# 全文检索部署维护手册V9.0SP1版本
北京致远互联软件股份有限公司 2025年4月
# 前言
本手册对全文检索独立服务的安装及维护相关事宜进行说明。
如对安装维护手册中相关问题存在疑问,请与致远互联的客户服务人员联系。
| 维度 | 支持范围 |
|---|---|
| 当前服务名称 | 全文检索服务 |
| 适用服务器环境 | Windows Server、Linux、信创操作系统 |
| 所需依赖 | 需要提前部署协同管理服务 |
# 修订记录
| 修订内容 | 修订时间 |
|---|---|
| 重新梳理全文检索单机部署手册章节及内容,确保结构易读、易懂 | 2025-4-11 |
# 环境准备
# 概要说明
- 取协同版本一致的全文检索安装程序部署;
- 使用全文检索必须部署独立的全文检索服务;
- 全文检索服务支持单机和集群两种部署方式
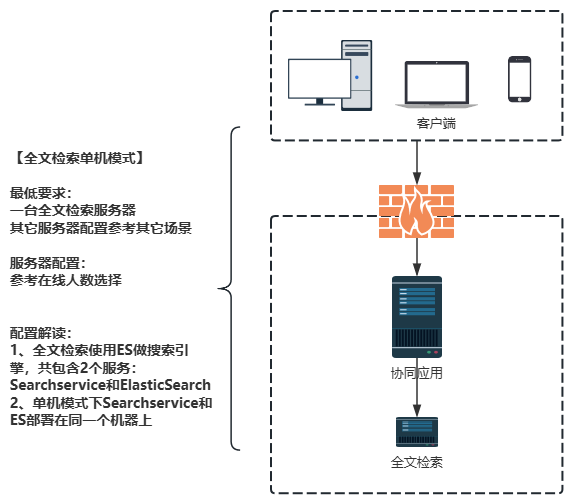
# 全文检索单机模式
- 资源成本需求低,只需要一台服务器
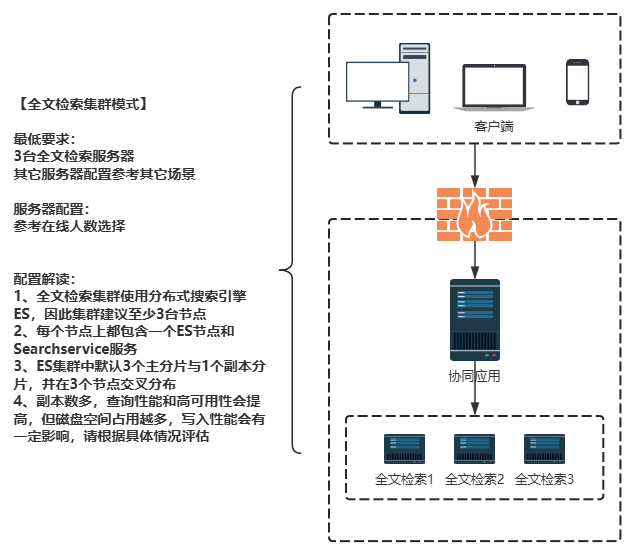
# 全文检索集群模式
- 满足高性能、具备高可用的要求,至少需要3台服务器
# 端口互通要求
如下是全文检索服务对外用到的默认端口:
| 端口服务 | http默认端口 | 端口互通要求 |
|---|---|---|
| 全文检索客户端连接端口 | 9700 | 需要被协同服务访问(协同==>>>全文检索:9700) |
| 全文检索ActiveMQ 消息队列服务 | 16161 | 需要被协同服务访问(协同==>>>全文检索:16161) |
| 全文检索ActiveMQ RMI 通信 | 1099 | 检索服务器其它应用不要占用此端口 |
| 全文检索Elasticsearch 数据交互 | 9200、9300 | 全文检索集群节点1<<<==>>>节点2<<<==>>>节点3<<<==>>>节点1 |
| 协同服务应用端口 | 80 | 全文检索==>>>http://协同服务 |
# 服务器配置参考
| 在线用户数 | 微服务名称 | 非信创单节点配置推荐 | 信创单节点配置推荐 |
|---|---|---|---|
| 200以下 | 全文检索 | CPU8核以上/内存16G以上/硬盘320G | CPU12核以上/内存20G以上/硬盘320G |
| 200~500 | 全文检索 | CPU8核以上/内存16G以上/硬盘320G | CPU12核以上/内存20G以上/硬盘320G |
| 500~1000 | 全文检索 | CPU8核以上/内存16G以上/硬盘320G | CPU12核以上/内存20G以上/硬盘320G |
| 1000~3000 | 全文检索 | CPU16核以上/内存24G以上/硬盘320G | CPU20核以上/内存32G以上/硬盘320G |
| 3000~5000 | 全文检索 | CPU16核以上/内存32G以上/硬盘320G | CPU20核以上/内存48G以上/硬盘320G |
| 5000~10000 | 全文检索(建议集群) | CPU16核以上/内存32G以上/硬盘320G | CPU20核以上/内存48G以上/硬盘320G |
注意:
- 全文检索集群节点需要3台,每台节点服务器的配置推荐单机的2/3资源
- 硬盘使用场景:在进行重建索引时,解析upload附件到检索服务器上,7天清理,此时会占用磁盘空间
# 操作系统相关准备
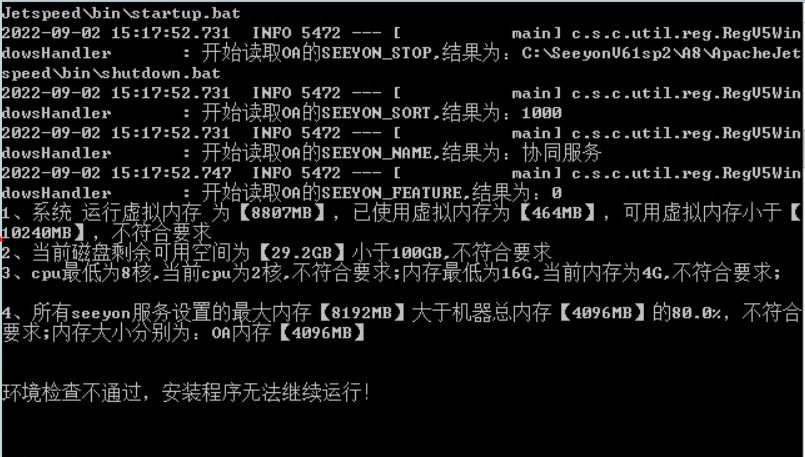
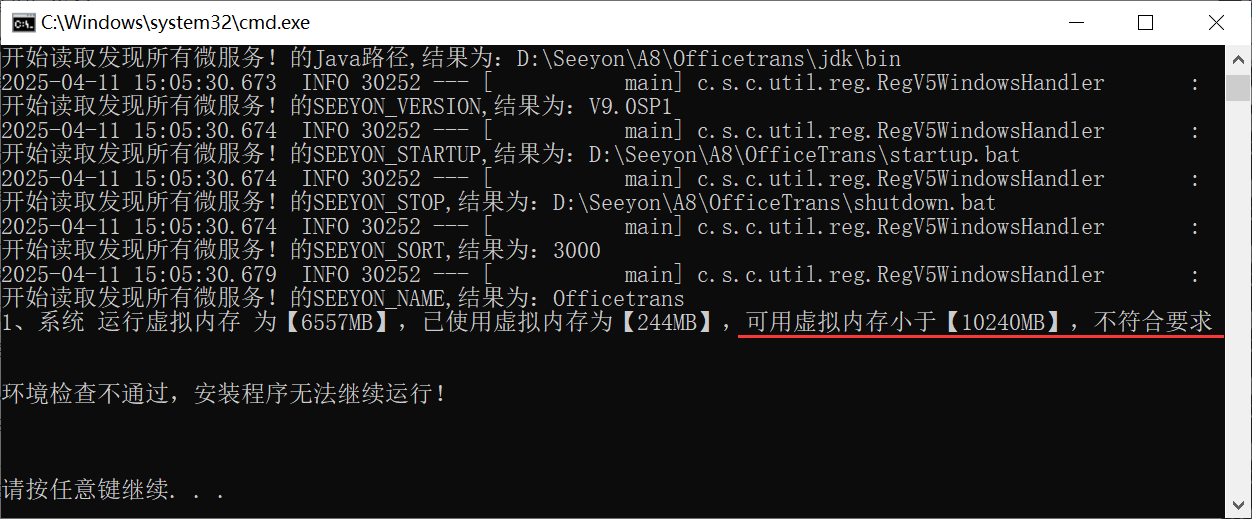
启动安装程序之前环境检查项: 在进行安装升级前,确保服务器环境配置符合要求,如不符合,安装程序无法继续运行。
1、检查当前是否为支持的操作系统类型
2、检查是否64位
3、检查cpu内存是否达到最低配置要求8c16g
4、检查虚拟内存是否不低于10240M
5、检查磁盘可用空间是否不低于100G
6、检查网卡速率是否符合基线要求1000M
7、已部署各项服务内存之和,加上即将安装的产品内存配置(默认4G)不得超过物理内存80%
8、当前服务器可用内存不得低于物理内存60%
9、Linux系统,ulimit -a检查open files和max user processes都不得低于60000
如当前系统配置较低,程序仅用作个人或演示使用,可酌情修改按照程序SeeyonInstall/inst/check.yml配置文件,降低环境检查基线
# Linux/信创操作系统初始准备
如全文检索采用Linux/信创操作系统部署,需要做如下初始准备:
安装基本的命令组件:
安装部署前,先确保当前系统已经安装了最基础的命令,(能连接互联网服务器)可执行如下语句做预装:
如服务器无法连接互联网,请要求操作系统厂商预装必要的命令组件
# Red Hat系列(如CentOS),使用yum命令安装,如当前系统提示yum不可用,则尝试使用apt
sudo yum update -y
sudo yum install tar curl telnet vim unzip -y
# 基于Debian的系统(如Ubuntu)使用apt预装组件
sudo apt update -y
sudo apt upgrade -y
sudo apt install tar curl telnet vim unzip -y
# 基于欧拉openEuler、龙蜥Anolis OS等系统使用dnf安装
sudo dnf update -y
sudo dnf install tar curl telnet vim unzip -y
安装图形命令组件:
确保当前系统安装了必要的字体、图形组件,否则会影响后续程序使用:
# Red Hat系列(如CentOS),使用yum命令安装,如当前系统提示yum不可用,则尝试使用apt
sudo yum install freetype libX11 libXrender libXtst libXi fontconfig -y
# 基于Debian的系统(如Ubuntu)使用apt预装组件
sudo apt install libfreetype6 libx11-6 libxrender1 libxtst6 libxi6 fonts-config -y
# 基于欧拉openEuler、龙蜥Anolis OS等系统使用dnf安装
sudo dnf install freetype libX11 libXrender libXtst libXi fontconfig -y
在进行安装部署前,先按照如下配置优化Linux相关系统参数:
修改Linux网络参数:
1、通过 vim /etc/sysctl.conf 命令在文件末尾添加:
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 1800
net.ipv4.tcp_window_scaling = 0
net.ipv4.tcp_sack = 0
net.ipv4.tcp_timestamps = 0
# 非常关键:命令调整可创建的最大虚拟内存区域的数量
vm.max_map_count=262144
2、然后执行命令重启网络服务:
service network restart
# 如上一条命令不可用,可能是不同Linux发行版差异,尝试换一个命令重启
systemctl restart NetworkManager
3、通过 vim /etc/rc.d/rc.local 命令在文件末尾添加:
echo "30">/proc/sys/net/ipv4/tcp_fin_timeout
echo "1800">/proc/sys/net/ipv4/tcp_keepalive_time
echo "0">/proc/sys/net/ipv4/tcp_window_scaling
echo "0">/proc/sys/net/ipv4/tcp_sack
echo "0">/proc/sys/net/ipv4/tcp_timestamps
修改Linux最大进程数最大文件打开数:
通过 vim /etc/security/limits.conf 命令编辑此文件添加以下内容
# open files (-n)
* soft nofile 65535
* hard nofile 65535
# max user processes (-u)
* soft nproc 65535
* hard nproc 65535
以上配置完成后,执行reboot重启操作系统,随后通过 ulimit -a 命令检查open files和max user processes是否都变成65535,如未生效,则将*改成root,再次重启测试是否生效:
# 如果调整配置并且重启操作系统之后以上配置未生效,当前是root设置,则将*改成root即可生效
root soft nofile 65535
root hard nofile 65535
root soft nproc 65535
root hard nproc 65535
禁用swap:
swapoff -a
# 全文检索单机部署X86
# X86安装程序准备
X86环境(Windows或Linux)从商务公布的对应版本安装程序下载地址下载名为“IndependentService.zip”的文件,此文件是X86环境扩展服务安装程序。
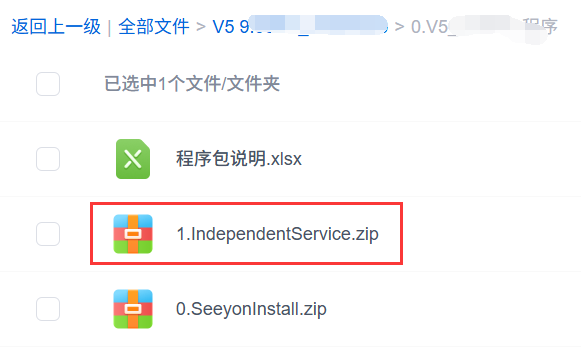
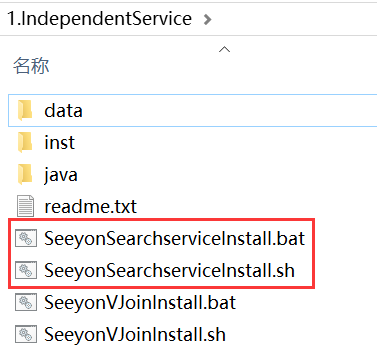
服务器直接解压IndependentService.zip,解压后的目录中“SeeyonSearchserviceInstall”就是全文检索安装程序
- SeeyonSearchserviceInstall.bat适用于Windows服务器安装全文检索
- SeeyonSearchserviceInstall.sh适用于Linux服务器安装全文检索
如全文检索在Linux服务器安装,则将IndependentService.zip上传到服务器,再进行解压,解压后对整个目录赋予可执行权限:
mkdir /data
# 解压安装程序
unzip 1.IndependentService -d /data
# 对扩展服务安装目录赋予可执行权限
chmod -R 777 /data/1.IndependentService
# 查看解压后的程序目录
cd /data/1.IndependentService/
ls
如全文检索在Windows服务器安装,建议服务器杀毒软件将安装程序设置为信任目录,避免安装部署时误报。
如全文检索在Linux下部署,必须参考【Linux操作系统初始准备】章节对所有全文检索服务器参数进行调优,以获得更好的性能。
# X86单机安装部署步骤
第一步,启动全文检索安装程序:
- Windows服务器直接双击运行SeeyonSearchserviceInstall.bat
- Linux服务器,使用命令启动运行SeeyonSearchserviceInstall.sh
程序启动第一步会进行环境校验,当前服务器环境不满足安装要求会拒绝安装,先将不通过项进行调整后再继续,详细检查项见【启动安装程序之前环境检查项】章节说明。
第二步,阅读许可协议,无异议选择“接受”并“下一步”
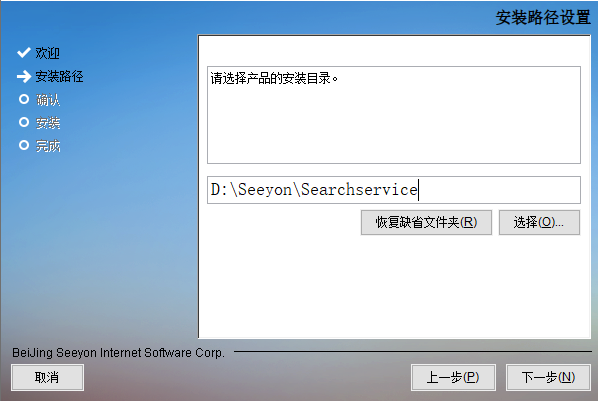
第三步,选择产品的安装目录,选择“下一步”
- Windows系统下安装目录建议更改到非系统盘符
- Linux建议安装在空间较大的盘符下,比如安装在
/data/Seeyon/Searchservice,不能部署于/root或者其子目录下(影响全文检索服务启动)
第四步,依次点击下一步,直至完成安装:
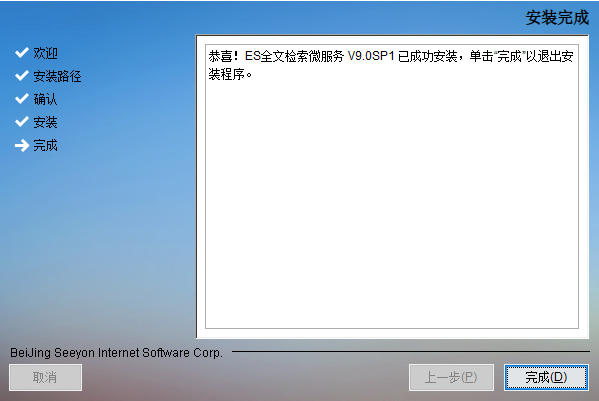
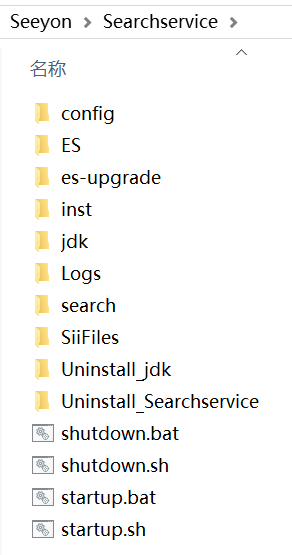
第五步,安装完成后,找到全文检索程序目录,Windows和Linux正常情况都包含如下文件,如检查文件无误,则确定部署完成:
# 全文检索单机部署(信创)
# 信创安装程序准备
信创环境从商务公布的对应版本安装程序下载地址下载名为“XinChuang.zip”的文件,此文件是信创环境相关服务安装程序。

将XinChuang.zip上传到信创系统,并解压XinChuang包,解压后,Search目录就是全文检索的程序根目录:
unzip 2.V9.0SP1_XinChuang.zip

Search全文检索程序免安装,建议解压后放置到规划的目录方便管理,比如参考X86统一放置到/data/Seeyon目录:
mkdir -p /data/Seeyon
# 全文检索程序迁移到规划好的目录
mv Search /data/Seeyon/

准备JDK:Search全文检索免安装版本不带JDK,需要自行准备。将JDK8上传到自定义路径,比如/usr/local/jdk,随后修改Search/config/jvm.properties文件中的search_java参数,设置成JDK下的bin/java运行路径:
cd /data/Seeyon/Search/config
vim jvm.properties
注意路径地址不是指向jdk,而是指向jdk下的bin/java可执行文件的路径:

以上完成后,信创免安装版本就准备完成,下一步就是进行配置。
# 全文检索单机配置运维
无论是X86还是信创系统,无论是图形化安装还是免安装程序,配置步骤均一样,参考本章节操作。
# 单机配置步骤
在全文检索单机已经安装完成前提下,进行协同与全文检索的配置:
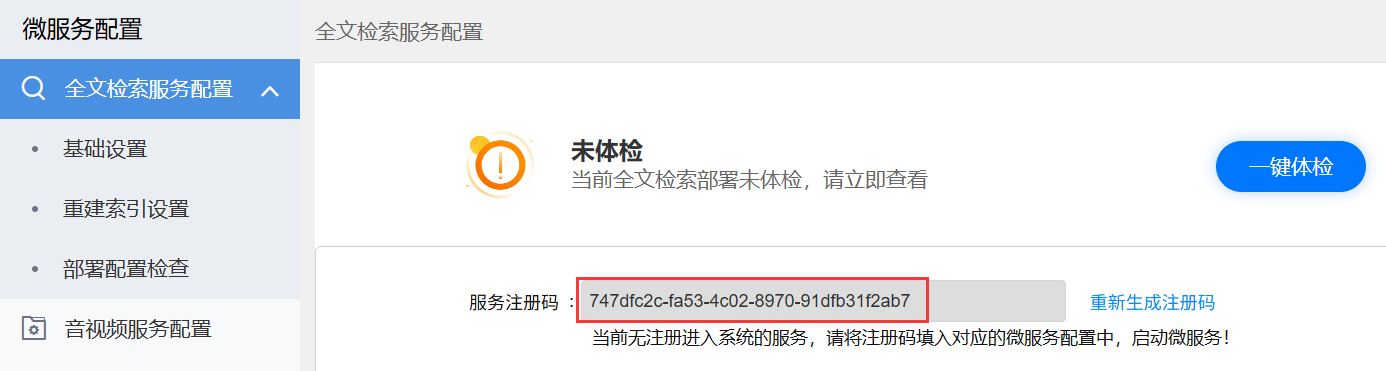
第一步,登录协同获取服务注册码:确保协同服务启动,登录协同系统管理员后台,进入"全文检索服务配置"界面,查看并记录服务注册码:
第二步,全文检索配置注册码。
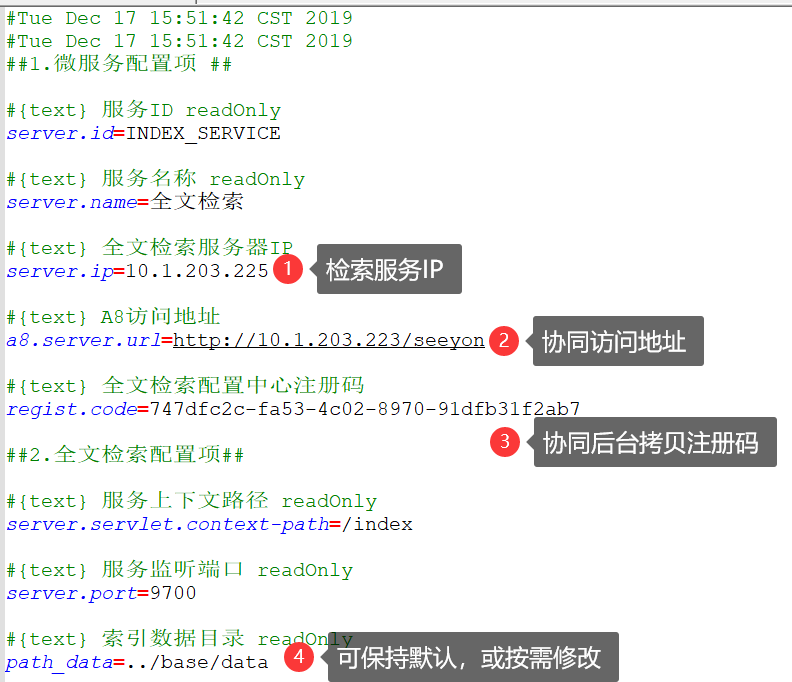
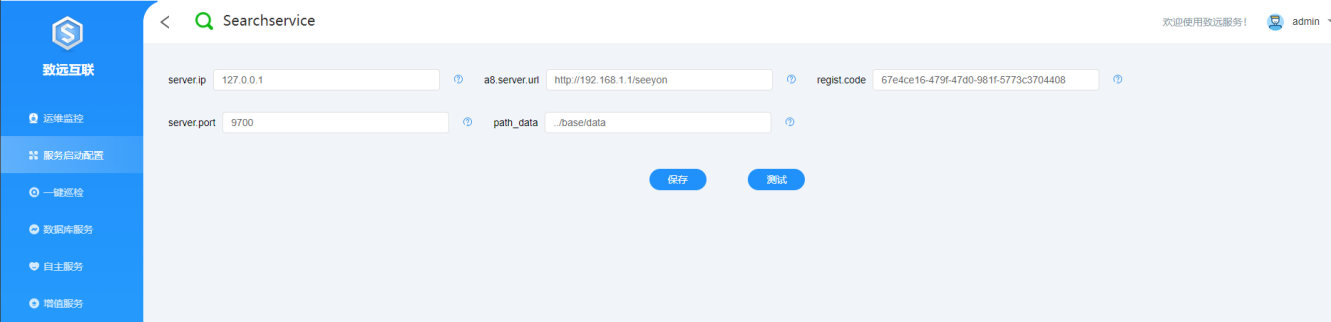
若未安装S1,需要手工进行注册码配置:将注册码配置在全文检索服务程序目录Searchservice/config/application.properties文件中,并调整其他配置参数:
server.ip:全文检索服务器的 ip地址,分离部署需要设置实际ip,如10.5.5.160
a8.server.url:协同服务的访问地址,注意带应用上下文/seeyon,需要确保全文检索服务器能访问到协同服务(协同集群则是负载地址)
regsit.code: 注册码,需要与系统管理员账号中的服务注册码保持一致,将第一步服务注册码拷贝到此处
server.port:全文检索服务的端口,默认9700, 全文检索服务9700端口必须让协同应用服务器可以访问
path_data:索引数据目录,默认是../base/data(即Searchservice/ES/base/data),如需修改需要设置绝对路径(不建议放在挂载盘上)
Windows系统通过文本工具修改保存,Linux系统可通过
vim修改保存。
若已安装S1,可在S1的"服务启停配置"中,进行全文检索配置:
server.ip:全文检索服务器的 ip地址,分离部署需要设置实际ip,如10.5.5.160
a8.server.url:协同服务的访问地址,注意带应用上下文/seeyon, 需要确保全文检索服务器能访问到协同服务
regsit.code: 注册码,需要与系统管理员账号中的服务注册码保持一致,将第一步服务注册码拷贝到此处
server.port:全文检索服务的端口,默认9700, 全文检索服务9700端口必须让协同应用服务器可以访问
path_data:索引数据目录,默认是../base/data(即Searchservice/ES/base/data),如需修改需要设置绝对路径(不建议放在挂载盘上)
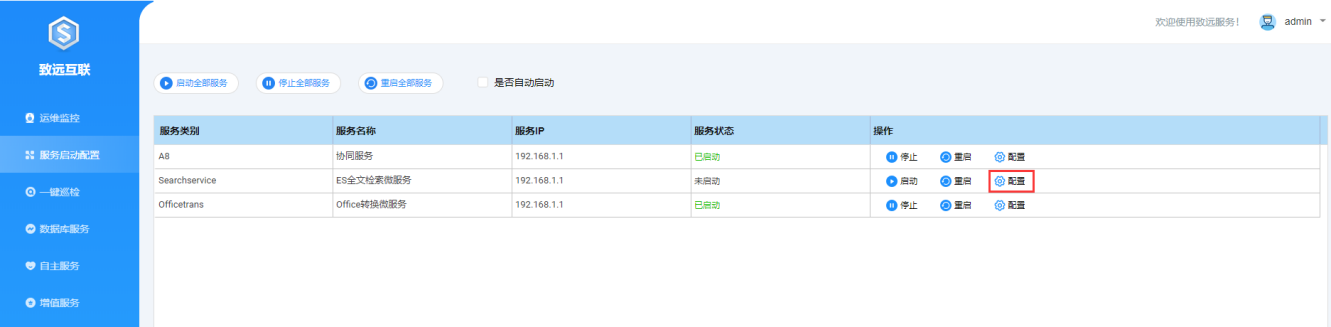
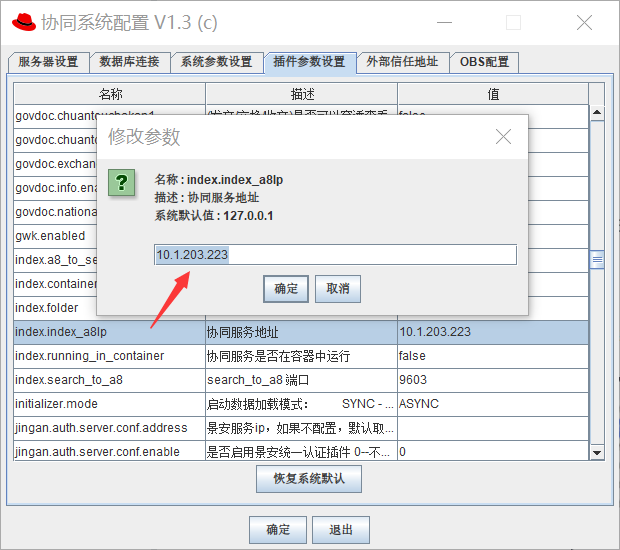
第三步:协同服务器配置全文检索信息
协同服务器运行SeeyonConfig,在协同系统参数设置中需要把index.index_a8Ip设置成当前协同服务器实际IP。
如果没有图形化窗口,在协同程序目录/base/conf/plugin.properties文件中单独增加一行配置:
# 10.1.203.223填写客户环境协同服务器真实IP
index.index_a8Ip = 10.1.203.223
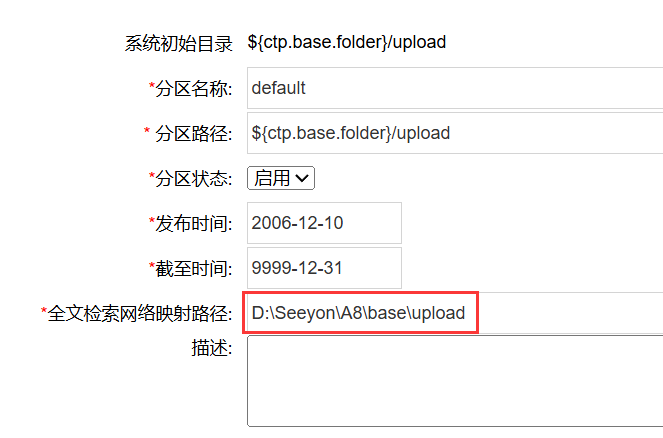
第四步:SeeyonConfig调整配置后需要重启协同服务。重启后,登录协同系统管理员后台,进入系统分区设置,修改所有分区,配置“全文检索网络映射路径”:此路径即协同附件目录地址,需要确保全文检索服务器能访问到协同附件所有分区目录!
如协同服务与全文检索服务部署在同一台服务器 ,并且附件默认存放在 协同程序目录\base\upload 下,则全文见检索网络映射路径直接指向附件绝对路径:
如协同服务与全文检索服务采用分离部署(不是同一服务器) ,并且附件默认存放在 协同程序目录\base\upload 下,则需要在协同附件目录下进行目录共享配置,确保全文检索能读取到协同的upload。Linux系统采用NFS协议挂载、Windows采用共享文件夹+SMB 协议挂载。
其它场景,如协同服务集群部署,附件必然会采用共享存储模式方便每台协同能访问,此时也需要给全文检索服务器开通共享存储访问权限。
Linux系统采用NFS协议挂载、Windows采用共享文件夹+SMB 协议挂载,具体可由客户IT进行配置。如需个人参照配置,可参考协同集群部署手册,本手册不赘述。
# 单机检索服务启停
启动前注意事项:
1、需要先确保协同服务处于运行状态,再启动全文检索服务,启动检索服务时会向协同服务发送请求
2、全文检索服务启动时,默认需要占用 9700、16161、1099、9200、9300 端口,确保这些端口未被其它服务进程占用,如需调整端口,请在全文检索服务配置文件config/application.properties 中配置为其他可用的端口。
3、全文检索服务和协同服务有端口互通要求,详细见 【默认端口互通】 章节,如未开通端口访问权限,会导致全文检索不可用。
启动方法一: 可以使用S1启动全文检索服务
启动方法二: 可以使用全文检索程序目录Searchservice/startup脚本启动
- Windows系统鼠标右键“以管理员身份运行”startup.bat启动,启动窗口不要关闭
- Linux系统运行
./startup.sh命令启动
cd 全文检索程序目录Searchservice/startup
./startup.sh
启动后,注意进程是两个,一个elasticsearch进程、一个searchservice微服务进程:
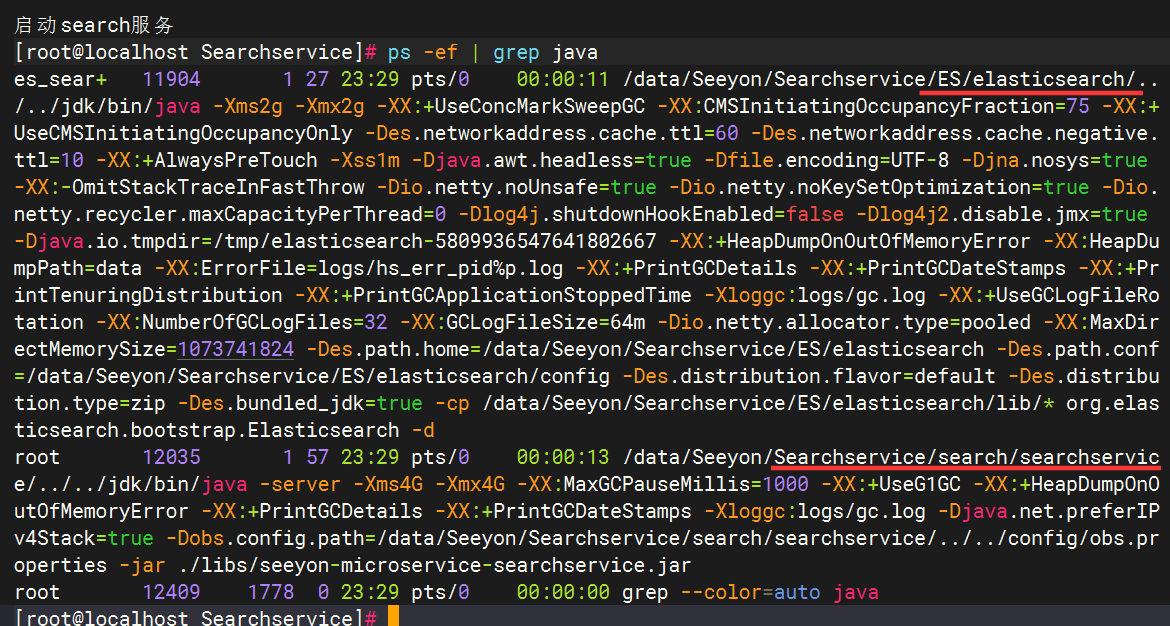
启动后验证: 登录协同系统管理员后台,进入"全文检索服务配置"界面,确保一键体检通过以及server.ip信息都已经打印在页面中:
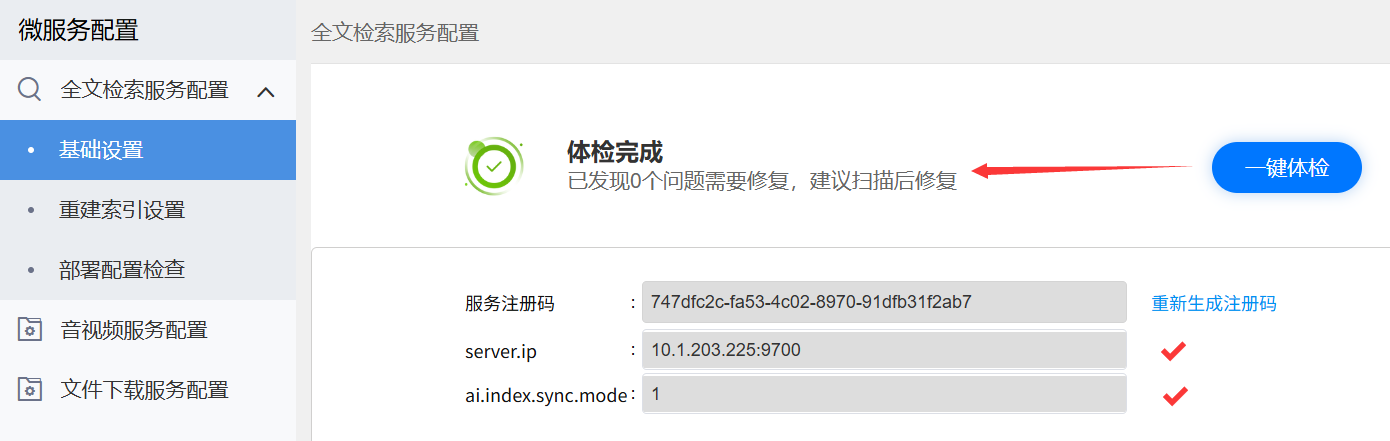
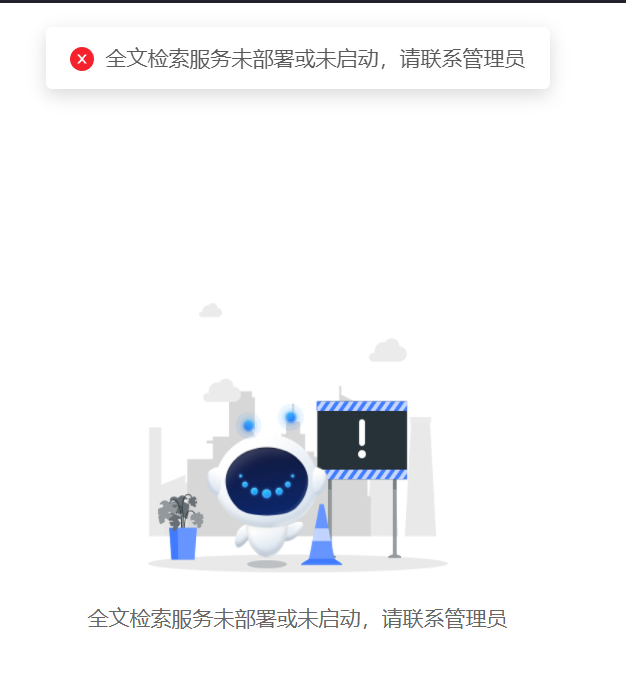
如启动后访问协同系统管理员后台一键体检提示:全文检索服务未部署或未启动。需要分析两个问题:
- 1、全文检索服务是否启动:确保两个进程都需要存在,一个elasticsearch进程、一个searchservice微服务进程
- 2、全文检索端口是否开放: 参考【默认端口互通】 章节,防火墙放行对应端口,确保协同能访问到全文检索
- 3、需要确保协同处于可登录访问状态后,再启动全文检索,否则也会报服务未部署或未启动的错误

停止方法一: 可以使用S1停止全文检索服务
停止方法二: 可以使用全文检索程序目录Searchservice/shutdown脚本停止
- Windows系统鼠标右键“以管理员身份运行”shutdown.bat停止,关闭ES程序窗口
- Linux系统运行
./shutdown.sh命令停止
cd 全文检索程序目录Searchservice/startup
./shutdown.sh
专用机启动方法:
先启动ES服务:使用普通用户,执行
ES/elasticsearch/bin/目录下的./elasticsearch -d命令再启动SearchService服务:使用root用户,执行
search/searchservice目录下的./startup.sh命令
# 单机JVM配置调优
如需提高全文检索服务的堆内存资源,可修改全文检索程序根目录\config\jvm.properties文件,只修改文件中的-Xms和-Xmx参数(数值保持一样),修改后重新启动全文检索。比如将内存改成8G,就改如下参数即可(其余参数不要动,也不要删):
-Xms8G -Xmx8G
注意:
- 此堆内存修改对searchservice微服务有效
- 以上堆内存占用不能大于当前服务器总内存的75%。
附录:全文检索宕机案例 https://open.seeyoncloud.com/#/faq/faq/v1/share?url=Z2JySmU+MjExOQ==
2、如需修改elasticsearch的堆内存资源,可修改ES\elasticsearch\config\jvm.options文件,注意ES的堆内存和Searchservice微服务的堆内存总和不能大于当前服务器总内存的75%。
# 单机日志分析
全文检索如出现异常,单机环境下重点分析如下日志:
- 协同服务器,全文检索日志:ApacheJetspeed\logs_sy\index.log
- 全文检索服务器,Search微服务日志:\Searchservice\search\searchservice\logs\index.log
- 全文检索服务器,ES日志:\Searchservice\ES\elasticsearch\logs\elasticsearch.log
# 索引升级工具
全文检索提供了索引升级工具,如客户是从V8.1SP2及更早版本升级到当前版本,必须使用工具进行索引全面升级,工具位于全文检索程序目录下的 es-upgrade 文件夹。
全文检索8.2版本针对检索匹配效果做了优化,如果不需要使用下面图示新特性的情况下,不需要执行本章节索引重建操作:
# 索引升级工具-图形升级
第一步,启动运行索引升级升级工具,进入全文检索服务安装目录下的es-upgrade 文件夹下:
- Windows系统以管理员身份运行startup.bat脚本
- Linux系统执行
./startup.sh命令启动
启动后的界面为升级配置界面,配置说明:
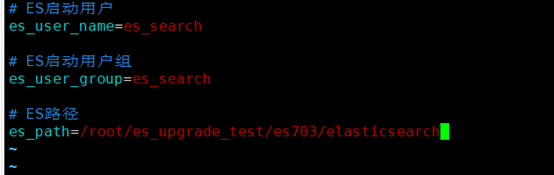
ES启动用户名:Linux系统下需要的配置项,Linux系统用户名,默认为es_search,不允许修改。用于启动elasticsearch服务,因为elasticsearch本身的安全机制的限制,不允许直接使用root用户启动。
ES启动用户组:Linux系统下需要的配置项,Linux系统用户名所属用户组,默认为es_search,不允许修改。
ES路径:指向全文检索程序路径下的ES\elasticsearch目录,Windows示例如
D:\Seeyon\Searchservice\ES\elasticsearch,Linux示例如/data/Seeyon/Searchservice/ES/elasticsearch
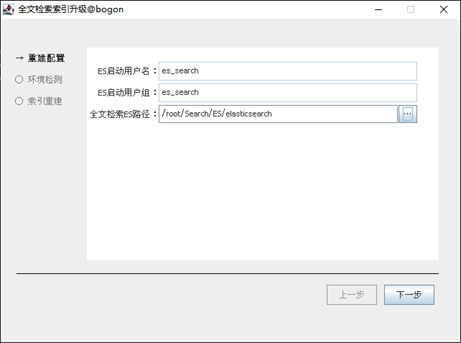
第二步,环境检查,完成第一步启动界面的相关配置后,点击【下一步】按钮,进入到升级环境检查界面:
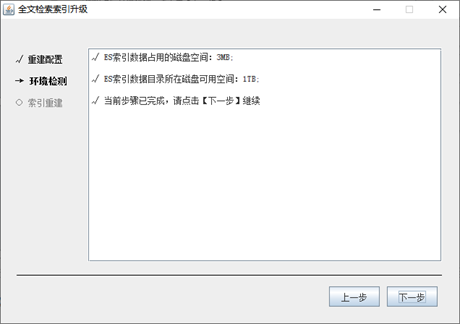
点击【下一步】,执行当前界面的升级环境检查。根据检查结果的处理提示,进行相应问题的处理后,接着点击【下一步】继续环境检查,直到所有的检查项都通过,如下:
第三步,索引重建:在完成上一步【环境检测】处理后,进行【下一步】操作,进入当前的索引重建界面,点击【下一步】,开始索引重建处理,直到处理完成:
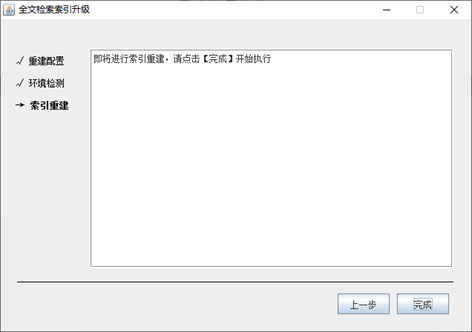
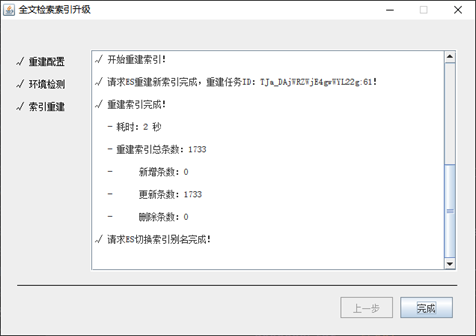
重建索引完成后,点击【完成】按钮,结束升级程序即可。然后正常进行索引服务的启动即可进行全文检索服务的检索验证和使用。
# 索引升级工具-命令升级
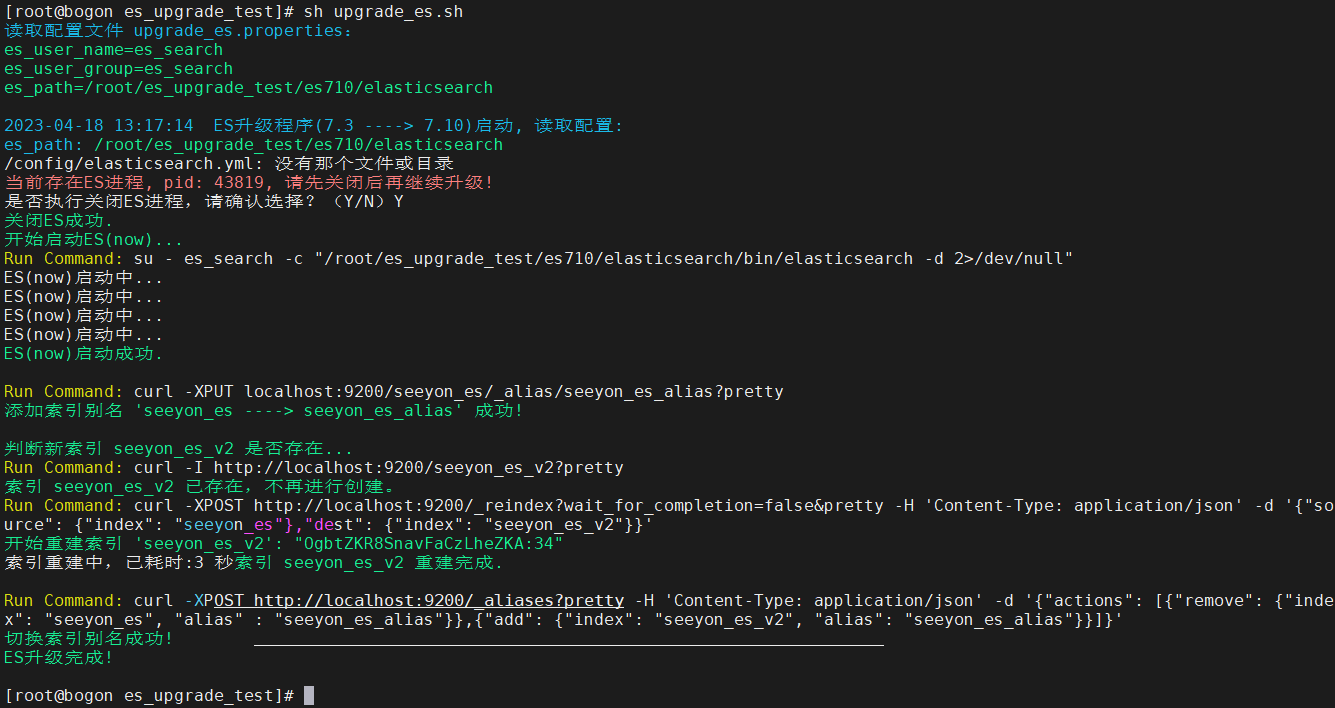
对于不支持可视化的Linux系统,提供了shell版本的升级脚本 es-upgrade.sh,位于全文检索服务安装根目录下的es-upgrade 目录下。
在登录Linux系统后,进入es-upgrade 目录下,编辑脚本需要的配置文件 es-upgrade.properties,添加或者修改相应的配置项,如下 图,各配置项对应的说明:
ES启动用户名:Linux系统下需要的配置项,Linux系统用户名,默认为es_search,不允许修改。用于启动elasticsearch服务,因为elasticsearch本身的安全机制的限制,不允许直接使用root用户启动。
ES启动用户组:Linux系统下需要的配置项,Linux系统用户名所属用户组,默认为es_search,不允许修改。
ES路径:指向全文检索程序路径下的ES\elasticsearch目录,Windows示例如
D:\Seeyon\Searchservice\ES\elasticsearch,Linux示例如/data/Seeyon/Searchservice/ES/elasticsearch
在当前目录下运行 es-upgrade.sh 脚本文件,直到命令行提示索引重建完成,过程中检测到正在运行的elasticsearch服务,提示关闭ES进程,请选择是(y):
# 全文检索集群部署配置
# 集群部署前要求
- 在部署全文检索集群模式前,先进行全文检索单机模式安装部署,确保单机模式全部配置完成,并且新建一条数据在全文检索侧进行检索测试,单机模式功能可用之后再部署集群模式!
- 如全文检索在Linux下部署,必须参考【Linux操作系统初始准备】章节对所有全文检索服务器参数进行调优,以获得更好的性能。
- 集群环境至少需要3个节点(奇数)才能实现高可用,准备三台同硬件配置全文检索服务器
- 集群服务器硬件资源配置可参考【服务器配置参考】章节,每一台服务器取单机2/3的硬件资源
# 集群安装部署步骤
全文检索集群起步三台(奇数),本手册以三台检索服务器为例进行配置:
再次提醒:先确保全文检索单机配通,并且新建的数据在全文检索能查询到结果后,再进行集群复制!
(1)停止原单机全文检索服务,后续将原单机全文检索服务当作集群节点一
(2)将集群节点一全文检索程序1比1复制到节点二、节点三服务器上,路径必须保持一致,然后删除节点二,节点三的/data/Seeyon/Searchservice/ES/base/data/nodes目录。此步操作也可放在第(3)步之后,可减少很多配置。
# 节点二、节点三创建目录
mkdir -p /data/Seeyon
# 节点一使用rsync命令同步文件到节点二、节点三
rsync -av --progress /data/Seeyon/Searchservice root@192.168.94.142:/data/Seeyon/
(3)依次修改集群节点一(原单机)、节点二、节点三的配置,使三个节点形成集群配置:
(3-1)配置每个elasticsearch节点信息:文件路径Searchservice\ES\elasticsearch\config\elasticsearch.yml,原文件内容全部删除,严格按照以下内容修改:
- cluster.name:自定义全文检索集群的名称,每个节点必须都一致
- node.name: 自定义节点名称,每个节点的标识,每个节点不能一样
- network.host: 当前全文检索节点服务器的物理IP
- discovery.seed_hosts: 集群中每个ES的地址,把所有节点都列出来
- cluster.initial_master_nodes: 集群的所有node节点名称,把所有节点的node.name都列出来
# 仅***星号部分的内容需要按需修改
# ***集群名称,可改也可不改,所有服务器节点必须保持一致
cluster.name: es-cluster
# 数据目录,不用修改
path.data: ../base/data
# ***节点名称,自定义,每个节点名称要唯一,比如节点一命名node1、节点二命名node2、节点三命名node3
node.name: node1
node.master: true
node.data: true
# ***当前全文检索节点服务器的物理ip
network.host: 192.168.94.138
# http 端口,不用修改
http.port: 9200
# tcp 监听端口,节点间通信用,不用修改
transport.tcp.port: 9300
# ***所有节点的物理IP和tcp监听端口(network.host:transport.tcp.port)全列在这里
discovery.seed_hosts: ["192.168.94.138:9300", "192.168.94.142:9300", "192.168.94.143:9300"]
#discovery.zen.fd.ping_timeout: 1m
#discovery.zen.fd.ping_retries: 5
# ***所有节点的节点名称(node.name)全列在这里
cluster.initial_master_nodes: ["node1", "node2", "node3"]
#action.destructive_requires_name: true
# 以下内容不要改
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.ml.enabled: false
(3-2)配置每个节点的Searchservice\ES\es-bin\es_index.json,修改配置项index.number_of_replicas,如下图:
三个节点配置1,五个节点配置2 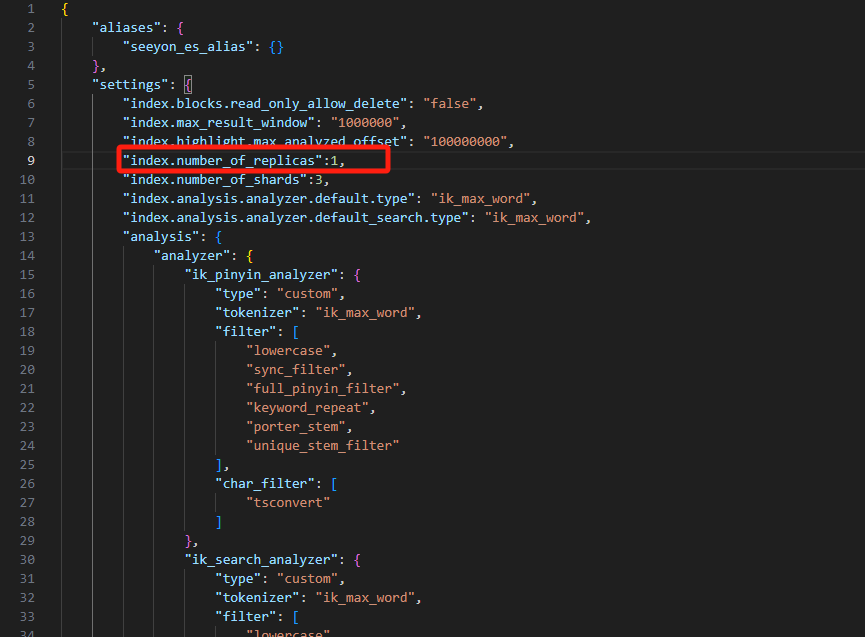
(3-3)配置每个节点searchservice微服务信息:文件路径Searchservice\search\searchservice\config\application.properties,原文件内容全部删除,严格按照以下内容修改:
- server.ip:当前全文检索服务器物理IP
- a8.server.url:协同服务请求地址,如果协同有前置Web负载均衡服务则指向Web负载地址
- regist.code:全文检索配置中心注册码,注册码获取方式参考本手册单机部署章节
- es_ips:ES各个节点的ip,全文检索所有节点的IP都列出来
- es_ports= ES各个节点的http端口,与(3-1)各节点的http.port配置对应,默认是9200
- es_ports_search= ES各个节点的tcp端口,与(3-1)各节点的transport.tcp.port配置对应,默认是9300
- cluster.name= ES集群名称,与(3-1)的cluster.name配置对应,要求所有节点保持一致
- mydict_path= 分词文件路径,新建一个空的共享目录,全文检索所有节点都指向这个共享目录地址,共享目录创建方式参考《协同集群部署手册》共享目录章节
#Tue Dec 17 15:51:42 CST 2019
#Tue Dec 17 15:51:42 CST 2019
##1.微服务配置项 ##
#{text} 服务ID readOnly,不改
server.id=INDEX_SERVICE
#{text} 服务名称 readOnly,不改
server.name=全文检索
#{text} ***全文检索服务器IP,当前节点的物理IP
server.ip=192.168.94.138
#{text} ***A8访问地址,如果协同是集群,要指向负载地址
a8.server.url=http://192.168.94.136/seeyon
#{text} ***全文检索配置中心注册码,注册码获取方式参考本手册单机部署章节
regist.code=77cd6de9-7809-476e-b0de-776ffb8649ca
##2.全文检索配置项##
#{text} 服务上下文路径 readOnly,不改
server.servlet.context-path=/index
#{text} 服务监听端口 readOnly,不改
server.port=9700
#{text} 索引数据目录 readOnly,不改
path_data=../base/data
#{text} ***ES 集群IP地址,默认不开启配置项,集群模式情况下展开 readOnly,所有服务的ES节点IP
es_ips=192.168.94.138,192.168.94.142,192.168.94.143
#{text} ***ES 集群端口,默认 9200 readOnly,所有全文检索节点的端口都列出来
es_ports=9200,9200,9200
#{text} ***ES 集群端口,默认 9300 readOnly,所有全文检索节点的端口都列出来
es_ports_search=9300,9300,9300
#{text} ik分词器热词请求地址白名单,不配置时不做校验 readOnly
#ik_ext_dict.request.hosts=127.0.0.1,127.0.0.1,127.0.0.1
#{text} ***ES 集群名,readOnly,注意与elasticsearch.yml的cluster.name保持一致
cluster.name=es-cluster
#{text} ES 索引别名,searchservice 服务调用时使用,since v8.2 readOnly
index_lib=seeyon_es_alias
#{text} ES 索引实际名称,searchservice 请求 ES 判断是否已升级时使用,since v8.2 readOnly
index_lib_real=seeyon_es_v2
#{text} 检索时完全匹配度,大于 0 的数值,0 表示完全匹配,数值越大,完全匹配度越低 readOnly
search.matchPhrasePrefix.slop=200
#{text} ***自定义分词文件的存储路径,集群情况使用,多节点需要共享该目录 readOnly
mydict_path=/mnt/share/search
# 是否AI同步节点 readOnly,与aiapp联合使用,可见智能应用章节
ai.isSyncNode = false
## 优化配置 ##
# 禁止upload文件解析结果缓存处理 readOnly
file_cache_enable=false
# flink 运行环境并发数 readOnly
core_num=8
# flink 检索历史统计处理并发数 readOnly
flink.source.his.parallelism=8
# flink 索引保存处理并发数 readOnly
#flink.source.parallelism=8
# flink es保存索引并发 readOnly
#flink.sink.parallelism=8
## 以下配置为可选配置,服务中均有默认值,一般情况下无需打开配置 ##
# OA 连接 ActiveMQ 服务器时的超时时间 readOnly
#activemq.connectResponseTimeout=5000
# 指定在连接中缓存的会话数量大小 readOnly
#activemq.sessionCacheSize=5
# 指定在接收消息时的最长等待时间 readOnly
#activemq.receiveTimeout=5000
# activemq 监听端口 readOnly
#activemq.port=16161
# activemq 索引消息队列的未消费最大消息数目 readOnly
#activemq.queueSize.limit=1000
# activemq 索引消息队列未消费消息数目达到或者超过限制后,循环等待的时长 readOnly
#activemq.producer.sleepMilliseconds=5000
# activemq rmi 端口 readOnly
#activemq.rmi.port=1099
# 发送消息的超时时间,用于指定在发送消息时的最长等待时间 readOnly
#activemq.sendTimeout=5000
# OA服务索引重试保存任务开始执行的延时时间 readOnly
#index.redoJob.delay=18000000
# OA服务索引重试保存任务定时执行的周期 readOnly
#index.redoJob.period=18000000
# OA服务 leveldb 失效索引数据删除任务开始执行的延时时间 readOnly
#index.delExpiredJob.delay=0
# OA服务 leveldb 失效索引数据删除任务执行的周期 readOnly
#index.delExpiredJob.period=18000000
# OA服务 leveldb 索引数据的达到失效状态的时长 readOnly
#index.leveldb.expiredDuration=172800000
# OA服务向 BlockingQueue 添加消息时阻塞的最长时间,超过该时间,则放弃添加 readOnly
#index.addBlockingQueue.timeout=7200000
# AI服务 ip port http://x.x.x.x:port / http://x.x.x.x readOnly
ai.server.url = http://x.x.x.x
# 全量同步ssh通道 readOnly
ai.server.ssh.url = http://127.0.0.1:6006
# Ai服务 全量同步方式 0 走AI算法服务,1 走ssh通道 默认走ssh通道
ai.index.sync.mode = 1
# ai服务 全量同步没批条数 readOnly
ai.index.sync.datas.size = 100
#ai服务 全量同步线程数 readOnly
ai.index.sync.thread.size = 2
#ai服务 是否需要重新进行全量同步: 0 不再次进行全量同步,1 重新进行全量同步 readOnly
ai.index.again.sync = 0
# ai服务,从某条数据开始重新开始全量同步 readOnly
ai.index.again.sync.from.id = 0
# 配置成OCR服务的地址。(格式:http://ip:port,端口默认12841)
ai.OCRUrl = http://192.168.0.3:12841
# 集群启停和验证
修改好配置以后,启动进行验证,由于ES开启集群后,不能使用默认的启动脚本进行启动(建议删除安装目录Searchservice\statrtup.sh|statrtup.bat,以免客户误用),开启集群后,启动顺序如下:
1、先启动原有的ES,再启动新加的节点,在Searchservice\ES\elasticsearc目录下启动所有节点的es
- windows 系统下:
.\bin\elasticsearch.bat
- Linux或信创系统下,必须使用普通用户启动,如:es_search
# 修改ES目录属主
chown -R es_search:es_search Searchservice/ES
# 切换普通用户
su - es_search
# 进入ES/elasticsearc/bin目录
cd /data/Seeyon/Searchservice/ES/elasticsearch/bin
# 执行ES启动
./elasticsearch -d
# 查看启动日志
tail -f ../logs/es-cluster.log
启动后通过命令 curl -X GET http://192.168.0.202:9201/_cluster/health?pretty查看状态
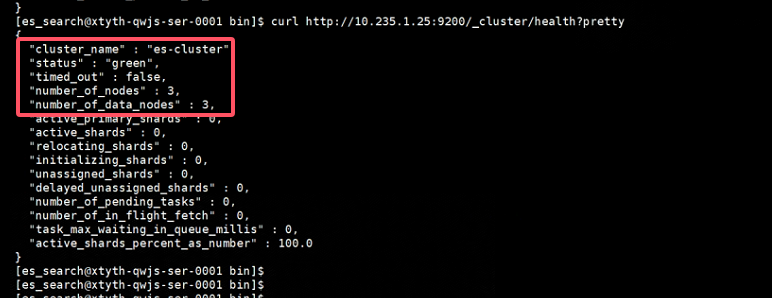
依次启动三个节点,三个节点启动完成后,再执行curl命令,确保number_of_nodes节点数必须是3个才对,status:green表示成功。
如启动不成功,重点排查三个问题:
- Linux系统需要参考【Linux操作系统初始准备】进行参数调整,否则会遇到无法启动问题
- Linux系统还需要对普通用户进行目录属主授权,然后切换成普通用户启动,ES不允许root用户启动
- 关闭防火墙或开通端口白名单,所有全文检索节点间必须确保9200、9300端口互通
全新部署环境如配置无误,启动三个ES无法形成集群(number_of_nodes还是1,status:yellow),则尝试删除各节点的base/data数据,再重新启动。
2、启动全文检索
通过Searchservice/search/searchservice/startup.sh|bat (Linux或信创下使用root用户启动),启动所有searchservice节点,然后测试功能即可。
以上完成后,登录系统管理员-微服务设置-全文检索-基础设置,查看注册节点是否正确
# 集群JVM配置调优
1、如需提高全文检索服务的堆内存资源,可修改全文检索程序根目录\config\jvm.properties文件,只修改文件中的-Xms和-Xmx参数(数值保持一样),修改后重新启动全文检索。比如将内存改成8G,就改如下参数即可(其余参数不要动,也不要删):
-Xms8G -Xmx8G
注意:
- 此堆内存修改对searchservice微服务有效
- 以上堆内存占用不能大于当前服务器总内存的75%。
附录:全文检索宕机案例 https://open.seeyoncloud.com/#/faq/faq/v1/share?url=Z2JySmU+MjExOQ==
2、如需修改elasticsearch的堆内存资源,可修改ES\elasticsearch\config\jvm.options文件,注意ES的堆内存和Searchservice微服务的堆内存总和不能大于当前服务器总内存的75%。
# 集群日志分析
全文检索如出现异常,集群环境下重点分析如下日志:
- 协同服务器,全文检索日志:ApacheJetspeed\logs_sy\index.log
- 全文检索服务器每个节点,Search微服务日志:\Searchservice\search\searchservice\logs\index.log
- 全文检索服务器每个节点,ES日志:\Searchservice\ES\elasticsearch\logs\ES集群名.log(elasticsearch.yml的cluster.name配置,如本手册示例为es-cluster.log)
# 常见问题
问题一: 全文检索application.properties中的a8.server.url参数(A8访问地址)配置成https负载后,全文检索微服务无法启动,地址配置成A8单机就可以启动:
查看全文检索index.log日志发现提示 javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target。
问题原因:A8负载走的https,而这个https是自签证书,不是合格的证书,导致请求不信任。解决方案是:购买带域名的SSL证书。 或者单独给全文检索开一个http的负载访问地址。
[2025-04-22 15:39:42.951] [ERROR] [main] [c.s.c.s.MicroServiceRegister.registerToA8:188] - 注册失败,原因,I/O error on POST request for "https://10.xxx.x.243/seeyon/rest/microservice/regist/INDEX_SERVICE": PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target; nested exception is javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
org.springframework.web.client.ResourceAccessException: I/O error on POST request for "https://10.xxx.x.243/seeyon/rest/microservice/regist/INDEX_SERVICE": PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target; nested exception is javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at org.springframework.web.client.RestTemplate.doExecute(RestTemplate.java:746) ~[spring-web-5.2.19.RELEASE.jar:5.2.19.RELEASE]
at org.springframework.web.client.RestTemplate.execute(RestTemplate.java:672) ~[spring-web-5.2.19.RELEASE.jar:5.2.19.RELEASE]
at org.springframework.web.client.RestTemplate.postForObject(RestTemplate.java:416) ~[spring-web-5.2.19.RELEASE.jar:5.2.19.RELEASE]
at com.seeyon.ctp.service.MicroServiceRegister.registerToA8(MicroServiceRegister.java:156) ~[microservice-common-trunk-SNAPSHOT.jar:trunk-SNAPSHOT]
at com.seeyon.ctp.service.MicroServiceRegister.start(MicroServiceRegister.java:83) ~[microservice-common-trunk-SNAPSHOT.jar:trunk-SNAPSHOT]
at com.seeyon.cdp.fulltext.SearchMain.main(SearchMain.java:44) ~[seeyon-fulltext-search-1.0-SNAPSHOT.jar:1.0]
at com.seeyon.cdp.fulltext.Main.main(Main.java:29) ~[seeyon-microservice-searchservice.jar:1.0]
Caused by: javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.ssl.Alert.createSSLException(Alert.java:131) ~[?:1.8.0_312]
at sun.security.ssl.TransportContext.fatal(TransportContext.java:324) ~[?:1.8.0_312]
at sun.security.ssl.TransportContext.fatal(TransportContext.java:267) ~[?:1.8.0_312]
快速跳转
