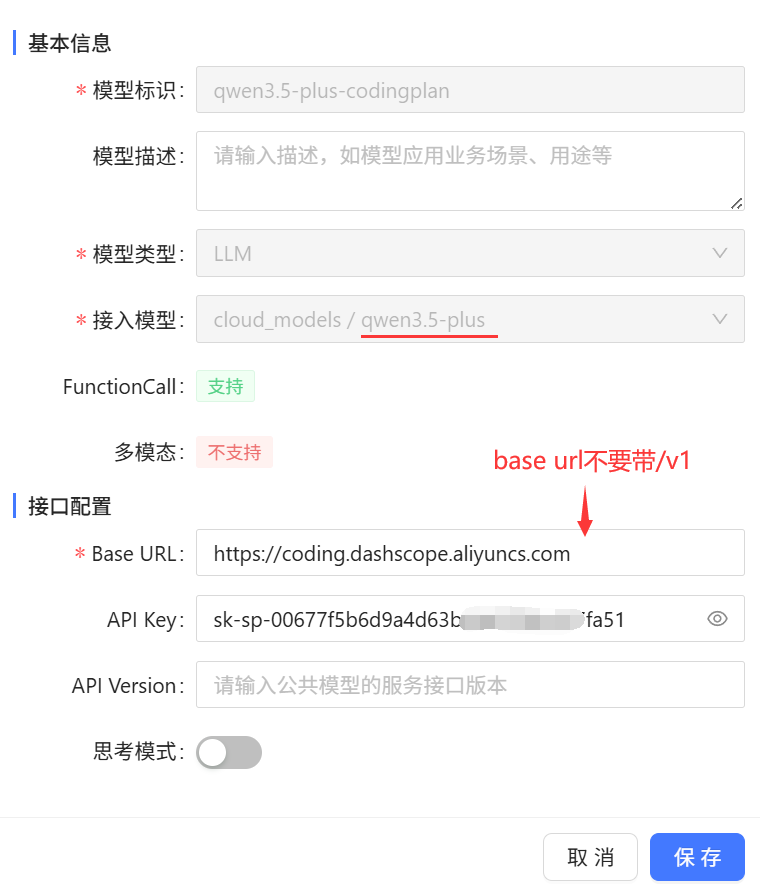
3、选择合适的模型,接入到CoMi中,如下是在CoMi环境接入配置成功的案例:
# 模型配置常见问题
# 1、只能输入英文、数字、中划线、下划线和.
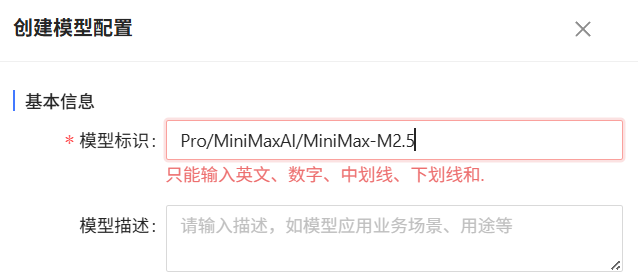
问题:创建模型配置-模型标识输入报错:只能输入英文、数字、中划线、下划线和.
原因:不是大问题,录入内容触发了特殊字符校验
解决方案:模型标识是CoMi给模型取的别名,可以随意自定义,如遇到特殊字符无法保存,就去掉不支持的特殊字符即可。
# 2、FunctionCall不支持
问题:连接状态“通过” 但FunctionCall“不支持”
原因有很多种:
- 第1种)当前模型就是不支持FunctionCall;
- 第2种)[接入模型]的名称错误,这个模型可能不存在!
- 第3种)CoMi配置的模型baseurl地址错误,要求baseurl取
/v1/xxx前面的地址,只要不是这样都会有这个问题 - 第4种)API Key配置错误,如果模型供应商要求录入APIKEY,填写错误也会显示这个问题
- 第5种)API Key没钱了,欠费无法调用模型
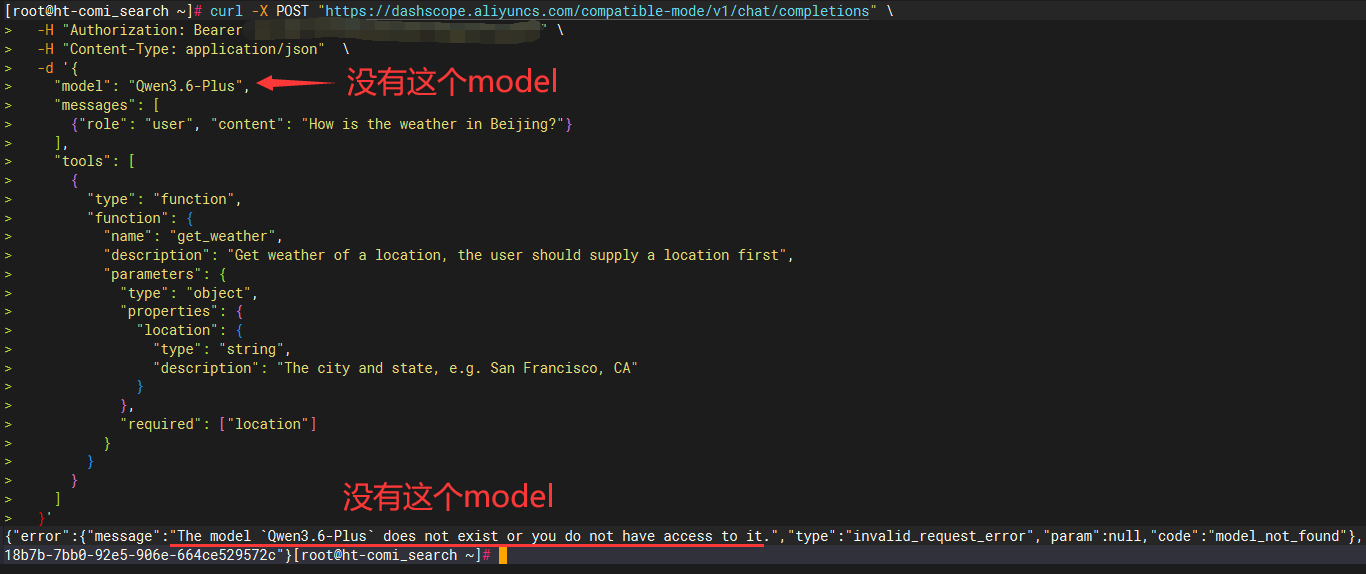
解决方案:无论那种原因,都可以统一通过 [测试FunctionCall的CURL命令] 查看错误信息就能发现问题。
- 如果是第1种问题(模型本身不支持FunctionCall),通过CURL测试会直接提示
tool choice requires,这种就需要换模型或联系客户开启模型的FunctionCall特性。 - 如果是第2、3、4、5种问题,通过CURL都会有对应错误提示(可以取错误让AI分析)。这几种场景问题都必须解决,否则功能都无法使用!

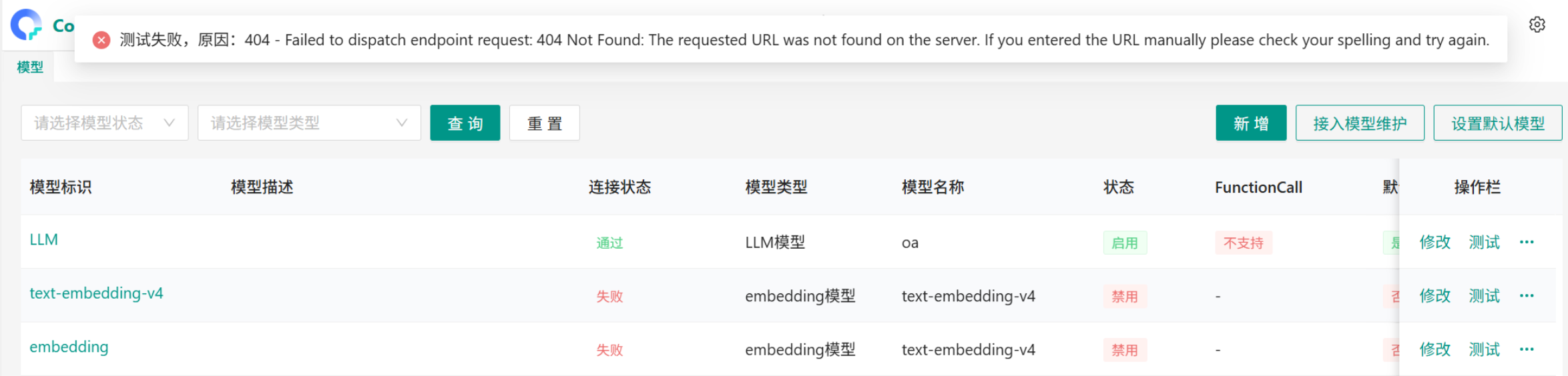
# 3、测试失败,原因:404 - Failed to dispatch endpoint request
问题:CoMi新建配置模型后测试报404
原因:模型baseurl配置错误
解决方案:参考关联FAQ https://open.seeyoncloud.com/#/faq/faq/v1/share?url=Z2JySmU+NjE6Mg==
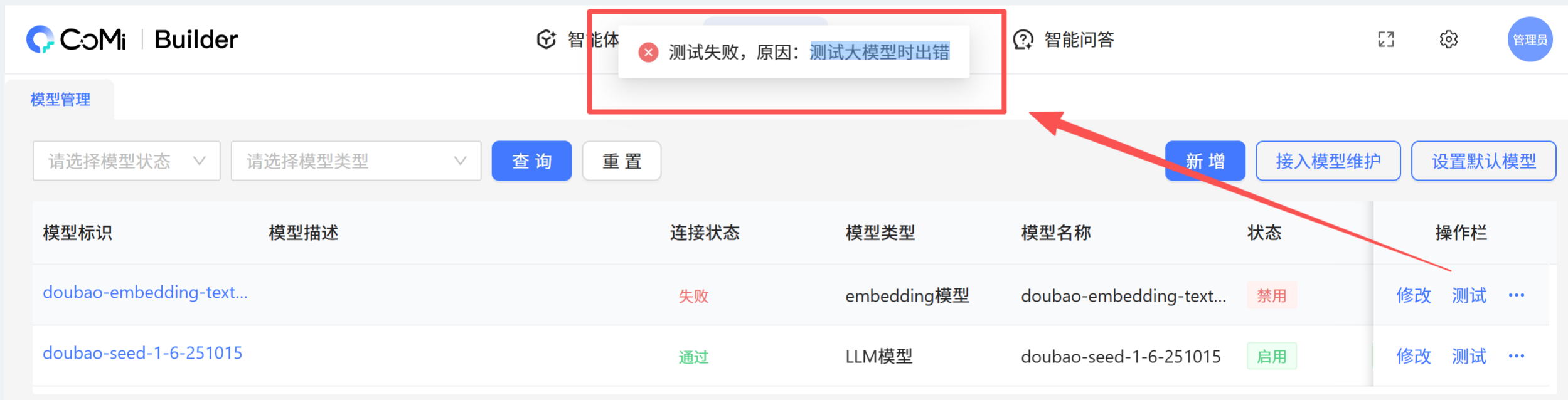
# 4、测试失败,原因:测试大模型时出错
原因:问题可能是该模型不是OpenAI接口的地址,比如doubao的Embedding模型baseURL是 /v3/embedding ,这个不是标准的OpenAI接口,无法使用。
解决方案:同样采用CURL测试,根据错误去分析问题。
# 5、不支持联网搜索
问题:有的支持联网搜索,有的不支持联网搜索,怎么才能开启联网搜索?
答案:这个联网搜索是模型本身的能力(或模型服务提供商提供的能力),不是我们通过配置就能解决的。通常开源模型都不具备联网搜索,支持联网搜索的往往是那些公有云服务供应商,比如实测阿里百炼的商用模型就支持联网搜索。
支持联网搜索的大模型,在使用时只要涉及外部信息查询,就会自动触发联网搜索,无需额外配置联网 MCP,实用性更强。

