# 系统监控分析
# 功能说明
系统监控特指V5产品线的系统监控页面,该页面提供了:产品运行时间、JVM运行状态、JDBC Dump、Thread Dump等信息。
系统监控能快速分析当前协同服务的运行状态,是日常运维最重要的监控手段之一。
具体位置:系统管理员后台 → 系统监控 菜单。
# 服务运行时长和在线人数
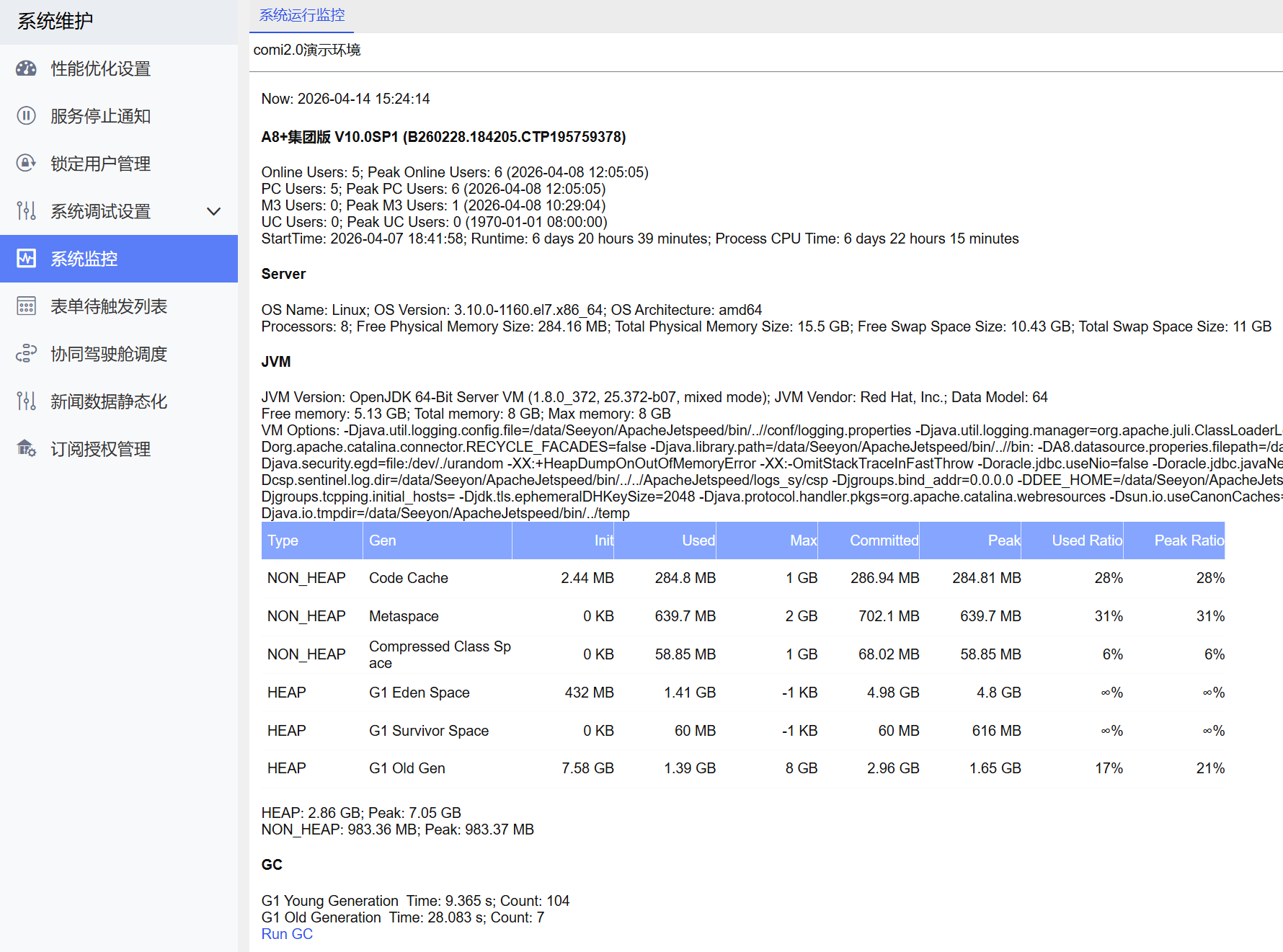
系统监控顶部提供了产品版本、在线人数、服务本次启动时间和运行时长:
- 具体的产品线、版本和BuildID,示例如
G6-N单组织版 V8.2 (B230831.000206.CTP96061989) - Online Users当前总在线人数
- Peak Online Users协同最近一次启动以来最高在线人数和时间点
- PC Users、M3 Users、UC Users分别对应PC浏览器、M3移动端、UC致信客户端的在线人数和峰值
- StartTime和Runtime分别对应本服务的最近一次启动时间 和 已经持续运行的时长

# 检查垃圾回收器G1GC
V5产品要求使用 G1GC 这种垃圾回收算法,G1对大内存、低延迟、高吞吐量的场景具备均衡且优秀的表现,通过系统监控能快速确认当前服务是否采用G1垃圾回收器。
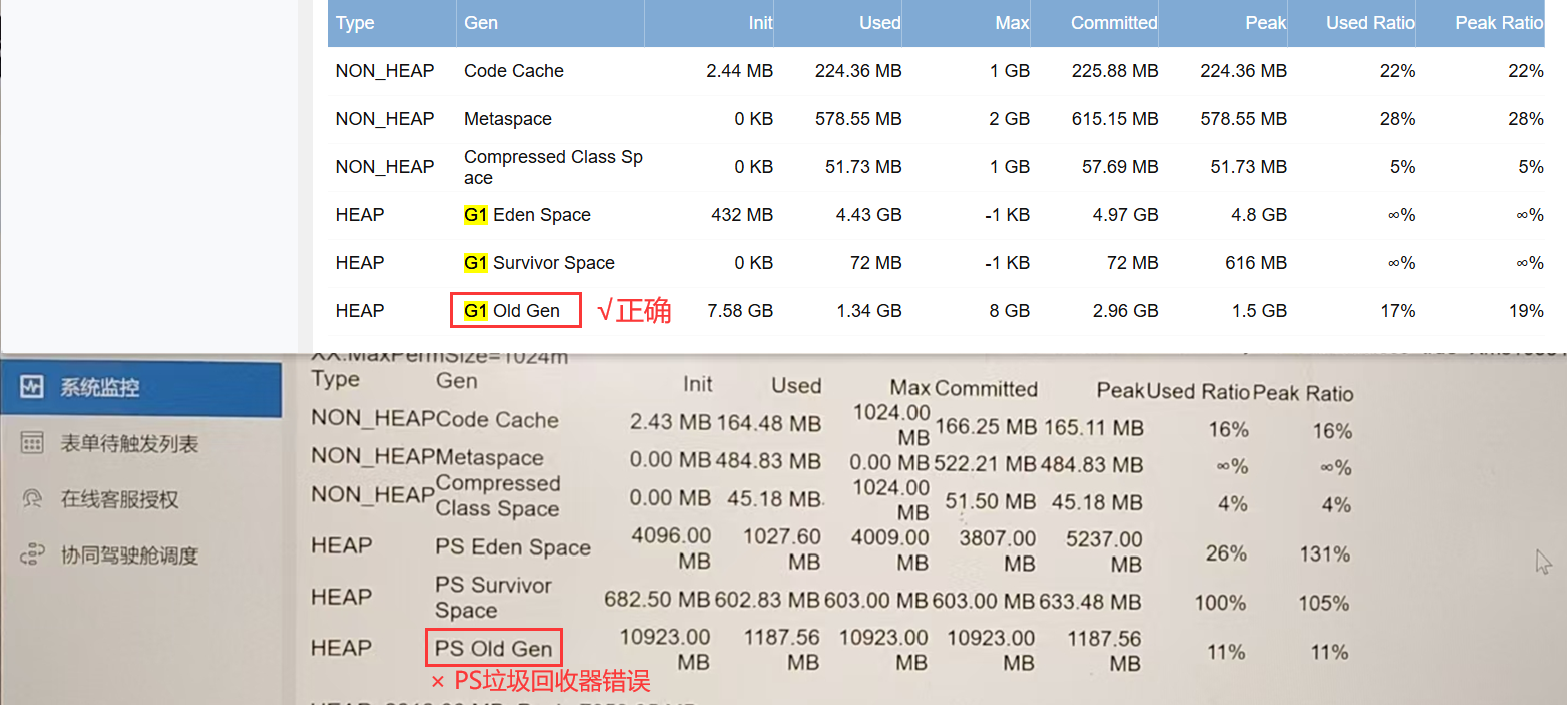
垃圾回收器检查方法: OA系统管理员后台 → 系统监控菜单 → JVM表格找到最后一行(Gen列):
- 如果是
G1开头,则说明配置正确! - 如果是别的,如
PS开头,则说明配置错误,需要修正!
非G1GC潜在风险: 如果使用JVM默认的Parallel Scavenge GC垃圾回收算法,可能会导致系统频繁full gc,用户感受为:系统突然卡一会儿,又恢复。
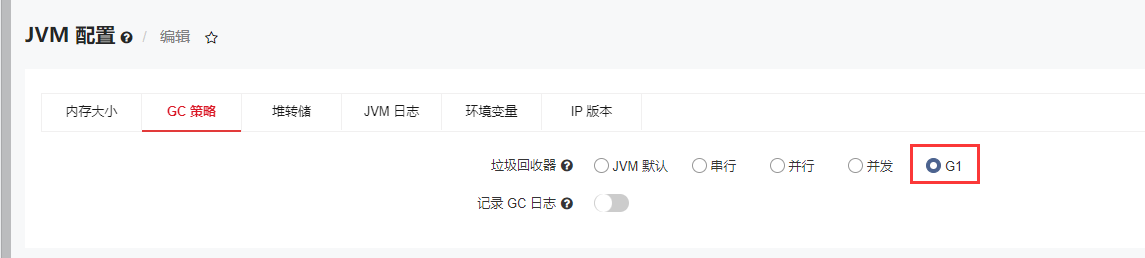
配置G1GC垃圾回收器方法:
- 如果是使用SeeyonInstall或XinChuang标准的安装程序,产品肯定是G1GC,这种不存在调整的情况
- 如果是中创、普元、华宇等非标中间件或者老版本手动信创部署的项目,则可能遇到没有配置G1GC垃圾回收算法的情况,需要参考信创部署手册或联系中间件厂商协助调整成G1GC!
另外一个少见的问题:信创中间件JVM配置了-XX:+UseG1GC但依然以PS垃圾回收器运行 https://open.seeyoncloud.com/#/faq/faq/v1/share?url=Z2JySmU+OjY4Og==
# JVM 内存使用情况分析
系统监控页面中的 JVM 表格 展示了当前 Java 进程的内存使用情况,是判断系统是否存在内存压力的重要依据。
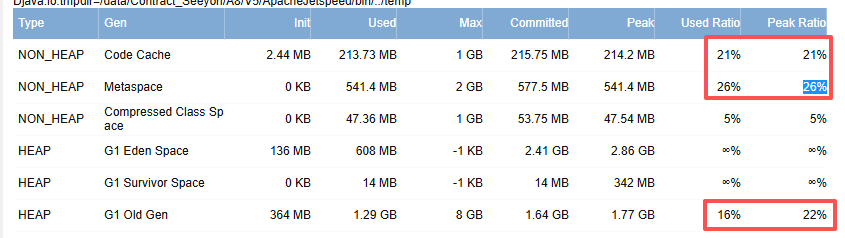
主要关注以下几项:
# Heap(堆内存)
通过 -Xms(初始堆内存)、-Xmx(最大堆内存) 设置堆内存大小
Heap 是系统最核心的内存区域,所有业务对象均在此分配。
- G1 Eden Space(新生代)
- G1 Survivor Space
- G1 Old Gen(老年代)
重点关注 G1 Old Gen(老年代):
- Used Ratio:使用比例
- Peak Ratio:峰值使用比例
判断标准
✅ 正常情况:Used Ratio 长期保持在 40%~70% (过低浪费资源)
⚠ 风险情况:Used Ratio 长期 80%左右;Peak Ratio 超过80%说明历史有冲高现象
❗ 危险情况:接近 100%,且频繁 Full GC
# Non-Heap(非堆内存)
- Metaspace(类元数据)
- Code Cache(JIT 编译代码缓存)
- Compressed Class Space
重点关注 Metaspace、Code Cache:
- Used Ratio:使用比例
- Peak Ratio:峰值使用比例
✅ 正常情况:Used Ratio 长期保持在 40%~70% (过低浪费资源)
通过以下JVM参数设置大小:
-XX:ReservedCodeCacheSize=1024m
-XX:MaxMetaspaceSize=2048m
-XX:MetaspaceSize=2048m
# 运行模式
系统监控页面的 Mode 区域展示OA服务的运行模式

生产环境要求使用 product 模式运行服务
# 数据库连接池(Connection Pooling)
系统监控页面的 Connection Pooling 区域展示数据库连接使用情况。
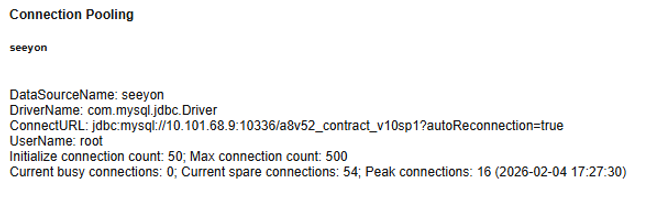
重点字段:
- Max connection count(最大连接数)
- Current busy connections(当前活跃连接数)
- Peak connections(峰值连接数)
判断标准
✅ 正常:当前连接数 < 最大连接数 70%
⚠ 风险:长期接近最大连接数
❗ 危险:达到最大连接数
用户报错:数据库连接耗尽
常见问题:连接数满
原因:
慢 SQL 未关闭连接 大批量操作 死锁
建议:
分析数据库慢日志 检查是否存在长事务 查看 JDBC Dump
# 线程监控(Thread)
系统监控页面提供线程统计信息:
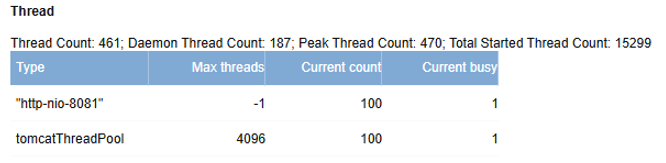
- Thread Count
- Daemon Thread Count
- Peak Thread Count
重点关注 Thread Count 正常:随业务波动 异常:持续增长不下降(可能线程泄漏)
重点关注线程池 http-nio-xxx(这里是http-nio-8081):
- Max threads
- Current count
- Current busy
判断标准
✅ 正常:busy 线程远低于最大线程数
⚠ 风险:busy 100~500 建议引起重视
线程耗尽表现
- 页面一直转圈
- 接口超时
- 系统假死
建议:
导出 Thread Dump 分析是否大量 WAITING / BLOCKED 排查是否数据库阻塞
# 特殊情况
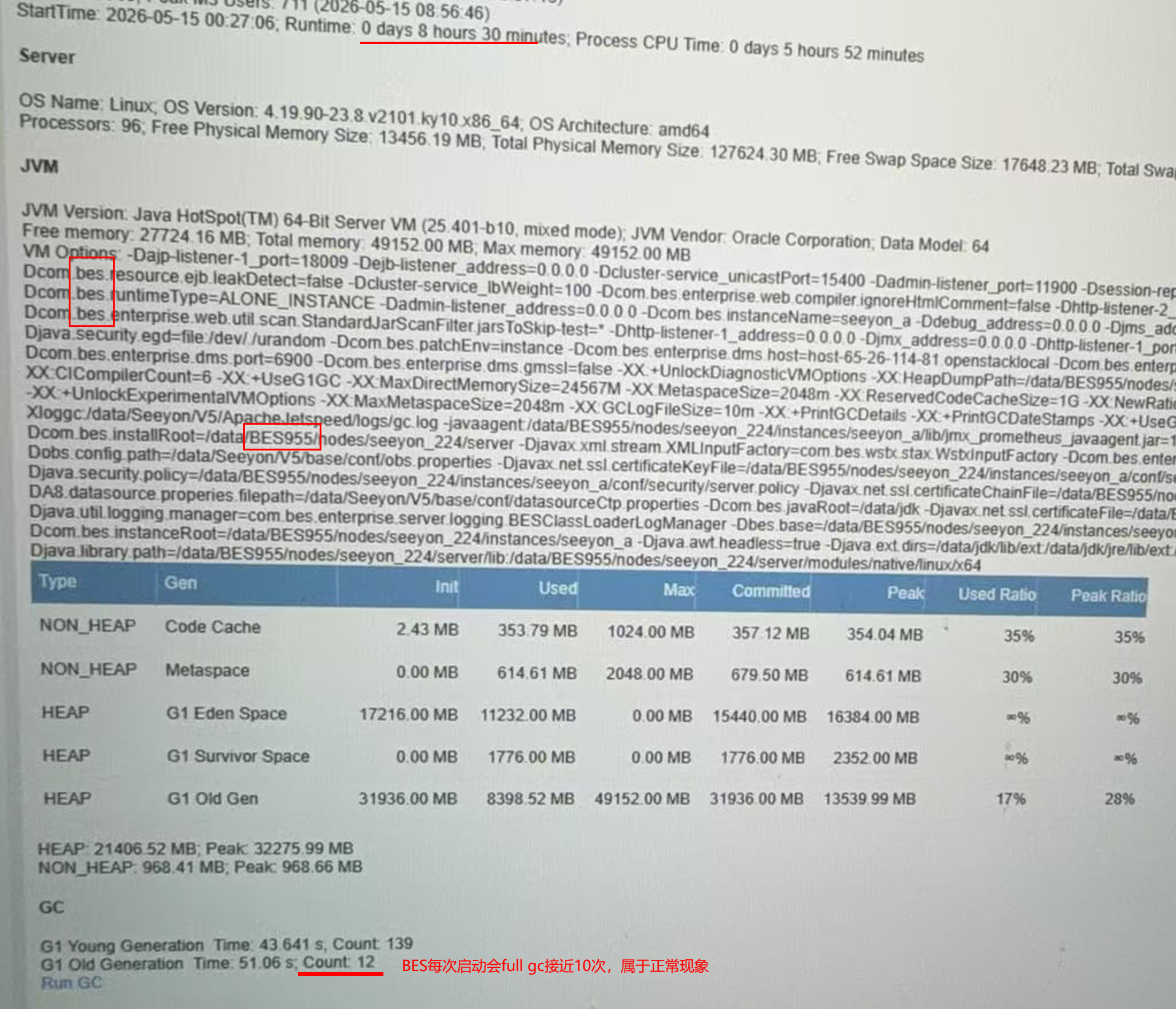
宝蓝德每次启动会进行数10次的full gc属于正常现象,后续持续观察每天不超过1次就OK:
快速跳转
← AI搜索方法指引 OA服务启动卡住分析 →
