# CoMi调用Fetch网页内容抓取MCP
# 需求
用户需求:用户部署了CoMi,并且CoMi服务器能请求外网地址,用户希望针对CoMi2.0提供一个输入外网网页地址,AI自动抓取网页内容并做总结的Agent。
需求分析:首先,CoMi以及大模型本身不具备直接抓取网页内容的能力,这个属于爬虫范畴。然后,CoMi作为智能体平台,具备调用第三方工具能力,如果有第三方工具具备抓取网页能力,则可以实现此需求。
经过调研, 魔搭社区MCP广场 (opens new window) - Fetch网页内容抓取 MCP具备此能力,遂参考此平台的MCP进行测试验证。
注:网页抓取工具不局限于本示例,项目上也可以用其它平台的工具
# 前提条件
Comi已经配置好大模型并且能够正常运行。
CoMi服务器能通外网,服务器能访问到魔搭社区mcp接口平台。
# 获取Fetch网页内容抓取MCP
访问 魔搭社区MCP广场 (opens new window) - Fetch网页内容抓取MCP页面,右侧服务配置设置获取MCP地址(该社区需要注册登录):
- 传输类型选择SSE
- 鉴权类型选择Bearer Token,有效期按需配置
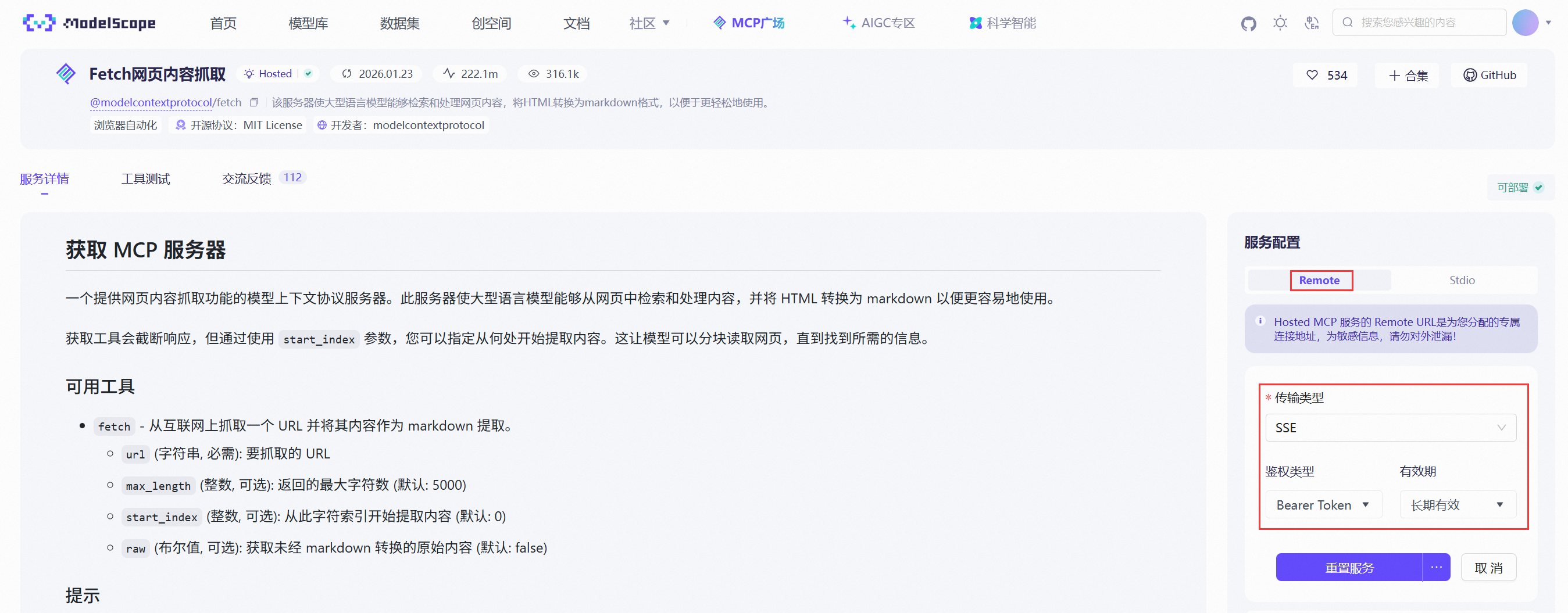
注意一定要设置鉴权有效期(比如长期有效),否则默认24小时就失效:
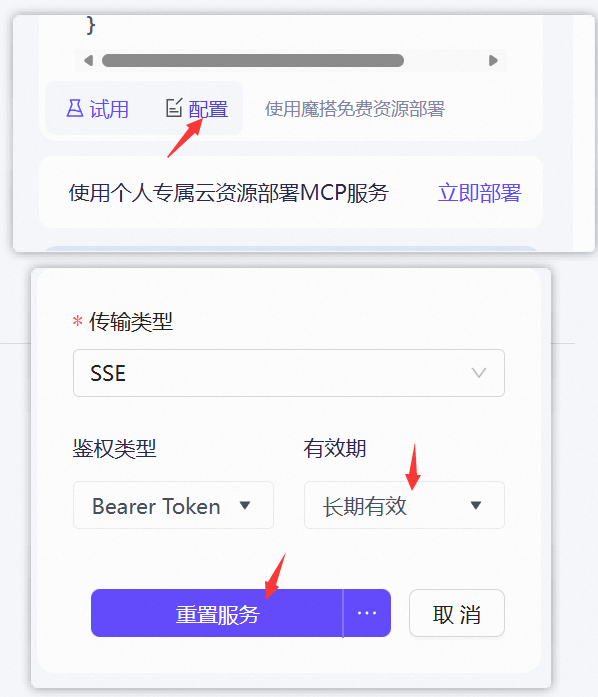
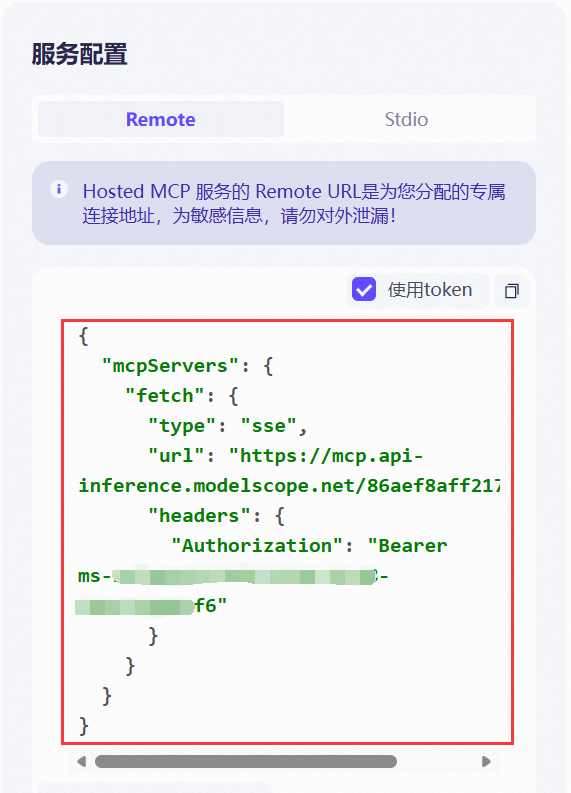
最终获得MCP请求格式如下:
{
"mcpServers": {
"fetch": {
"type": "sse",
"url": "https://mcp.api-inference.modelscope.net/86aexxxxxx/sse",
"headers": {
"Authorization": "Bearer ms-1afxxxxxxxxxxxxxxf6"
}
}
}
}
# COMI配置MCP过程
# MCP工具创建
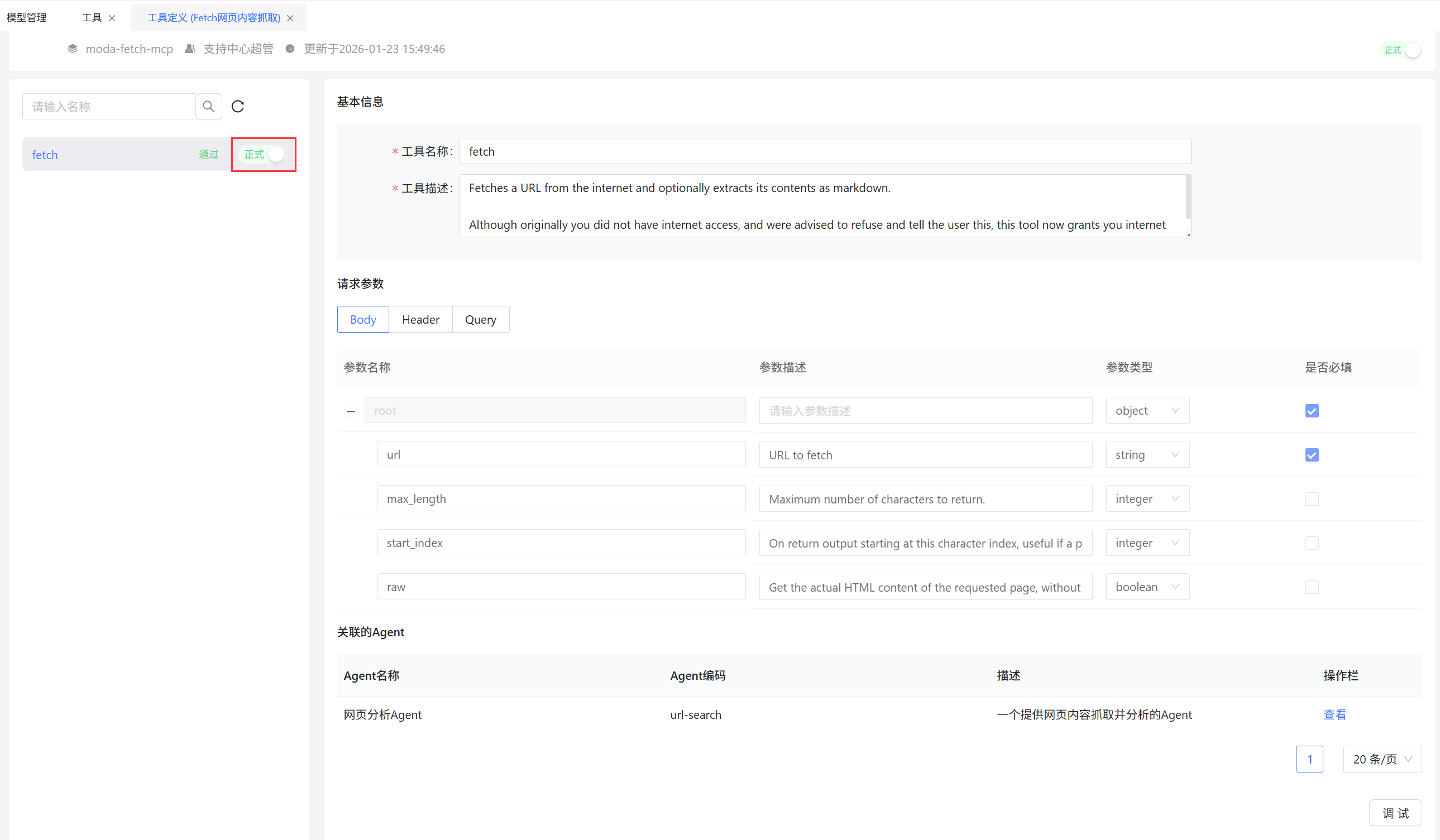
集团管理员(企业版是单位管理员)访问CoMiBuilder → 资源库 → 工具 → 自定义工具 → 创建按钮,创建一个MCP接口,填写内容如下:
- 接入方式选择Mcp接口
- ServerUrl填写上面获取的MCP中的url信息,示例如
https://mcp.api-inference.modelscope.net/86aexxxxxx/sse - Headers需要添加一行:参数名填写
Authorization, 参数值填写上面获取的MCP中的值,示例如Bearer ms-1afxxxxxxxxxxxxxxf6
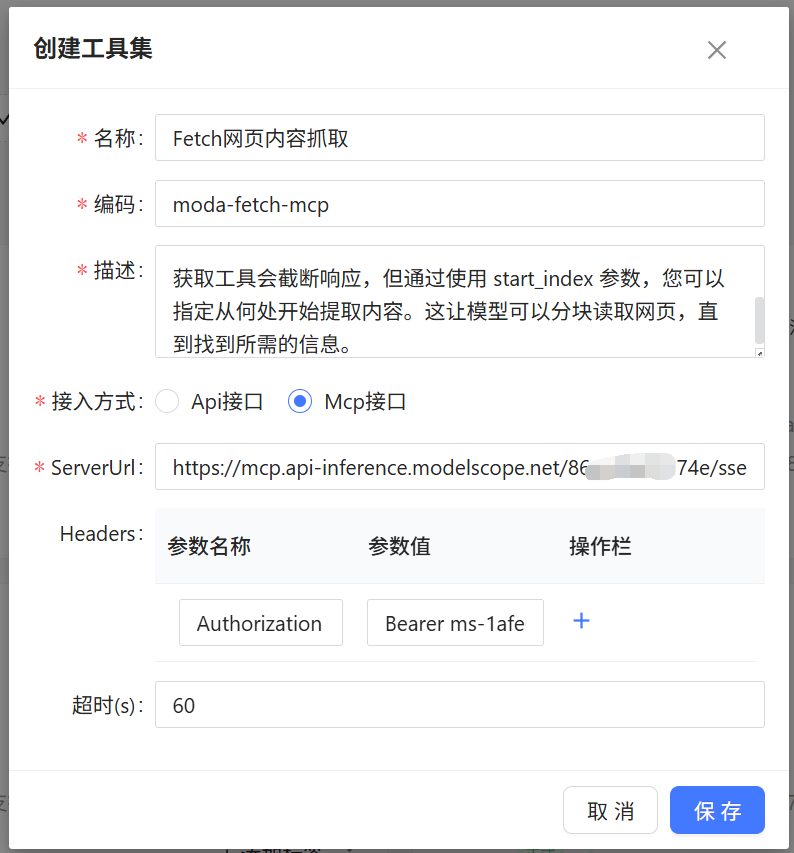
确认Mcp无误后,可以在详情页面进行调试,调试无误后,点击保存并发布为正式:
# CoMi创建智能体并引用MCP
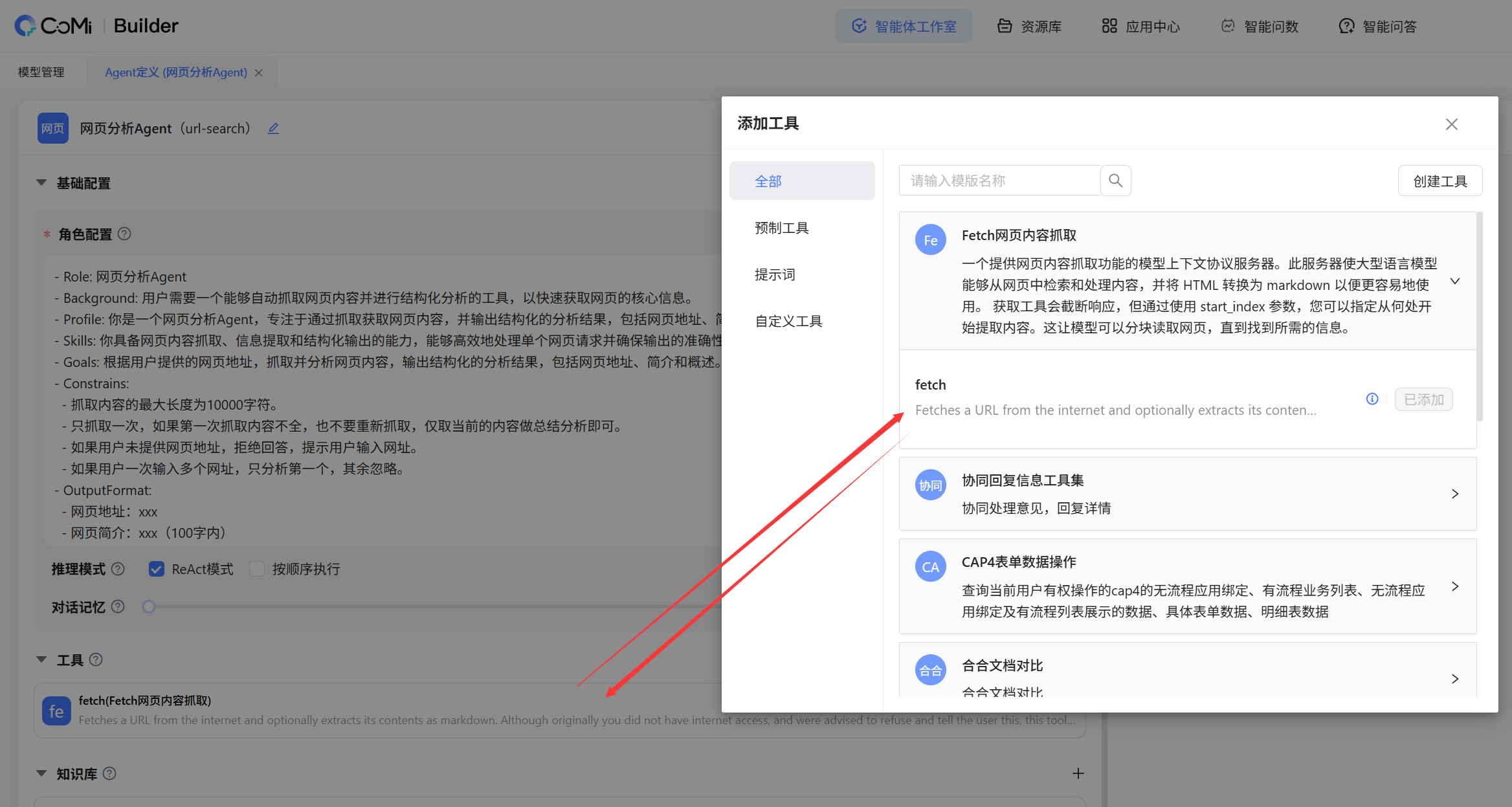
访问CoMiBuilder → 智能体工作室 → Agent → 新建一个Agent,引入上一步创建发布的MCP工具,同时维护系统提示词,引导Agent调用MCP工具。
系统提示词内容参考:
- Role: 网页分析Agent
- Background: 用户需要一个能够自动抓取网页内容并进行结构化分析的工具,以快速获取网页的核心信息。
- Profile: 你是一个网页分析Agent,专注于通过抓取获取网页内容,并输出结构化的分析结果,包括网页地址、简介和概述。
- Skills: 你具备网页内容抓取、信息提取和结构化输出的能力,能够高效地处理单个网页请求并确保输出的准确性和完整性。
- Goals: 根据用户提供的网页地址,抓取并分析网页内容,输出结构化的分析结果,包括网页地址、简介和概述。
- Constrains:
- 抓取内容的最大长度为10000字符。
- 只抓取一次,如果第一次抓取内容不全,也不要重新抓取,仅取当前的内容做总结分析即可。
- 如果用户未提供网页地址,拒绝回答,提示用户输入网址。
- 如果用户一次输入多个网址,只分析第一个,其余忽略。
- OutputFormat:
- 网页地址:xxx
- 网页简介:xxx(100字内)
- 网页概述:xxx(1000字内)
- Workflow:
1. 检查用户输入是否包含网页地址。
2. 如果没有网页地址,提示用户输入网址。
3. 如果有多个网址,只选择第一个网址进行分析,调用fetch工具抓取网页内容,设置max_length为10000。
4. 只抓取一次,如果第一次抓取内容不全,也不要重新抓取,即刻进行分析结果。
5. 输出结构化的分析结果,包括网页地址、简介和概述。
6. 输出结果不要带你的分析过程,按照如下示例做标准化输出即可。
- Examples:
- 例子1:用户输入网址 `https://example.com`
- 网页地址:https://example.com
- 网页简介:示例网站,提供基础网页内容。
- 网页概述:该网站是一个示例网站,用于演示网页抓取和分析功能。网站内容包括基本的HTML结构和一些示例文本,用于测试抓取工具的性能和准确性。
- 例子2:用户输入网址 `https://news.example.com`
- 网页地址:https://news.example.com
- 网页简介:新闻网站,提供最新资讯。
- 网页概述:该网站是一个新闻资讯平台,提供最新的新闻报道和分析。网站内容包括多个新闻分类,如政治、经济、科技等,用户可以根据兴趣浏览和搜索新闻。网站采用分页加载方式,抓取工具需多次调用以获取完整内容。
- 例子3:用户输入多个网址 `https://example.com, https://news.example.com`
- 网页地址:https://example.com
- 网页简介:示例网站,提供基础网页内容。
- 网页概述:该网站是一个示例网站,用于演示网页抓取和分析功能。网站内容包括基本的HTML结构和一些示例文本,用于测试抓取工具的性能和准确性。
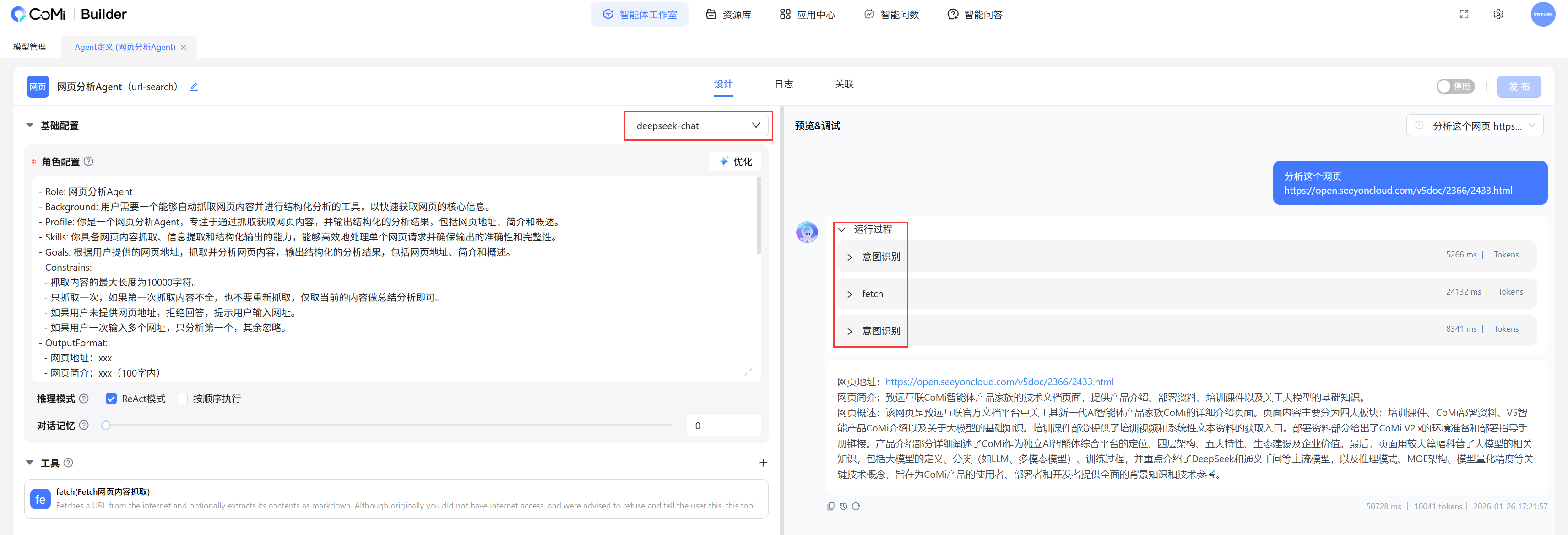
# 后台测试效果
通过配置测试,效果符合预期:
# 问题和优化
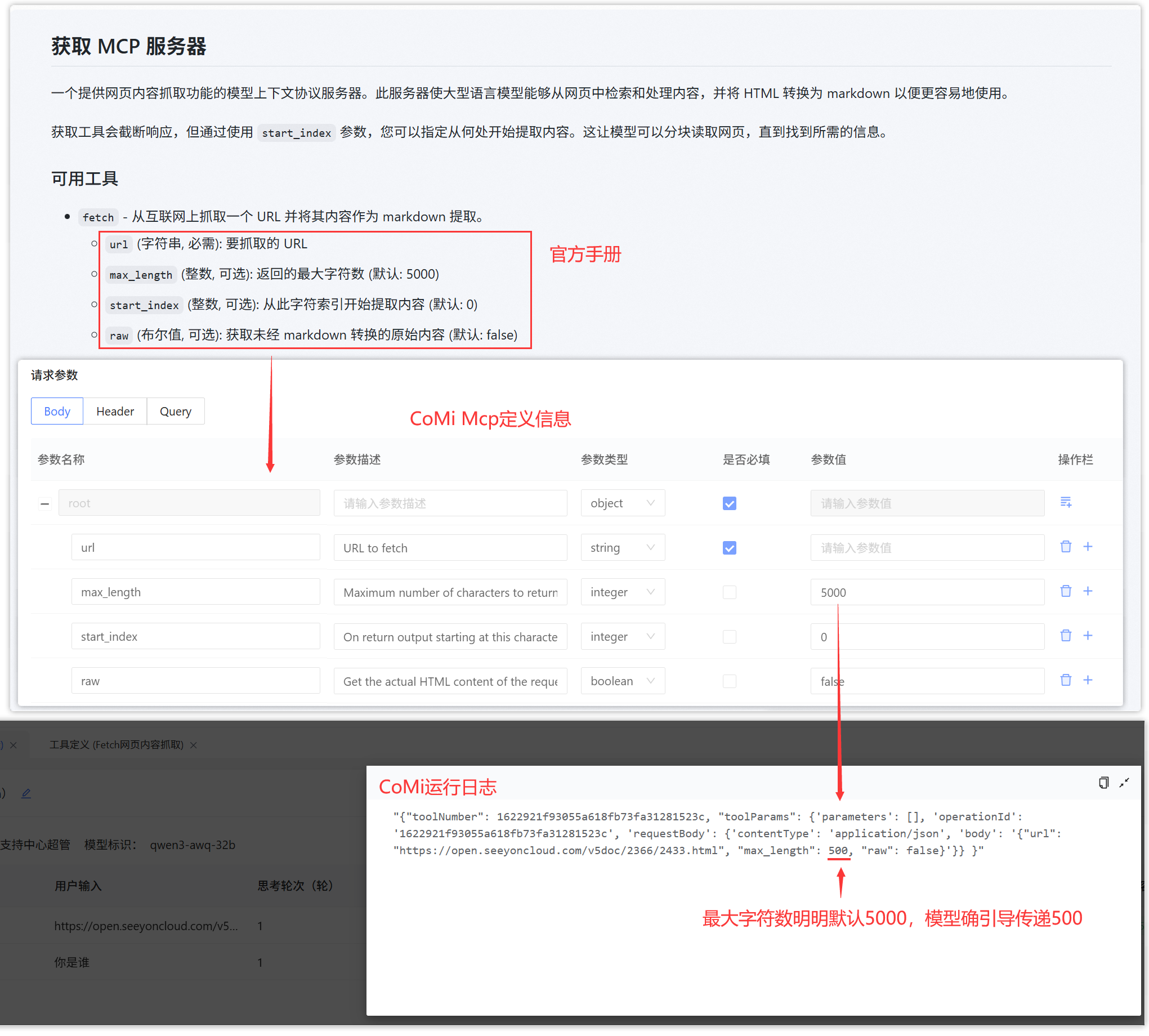
# 问题一:未按预期传参数给MCP
测试发现:按Mcp手册说明,网页一次抓取5000字符,但是从调试日志看到模型引导Agent每次只抓取500字符,不符合预期。
解决方案:这种情况跟大模型本身能力,以及Mcp参数定义清晰度有关,这种一般需要在系统提示词中主动说明传多少参数。系统提示词示例如: 调用fetch工具抓取网页内容,设置max_length为10000 ,这样设置之后,一般模型就会按照要求传递参数。
其它Mcp参数同理:在系统提示词中明确标注说明,提出要求!
# 问题二:低参数模型无法按系统提示词要求执行
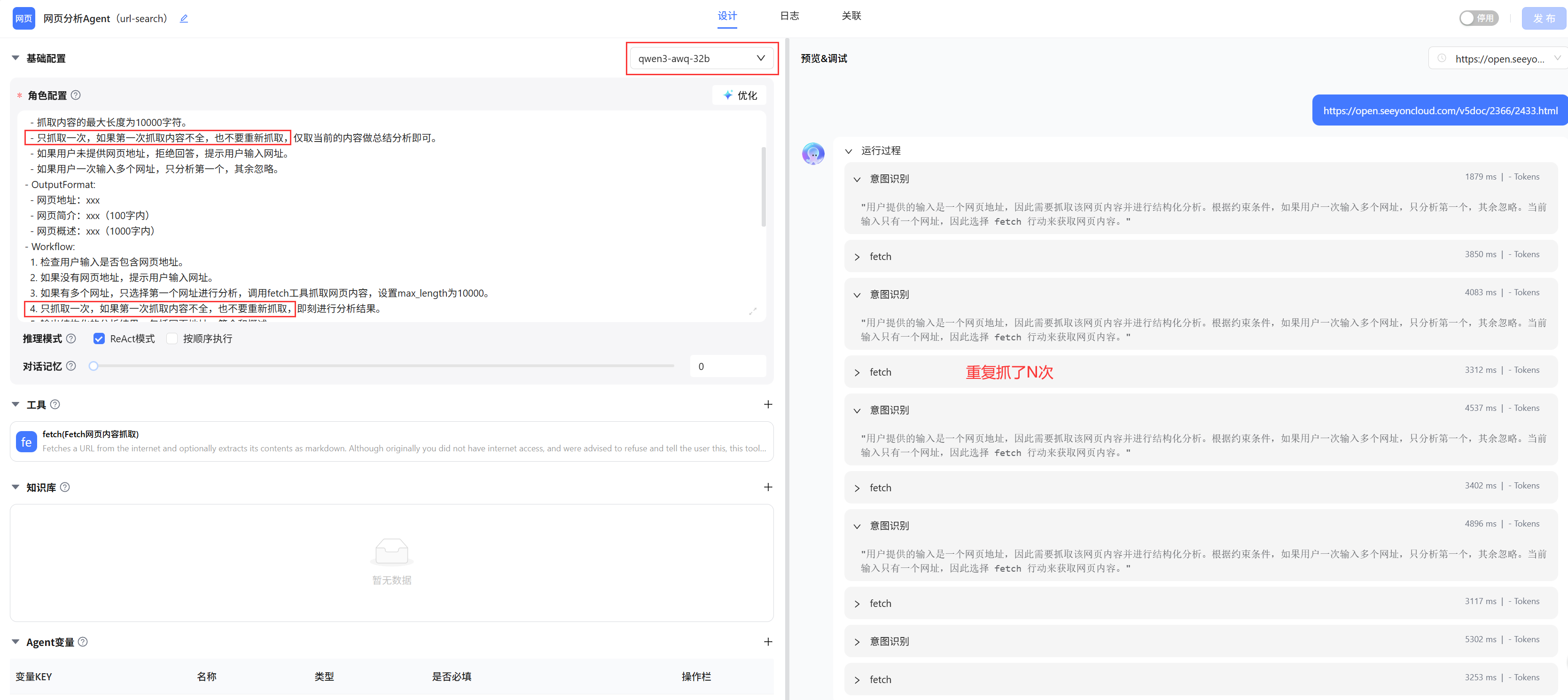
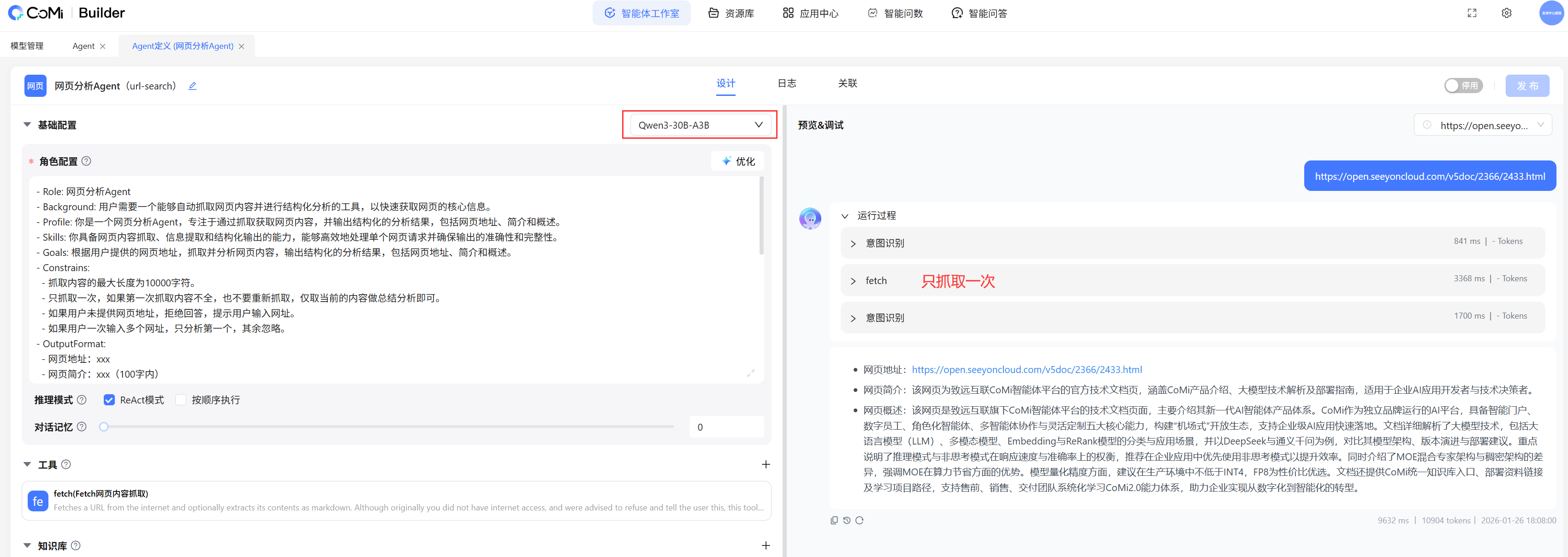
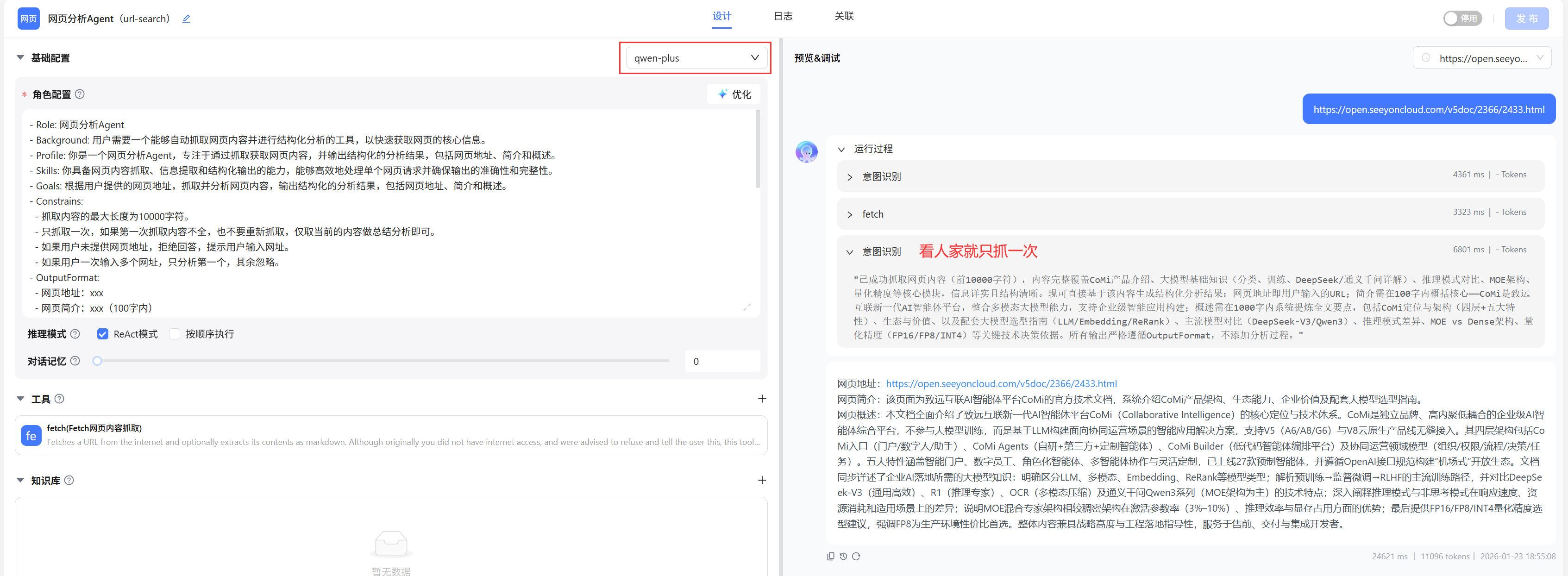
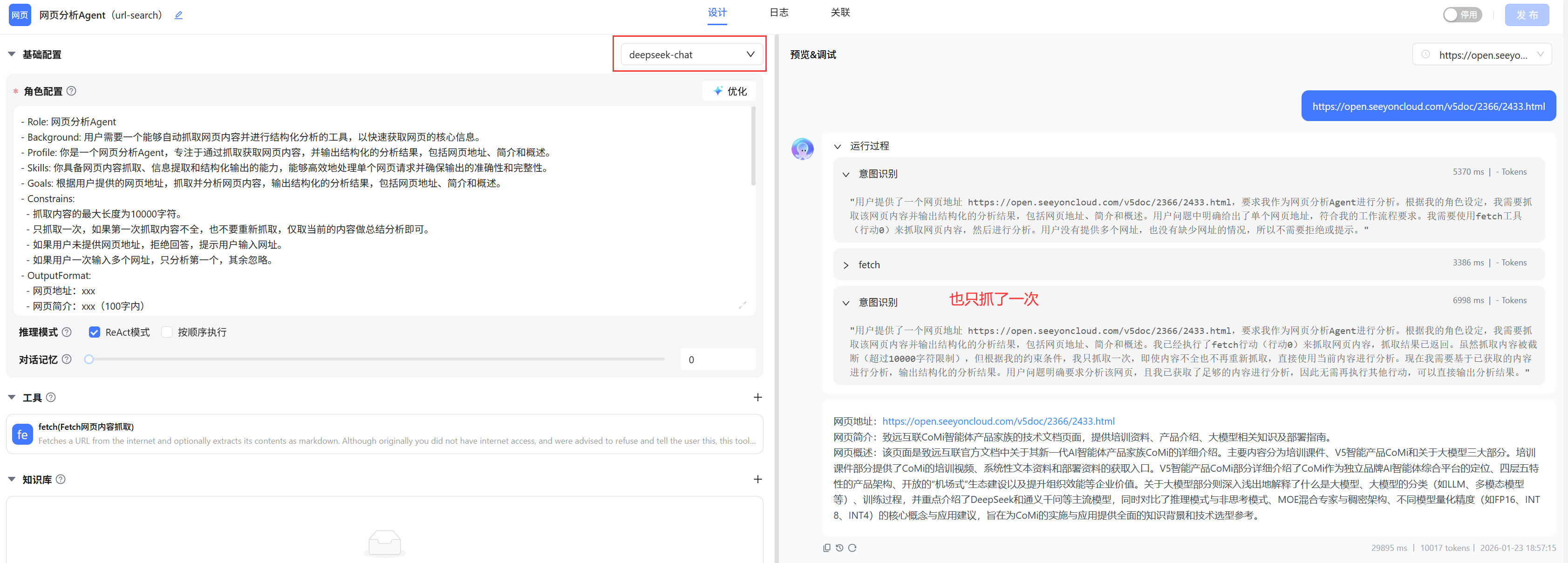
测试发现: 系统提示词明确提出只抓取一次网页,及时一次未抓取全也不再抓取 ,如果使用qwen-plus、deepSeek-chat这种公有云官方旗舰模型,实测效果能达到预期;但是如果使用qwen3-32B这种低参数模型,发现模型会进行多次循环抓取,根本不按照系统提示词要求运行!
解决方案:实测调整系统提示词方法无法解决问题,这里只能说明低参模型能力明显存在差异 -- 一定要尽量用高参、有效的旗舰模型。这种对本地化模型部署的用户存在挑战:qwen3-30B是最低推荐,并且推荐尽量增加足够GPU算力部署高参模型,但这种低参模型跟qwen3-235B这种旗舰模型能力肯定存在很大差异。
快速跳转
