# SQLServer数据库修改排序规则为Chinese_PRC_90_CI_AI
# 背景
在选择使用SQLServer数据库时,OA要求数据库的排序规则必须是Chinese_PRC_90_CI_AI,对于部分低版本的客户,由于当时安装程序没有做强制检测或其他一些原因,导致客户在创建数据库时没有指定正确的排序规则。当这部分客户往高版本升级时,升级程序会对数据库的排序规则做检测,如果不满足正确的排序规则将无法继续后面的步骤。
注意:修改排序规则不能直接修改数据库选项中的参数配置,这会导致原数据表和新表排序规则不一致,可能会导致升级执行存储过程失败,后续功能异常等,且无法修复
# 问题现象
场景一:安装程序时校验不通过:标准产品需要使用Chinese_PRC_90_CI_AI排序规则:
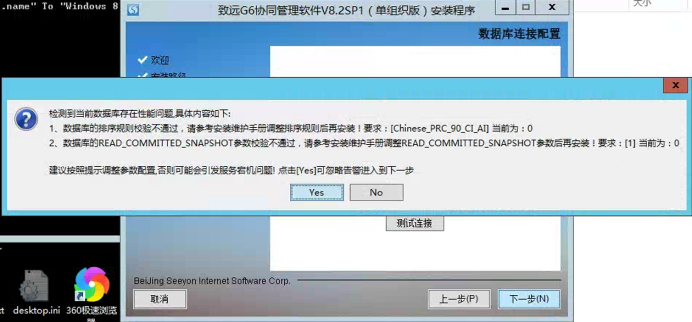
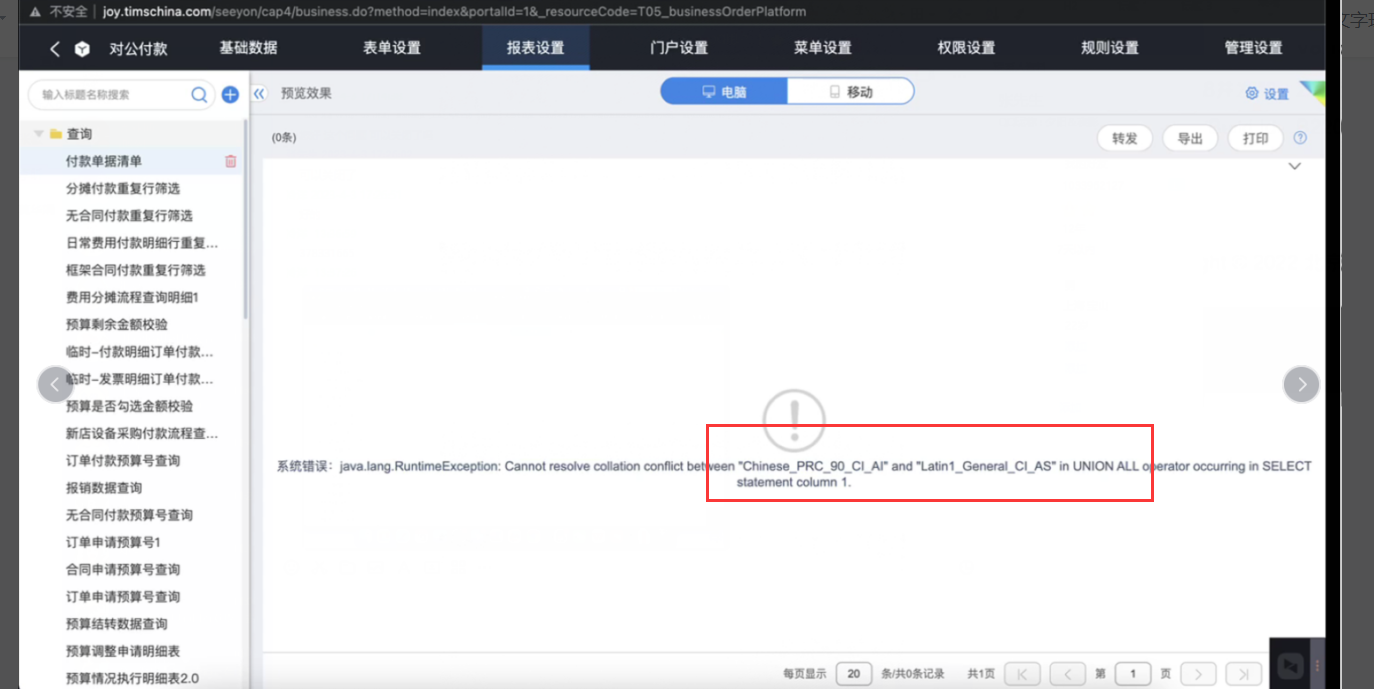
场景二:如未修改到正确的排序规则,使用产品功能时,会出现类似如下的错误:
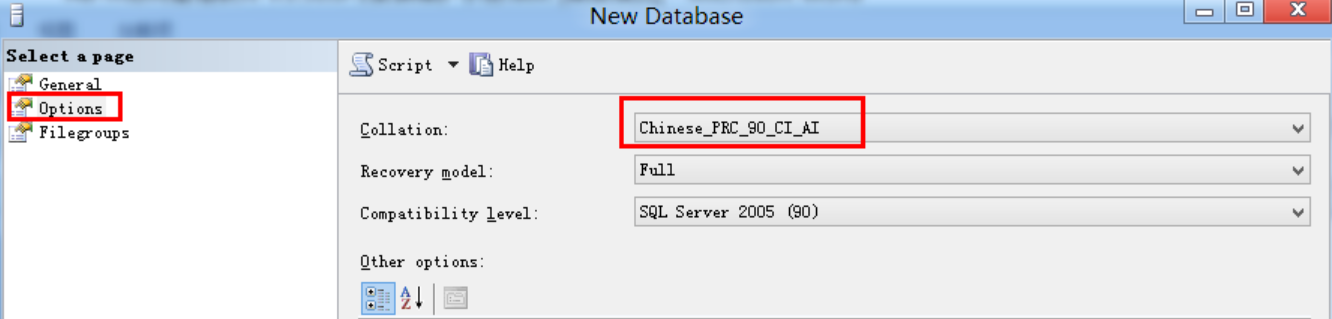
场景三:环境检查工具扫描发现排序规则不匹配,给出了整改提示:
正确的排序规则如下:
场景四:升级日志报错,出现如下关键字异常无法解决列 9(在 SELECT 语句中)的排序规则冲突:
Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: 无法解决列 9(在 SELECT 语句中)的排序规则冲突。
at com.microsoft.sqlserver.jdbc.SQLServerException.makeFromDatabaseError(SQLServerException.java:217)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.getNextResult(SQLServerStatement.java:1655)
at com.microsoft.sqlserver.jdbc.SQLServerPreparedStatement.doExecutePreparedStatement(SQLServerPreparedStatement.java:440)
at com.microsoft.sqlserver.jdbc.SQLServerPreparedStatement$PrepStmtExecCmd.doExecute(SQLServerPreparedStatement.java:385)
at com.microsoft.sqlserver.jdbc.TDSCommand.execute(IOBuffer.java:7505)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.executeCommand(SQLServerConnection.java:2445)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeCommand(SQLServerStatement.java:191)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeStatement(SQLServerStatement.java:166)
at com.microsoft.sqlserver.jdbc.SQLServerPreparedStatement.execute(SQLServerPreparedStatement.java:367)
at com.seeyon.ctp.install.util.JDBCAgent.executeOther(JDBCAgent.java:227)
# 排序规则修改方法
新创建一个Chinese_PRC_90_CI_AI排序规则的新数据库,然后经过一定的操作将问题库数据导入到新库。
本示例场景:
现有存在错误排序规则的库,库名为v56sp1init
计划创建Chinese_PRC_90_CI_AI排序规则的新数据库,库名为v56sp1init_new
操作步骤如下:
第1步,从问题数据库v56sp1init导出全量的SQL脚本;
第2步,编辑上一步导出的sql文件,批量修改数据库名称、批量修改排序规则为产品要求的CHINESE_PRC_90_CI_AI;
第3步,创建新库v56sp1init_new;
第4步,借助导出导入数据向导,将数据从v56sp1init导入新库v56sp1init_new,完成。
# 第1部分:导出整个库的架构sql
1.选择原数据库右键>任务>生成脚本
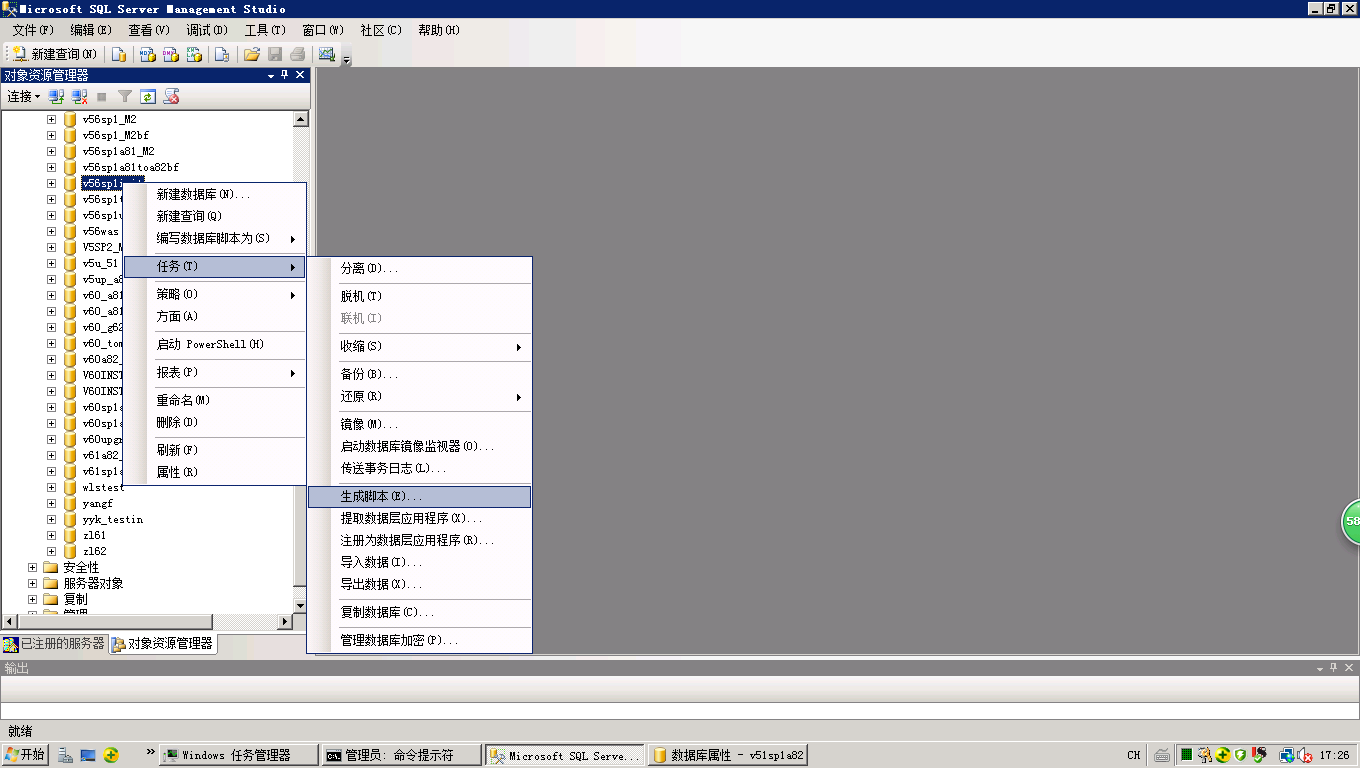
2.下一步
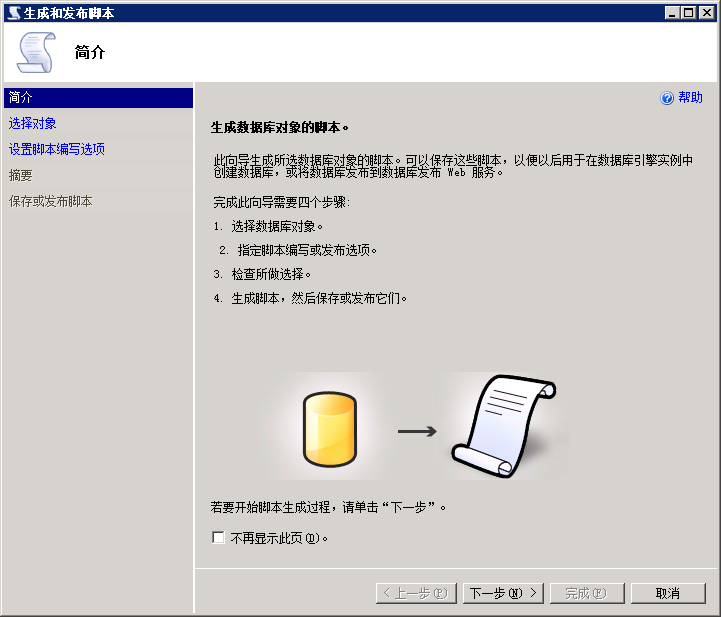
3.默认编写整个数据库及所有数据库对象的脚本,下一步
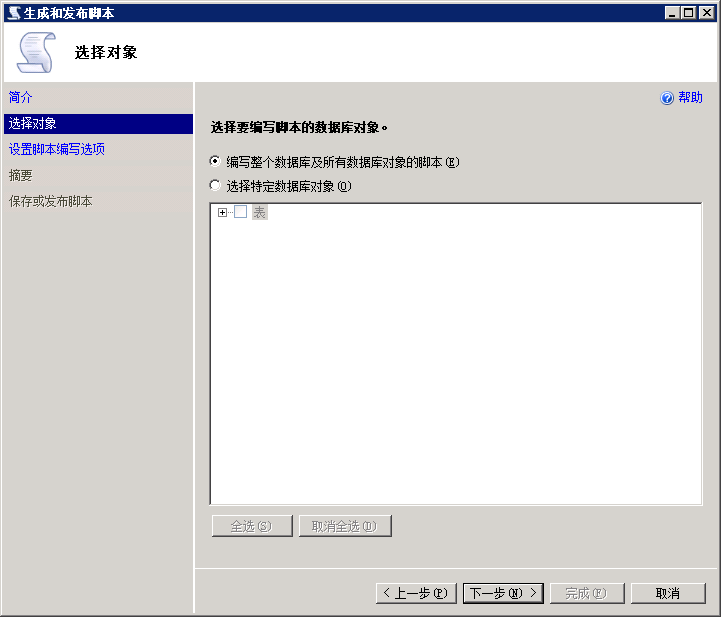
4.存为单个文件,覆盖现有文件,ANSI文本,文件名以及存放目录设置
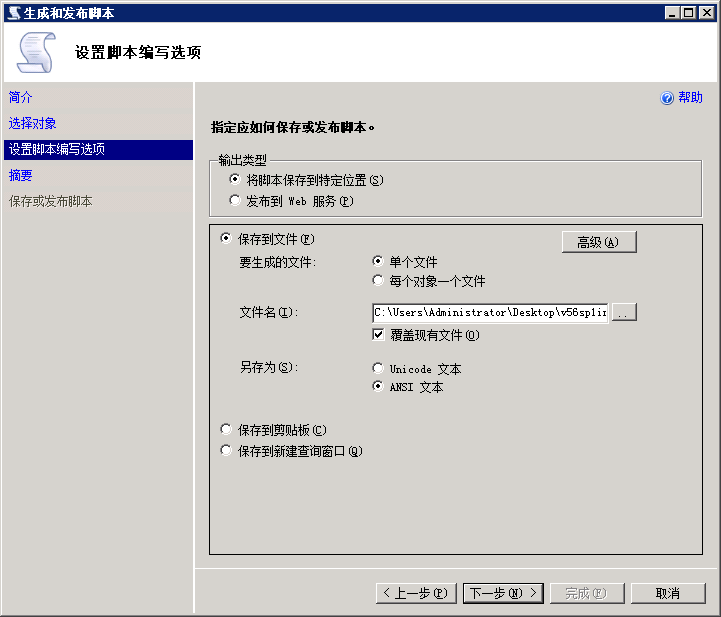
5.高级按钮中true、false的设置,编写约束、触发器、索引、外键、唯一键、主键脚本均为true
6.编写USE DATABASE、排序规则等脚本均为true
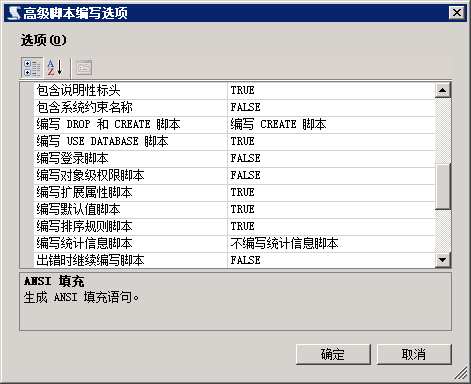
7.编写脚本的数据类型,仅限架构
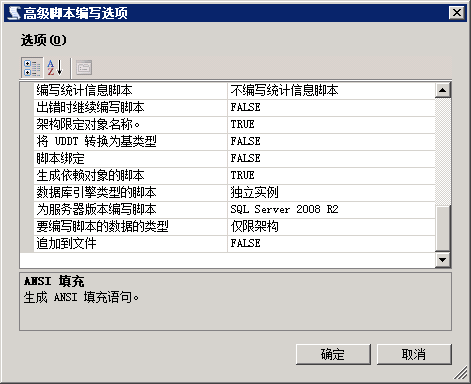
8.下一步
9.等待生成脚本
10.结果须要均为成功
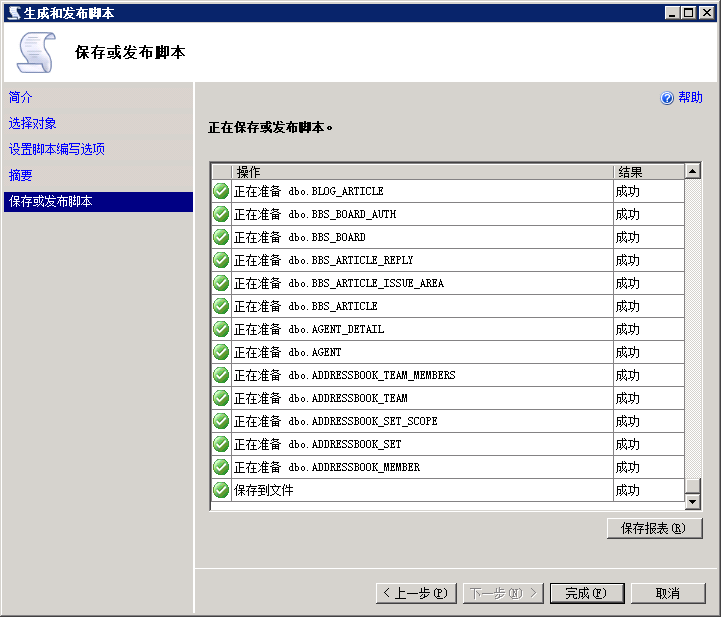
# 第2部分:修改数据库名称及修改排序规则
使用文本编辑器,修改导出的文件内容:
1.数据库名[v56sp1init]替换为[v56sp1init_new]
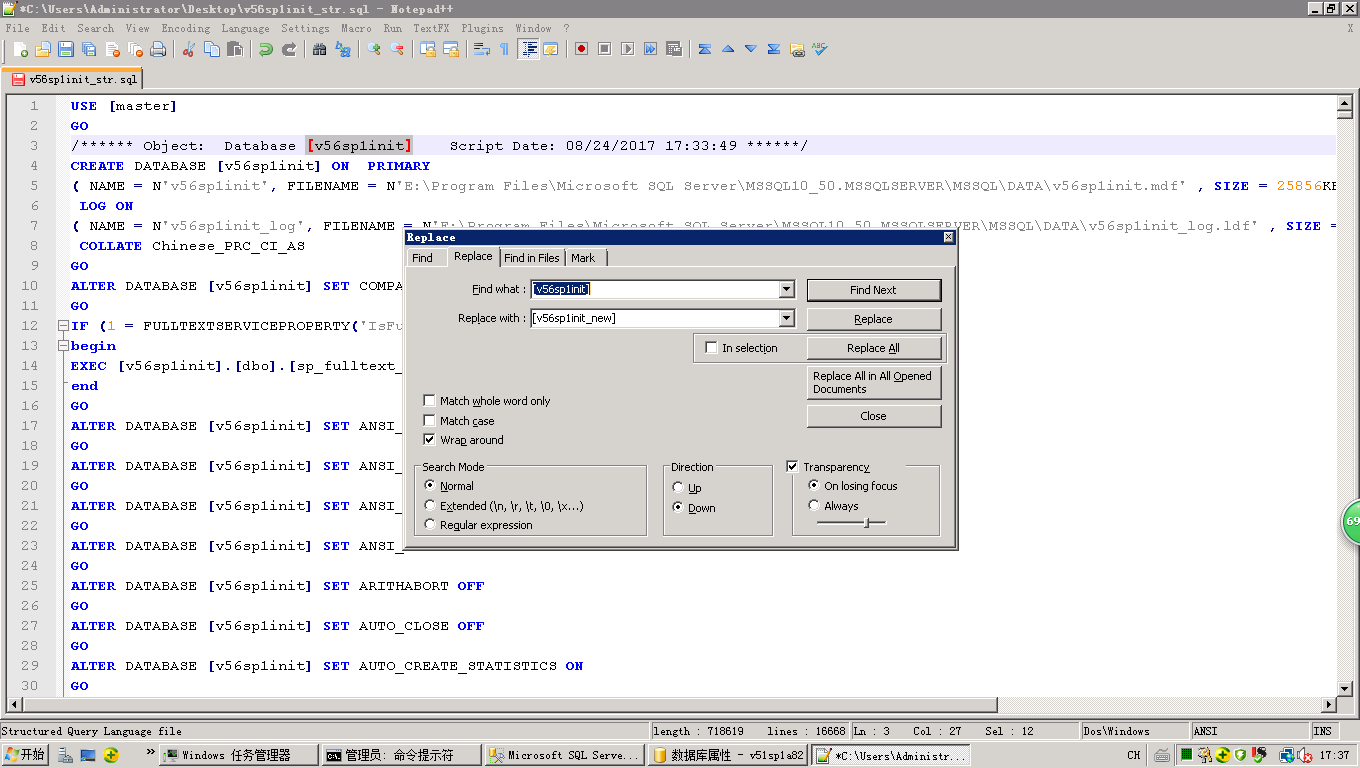
2.mdf和ldf文件名也需修改命名:绿色底色光标处的"v56sp1init"关键字改成"v56sp1init_new":
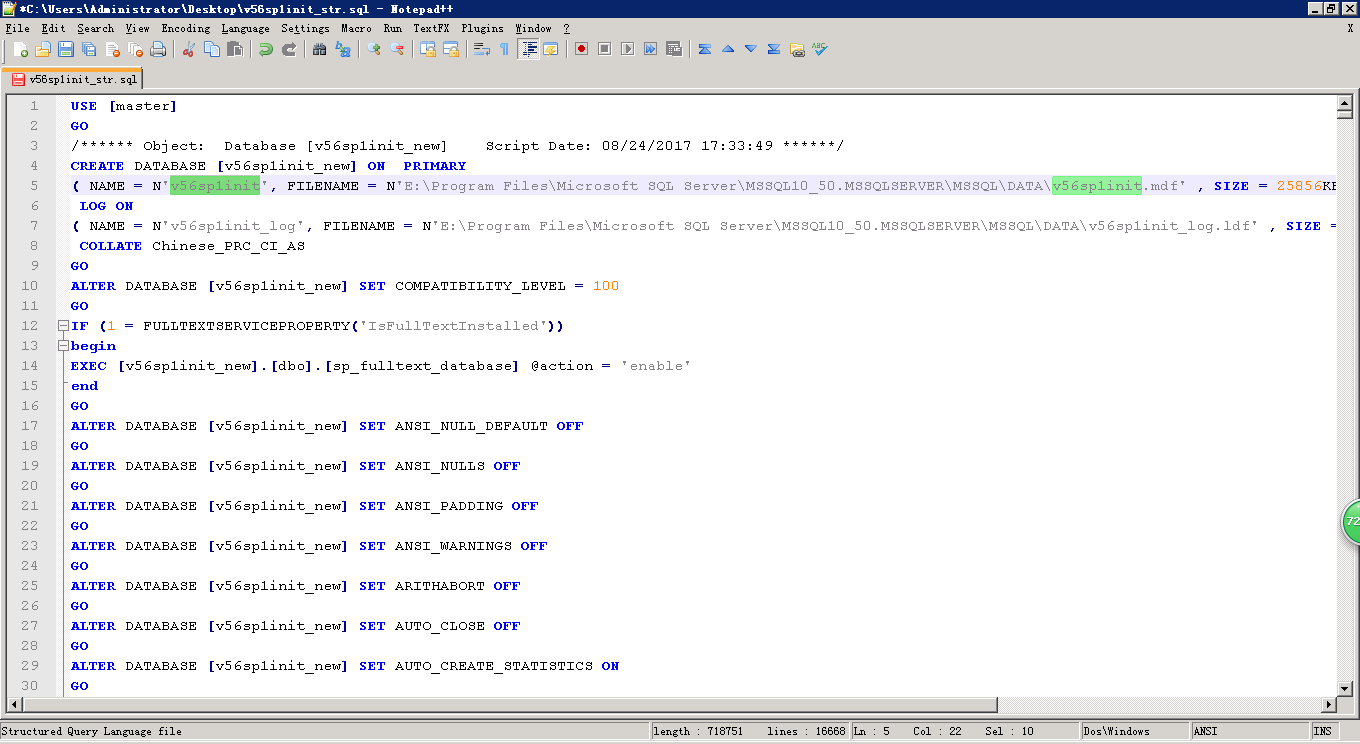
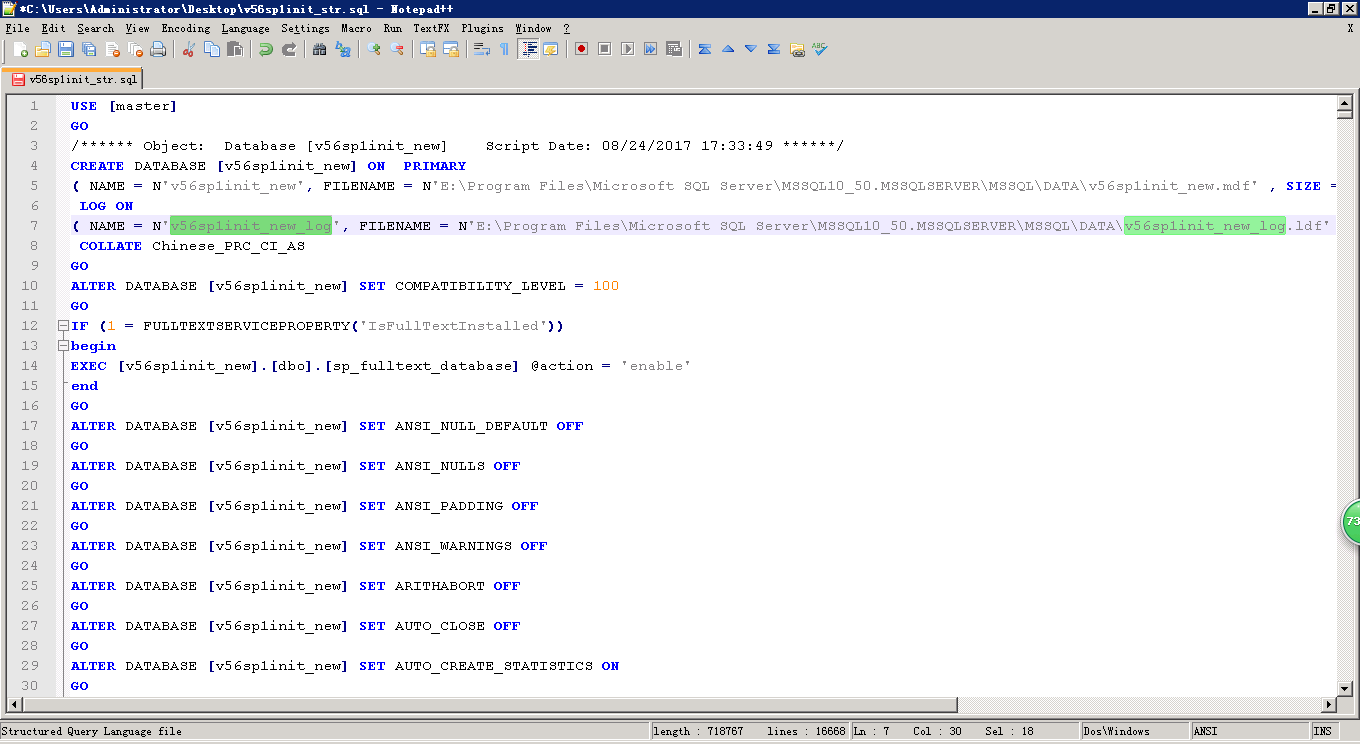
3.全局再搜索一下是否存在"v56sp1init"的数据库名称,需要将其修改为"v56sp1init_new":
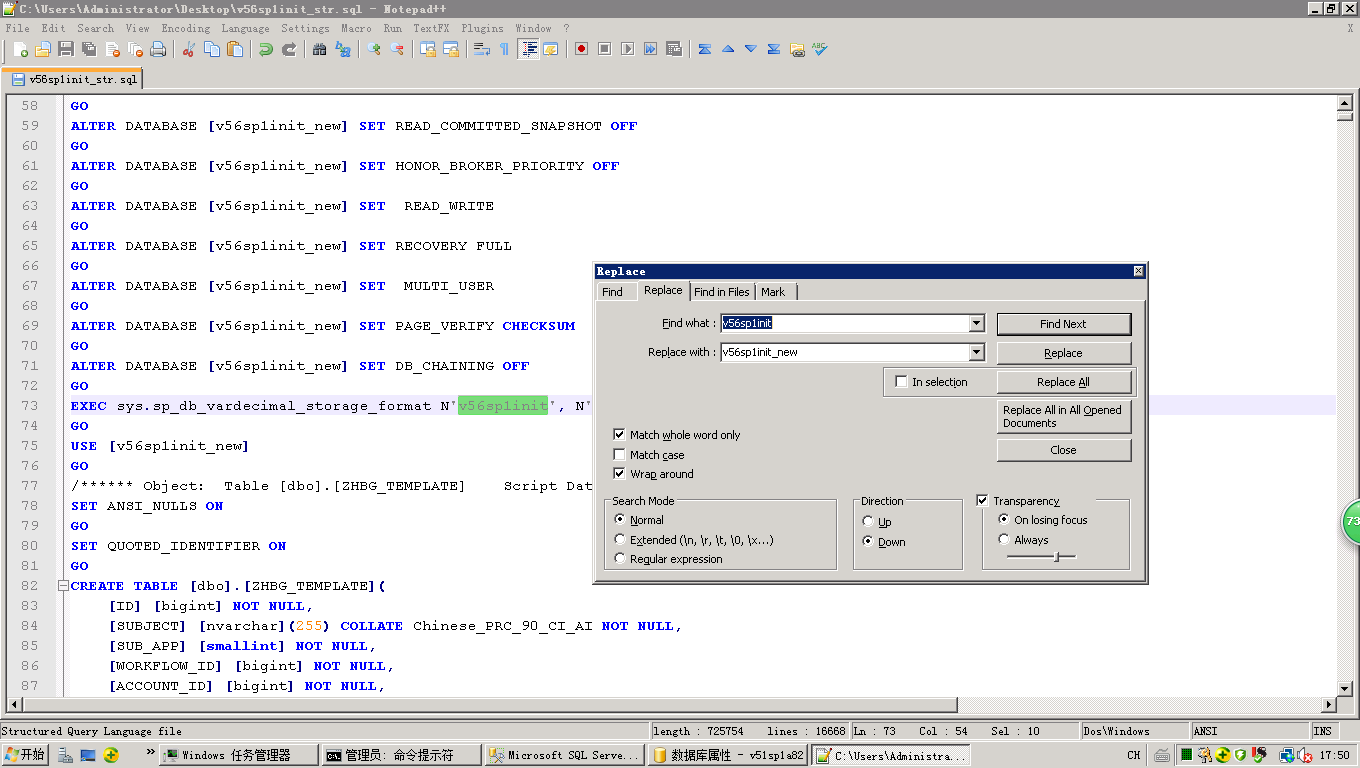
4.排序规则修改:看下问题库的关键字是什么将其批量修改为CHINESE_PRC_90_CI_AI,如下图绿色光标是错误的排序规则,需要修改至正确:
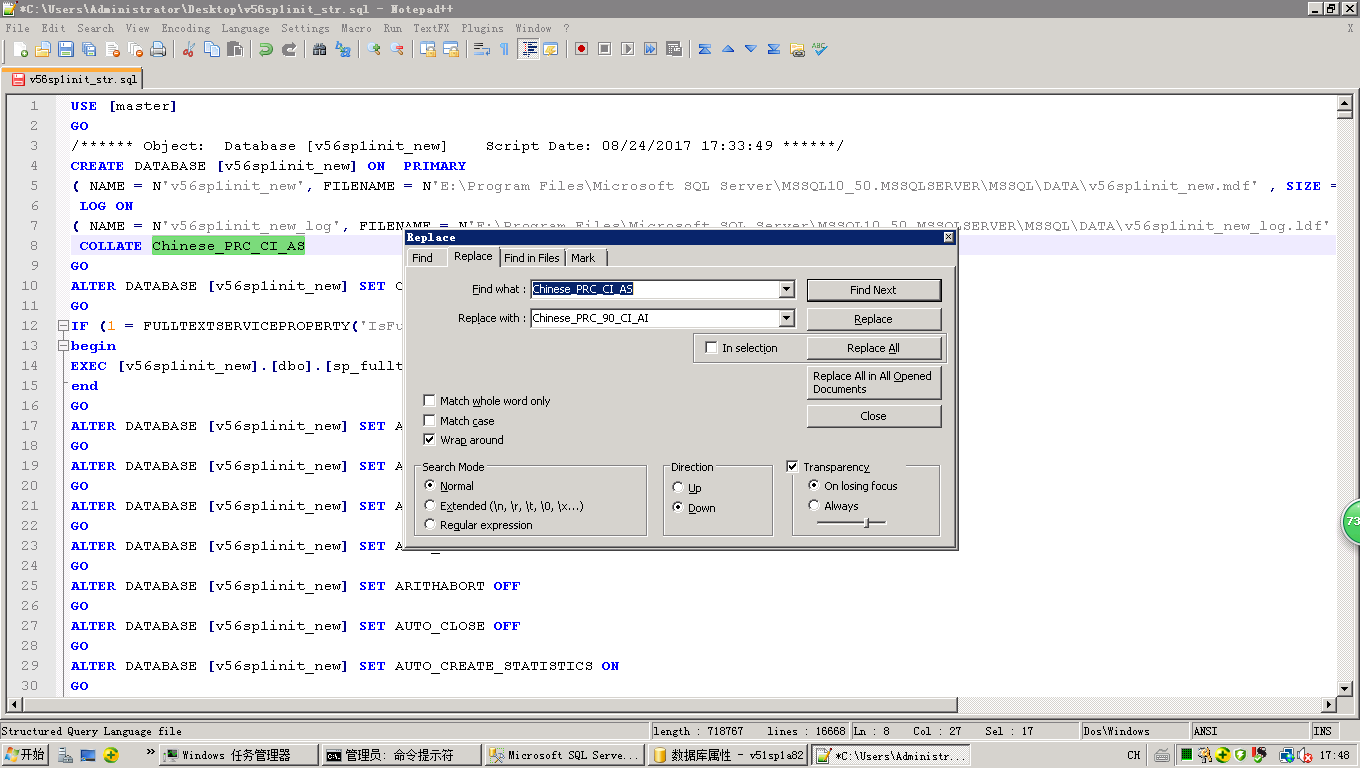
# 第3部分:执行sql文件,创建新库
1.在管理工具中打开sql文件选择master数据库执行
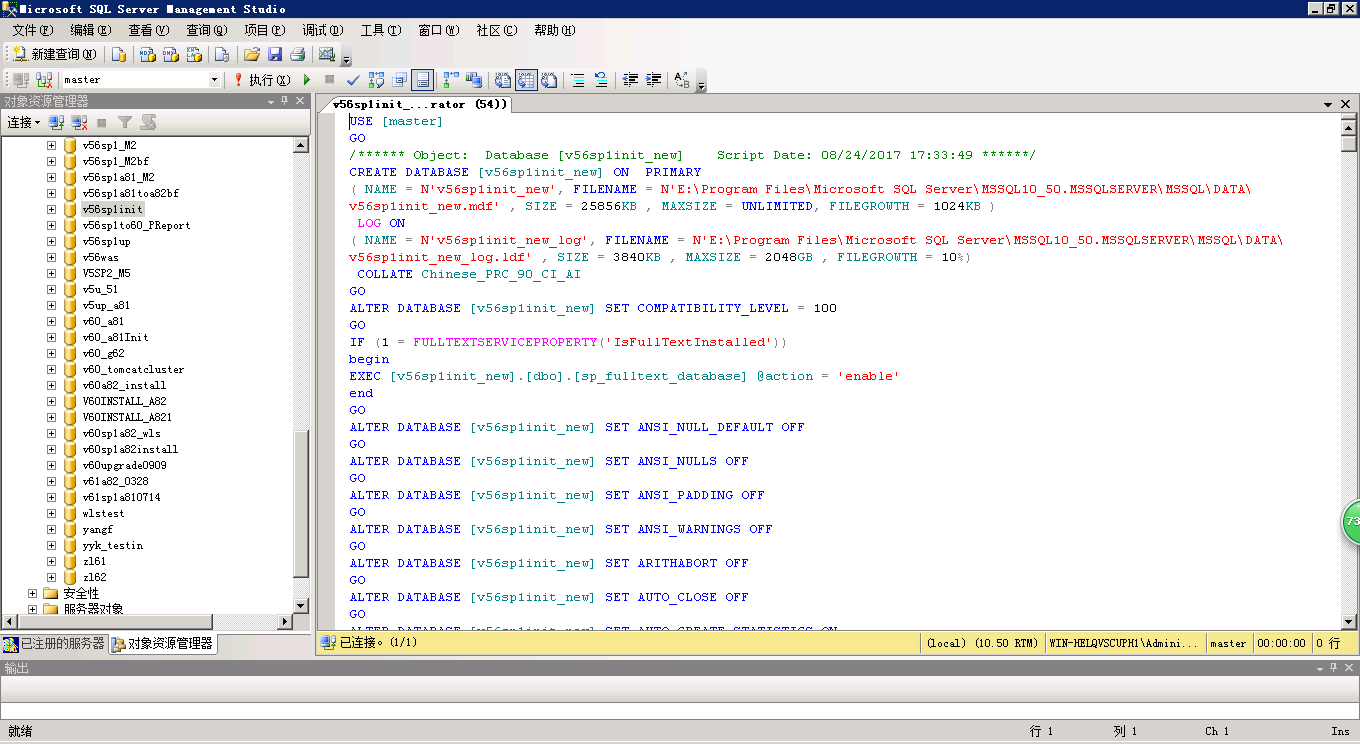
2.执行结果效果
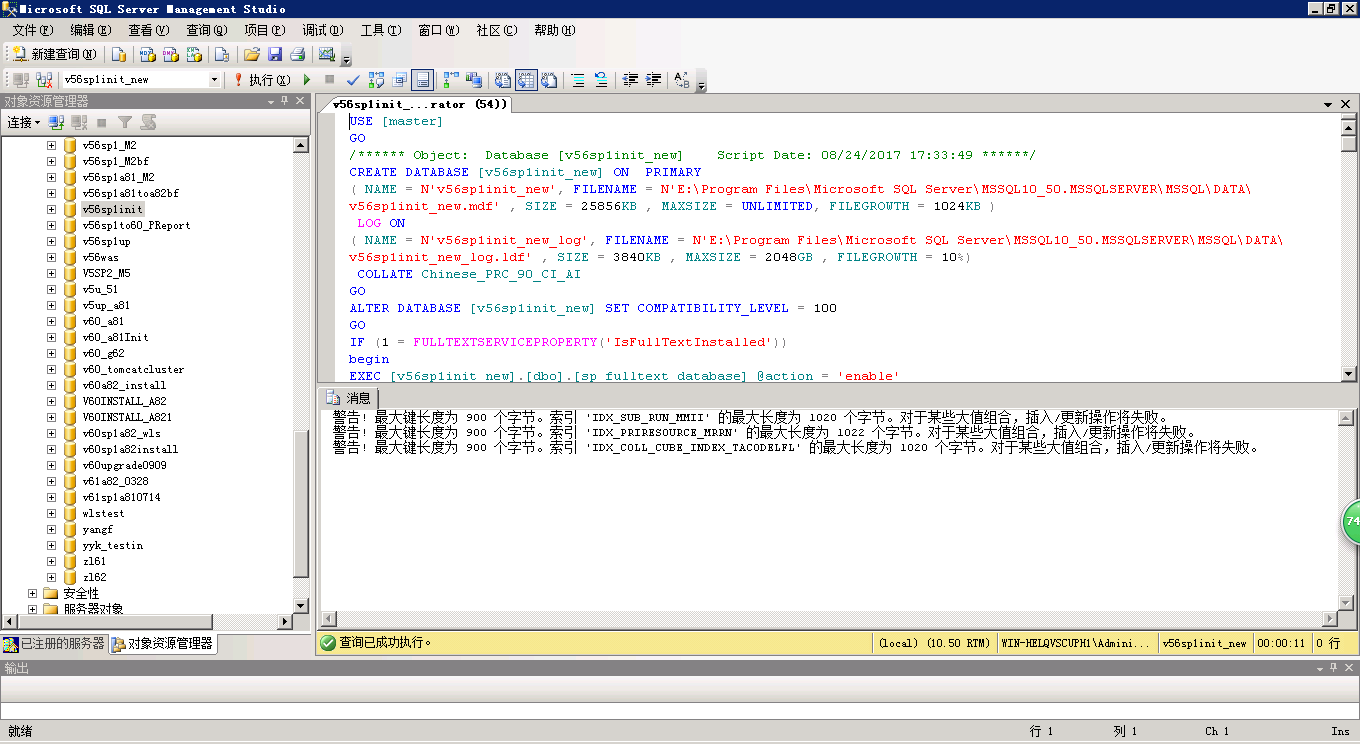
3.刷新后出现新数据库
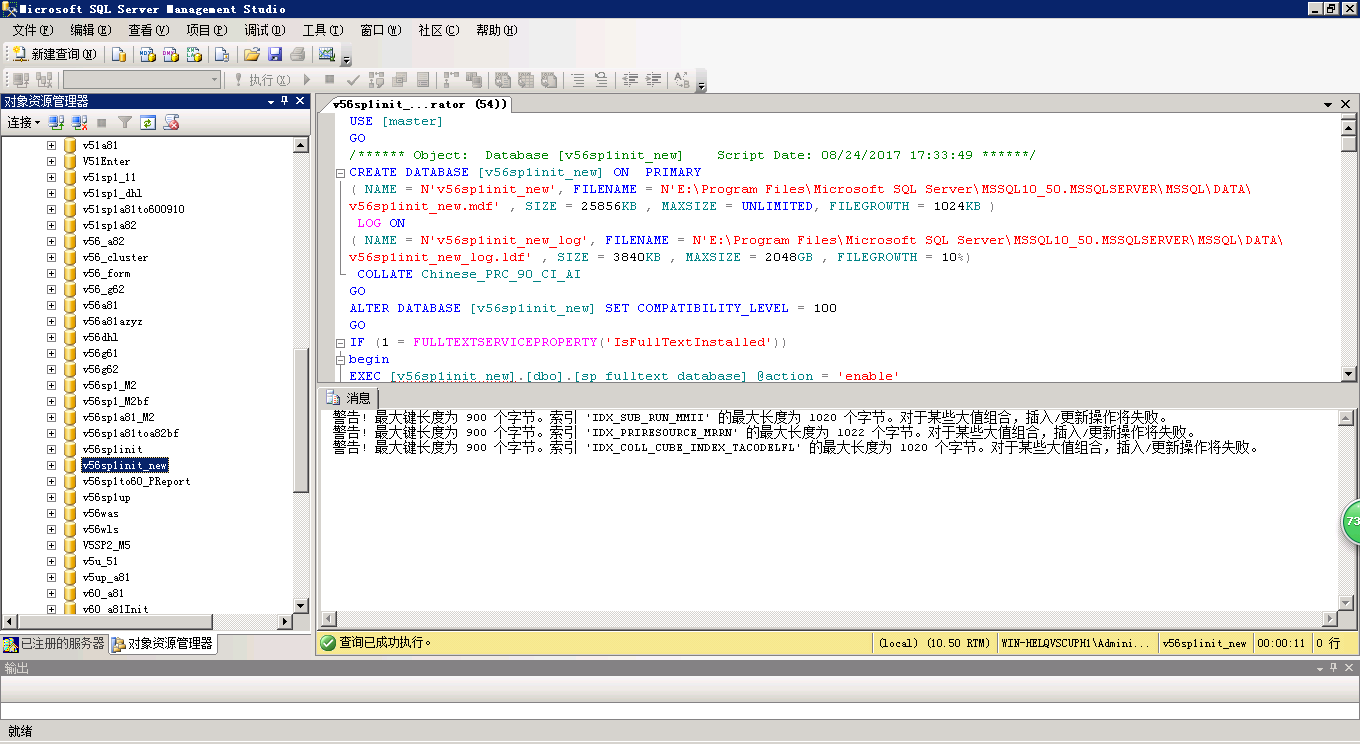
# 第4部分:将数据从生产环境数据库导入新库
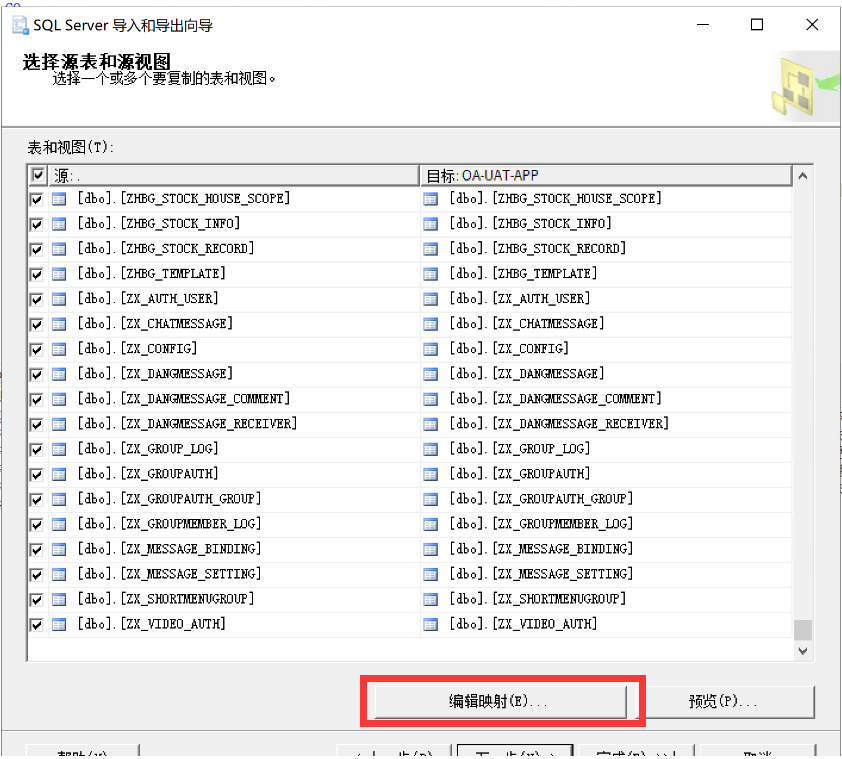
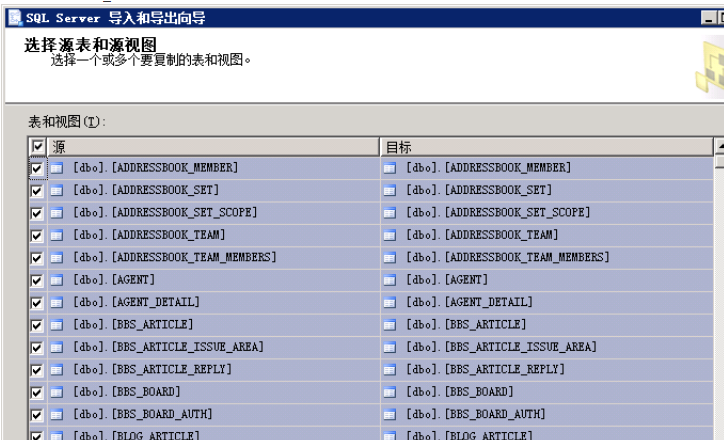
1.选择新数据库右键>任务>导入数据
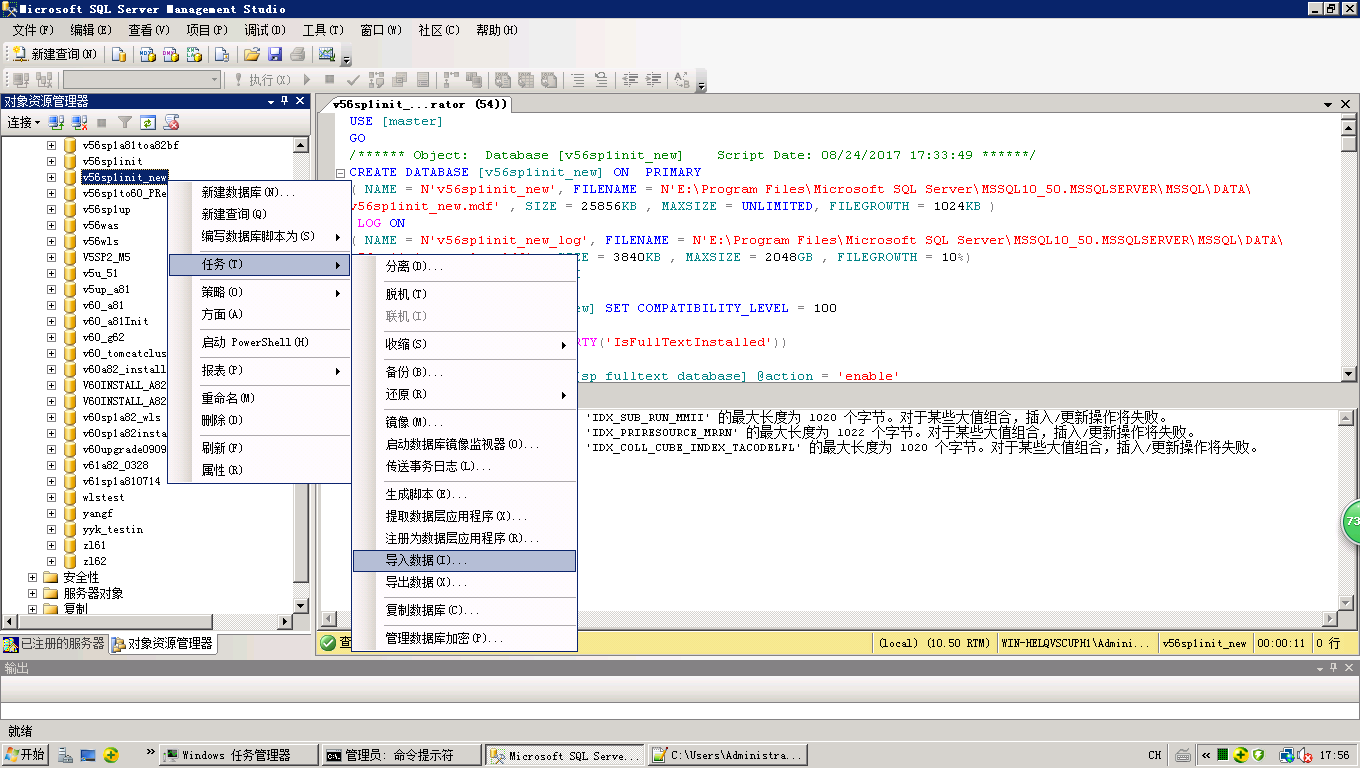
2.下一步
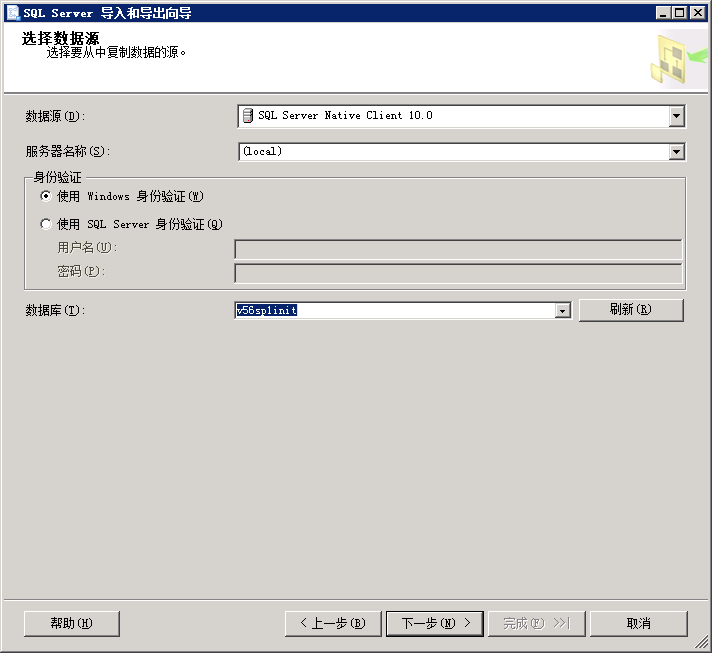
3.左上角选择数据源头,服务器名称为本地
4.选择目标为新库,服务器名称也为本地
5.选择复制一个或多个表数据
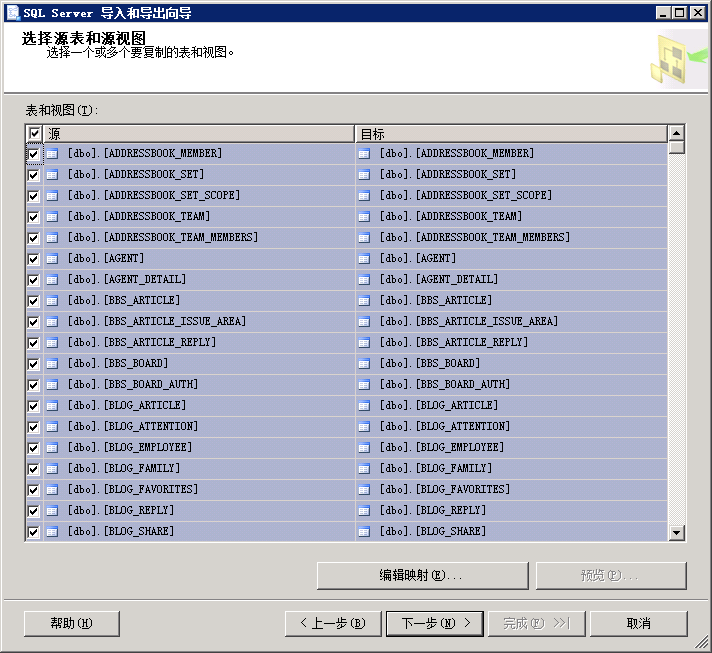
6.勾选左上角-源(全选)
7.立即运行,下一步
完成
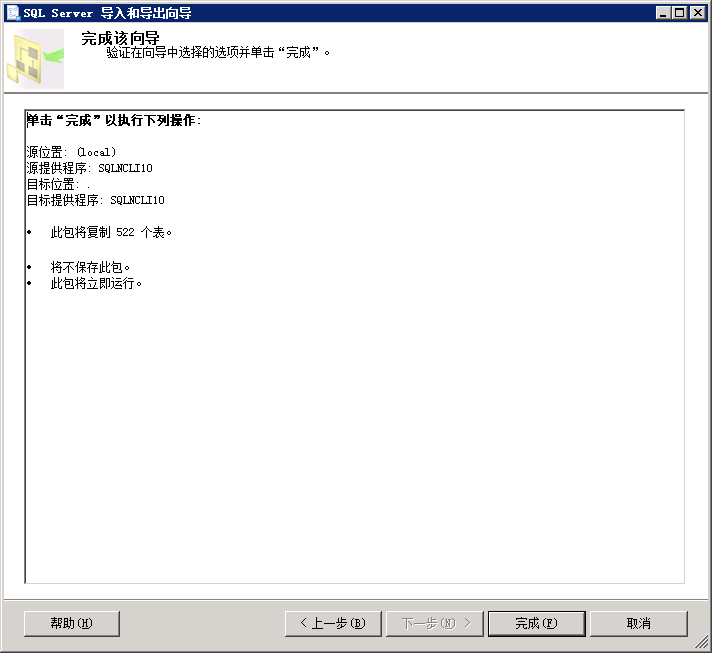
正在导入数据
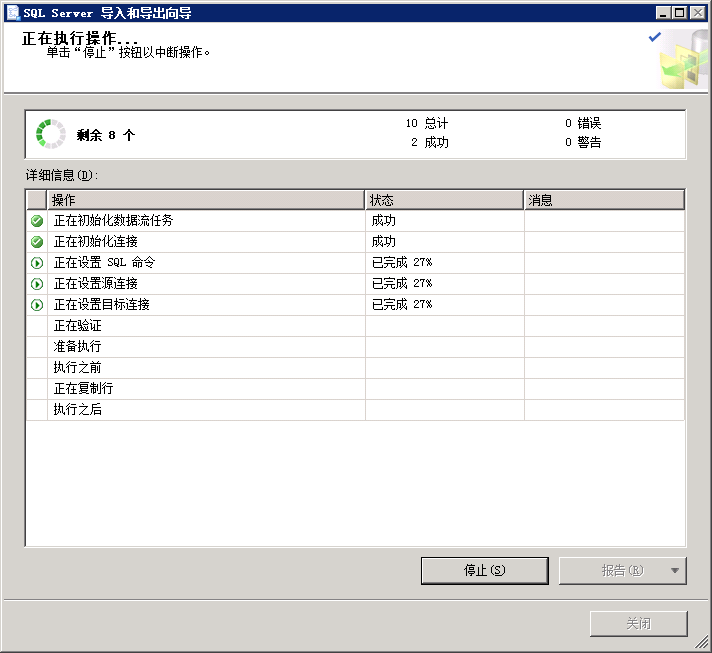
8.没有错误则转库完成
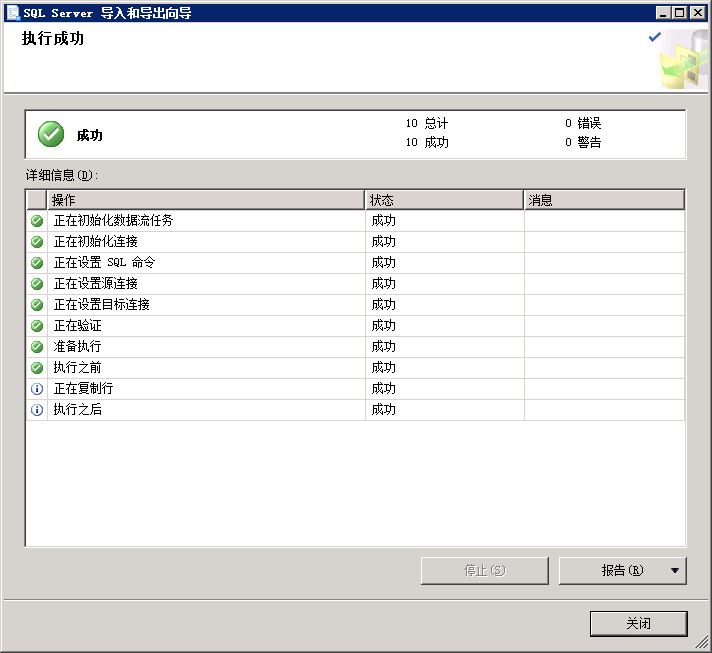
注意:如果导入过程有报错,必须确认并解决,可参考下列常见报错的解决方法
# 常见问题
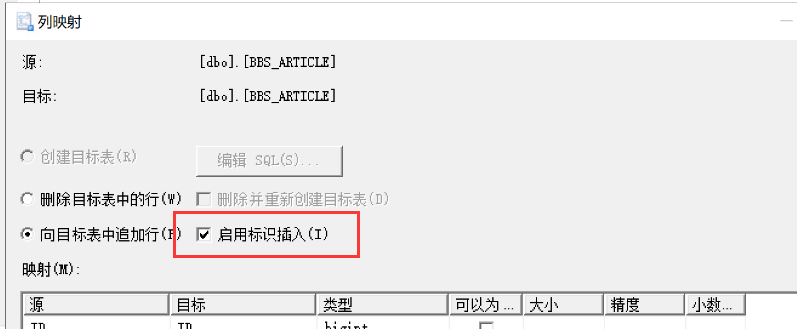
# 1.报错:无法在只读列“ID”中插入数据
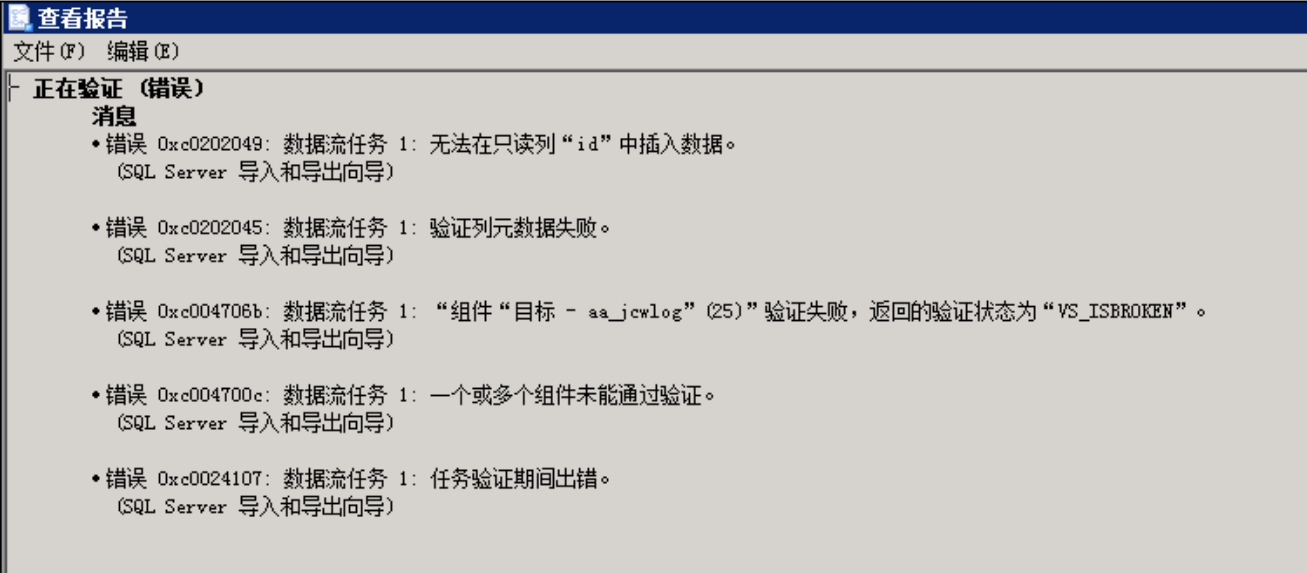
# 解决方法:
导入导出向导,在“选择源表和源视图”页,在导入导出的表打勾之后点击编辑映像,选择“启用标识列插入!”即可
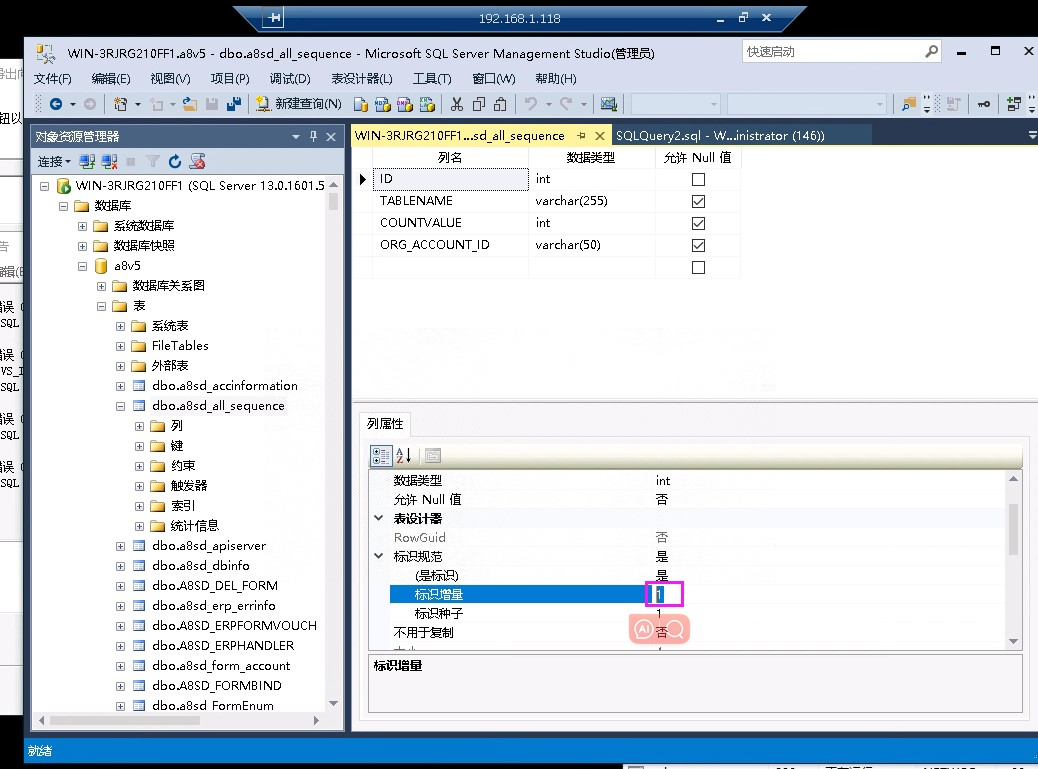
###情况2:若启用标识列插入无法解决,考虑为客开表创建时表加了标识增量导致
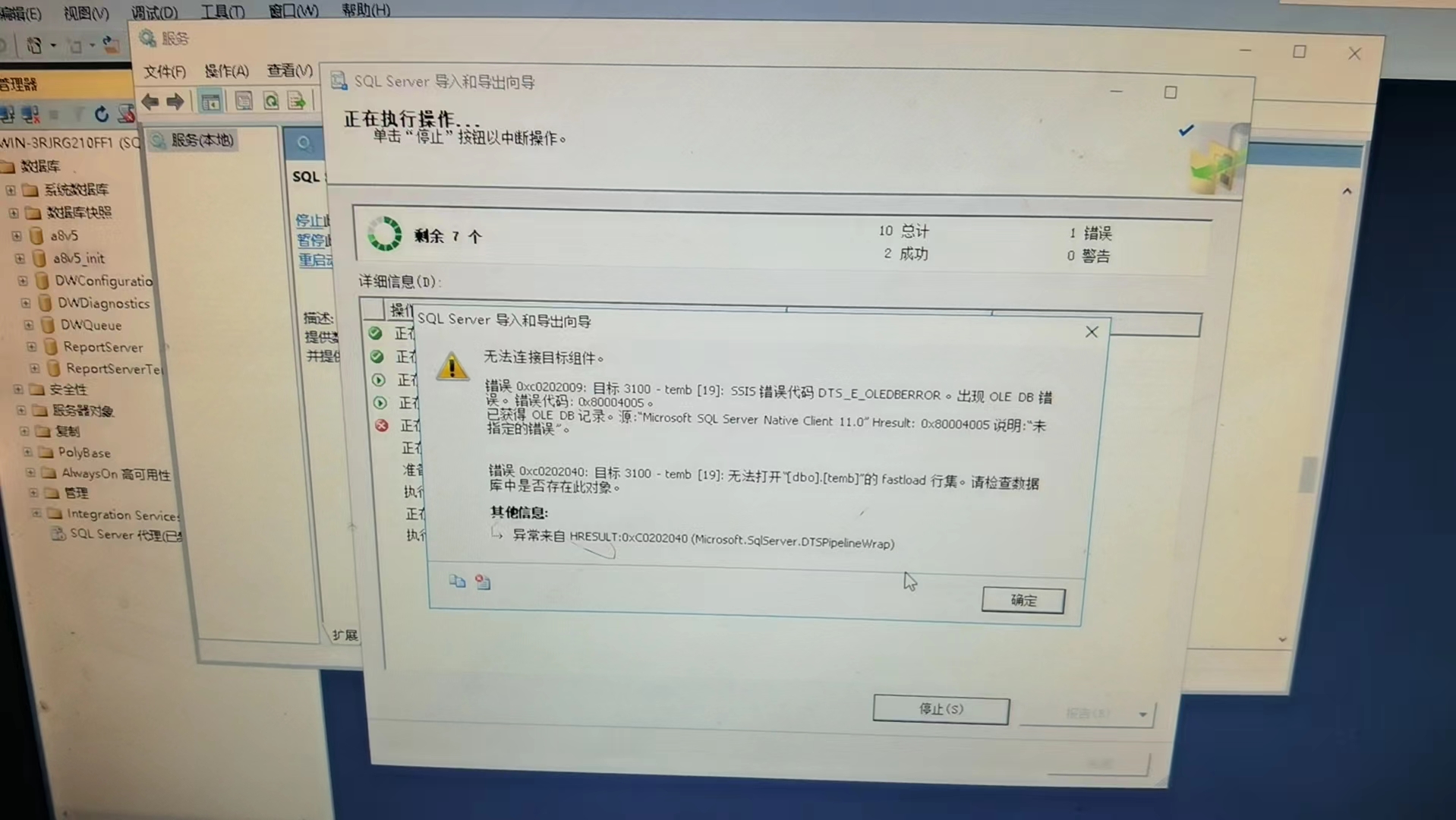
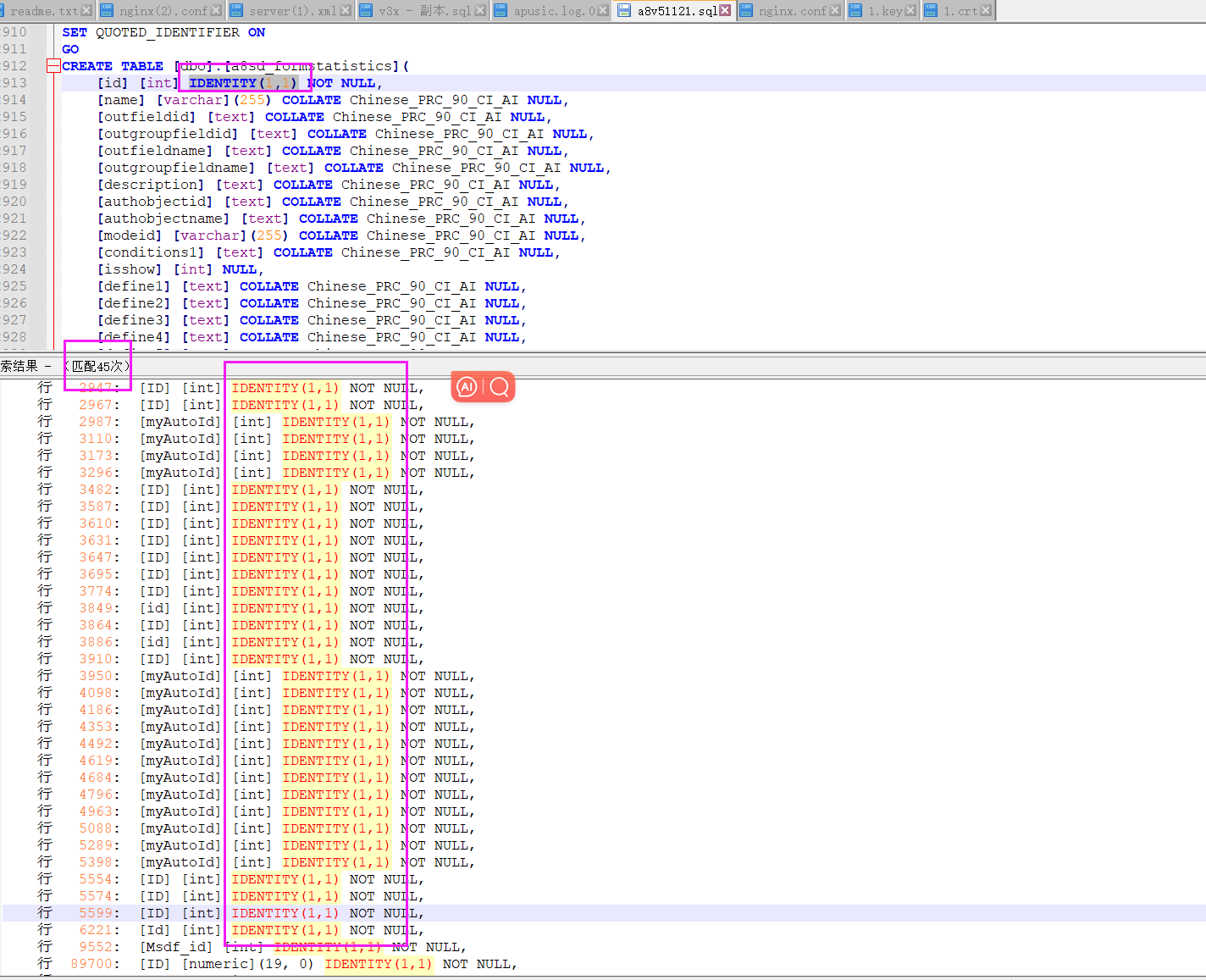
# 解决方法:将对应表标识增量去掉,导完了再改回来
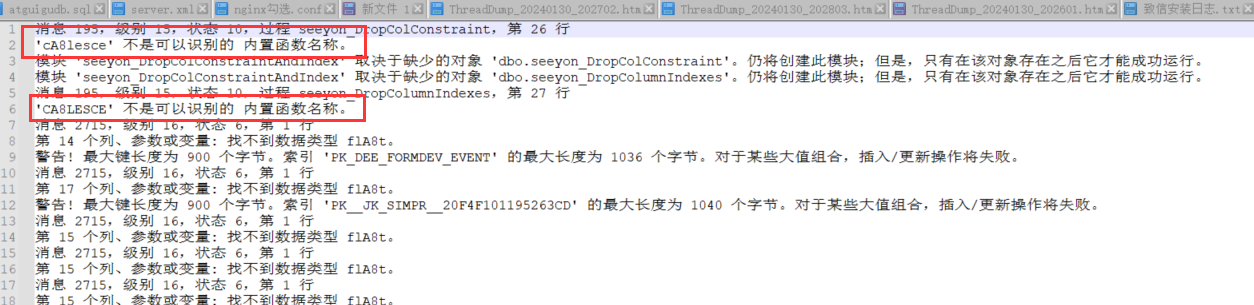
# 2.报错:不是可识别的内置函数名称
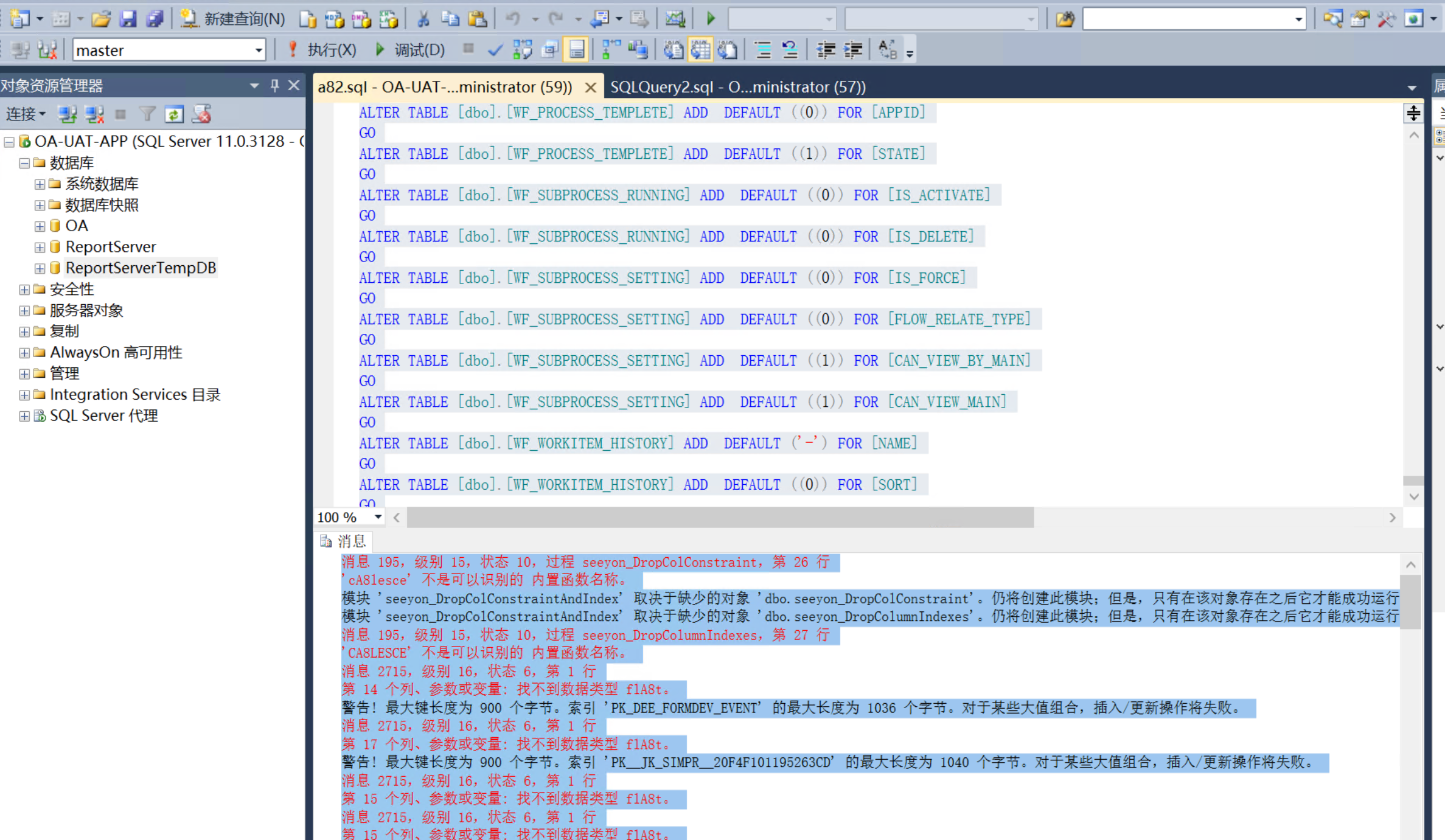
原因为原库叫OA,批量换成A8,将函数名称也一并改了导致
# 解决方法:
将报错函数名改回原来,重新生成数据库
**注意:**修改替换数据库名时建议逐个替换确认,避免替换到函数名、数据类型等,关注数据库名称为OA、DB等
# 3.报错为视图、触发器相关
由于标准产品不包含视图、触发器,且不涉及标准产品数据
需找对应客户客开确认,或可以在导入源时不勾选对应视图、触发器。
快速跳转
