# 手动部署
最后更新: 2023年02月18日 05:00:00
# 环境说明
1、采用官方最新二进制版离线部署 k8s 高可用集群,基于 k8s 集群再部署其他相关插件等。
2、基于 keepalived + haproxy + tengine 实现高可用和负载均衡以及反向代理。
3、基于 containerd 容器运行时。
4、基于红帽最新操作系统 rhel 8.9 离线部署。
5、基于 harbor 本地私有仓库镜像。
6、IPv4和IPv6双协议栈支持。
7、通过中控机进行安装部署。中控机要求可连接互联网。便于拉取和制作容器镜像。
# 部署规划
# 主机准备
仅为测试验证,使用最低硬件配置,也没有做存储规划。
当前环境在现有的 v8-k8s-console/192.168.100.190 中控机上执行所有部署操作。
id Hostname IPv4/IPv6/VIP CPU Mem OS/Disk Data/Disk OS Arch Role
0 k8s-vip 192.168.100.60 0 0 0 0 - - vip/lb
1 k8s-m1 192.168.100.61 2 4 100 0 rhel 8.9 arm64 master
2 k8s-m2 192.168.100.62 2 4 100 0 rhel 8.9 arm64 master
3 k8s-m3 192.168.100.63 2 4 100 0 rhel 8.9 arm64 master
4 k8s-n1 192.168.100.64 2 4 100 0 rhel 8.9 arm64 worker
5 k8s-n2 192.168.100.65 2 4 100 0 rhel 8.9 arm64 worker
6 k8s-n3 192.168.100.66 2 4 100 0 rhel 8.9 arm64 worker
# 软件准备
软件 版本 需求 用途说明 官网
red hat enterprise linux 8.9 必需 操作系统 https://www.redhat.com (opens new window)
containerd 1.7.8 必需 容器运行时 https://github.com/containerd/containerd/releases (opens new window)
runc 1.1.10 必需 创建和运行容器 https://github.com/opencontainers/runc/releases (opens new window)
cni-plugins 1.3.0 必需 提供标准的网络接口 https://github.com/containernetworking/plugins/releases (opens new window)
cri-tools 1.28.0 必需 CLI for kubelet CRI https://github.com/kubernetes-sigs/cri-tools/releases (opens new window)
kubernetes 1.28.3 必需 容器编排系统 https://kubernetes.io (opens new window)
keepalived 2.2.4 必需 高可用-系统自带 https://www.keepalived.org (opens new window)
haproxy 2.4.17 必需 负载均衡-系统自带 https://www.haproxy.org (opens new window)
tengine 3.1.0 必需 反向代理-编译安装 https://github.com/alibaba/tengine (opens new window)
tengine-ingress 1.1.0 可选 网关 https://github.com/alibaba/tengine-ingress (opens new window)
# 镜像准备
镜像名 版本/tag 需求 用途说明 官方来源
kube-apiserver v1.28.3 必需 kubernetes系统入口 registry.k8s.io/kube-apiserver:v1.28.3
kube-controller-manager v1.28.3 必需 负责维护集群的状态 registry.k8s.io/kube-controller-manager:v1.28.3
kube-scheduler v1.28.3 必需 资源调度 registry.k8s.io/kube-scheduler:v1.28.3
kube-proxy v1.28.3 必需 集群内的服务发现和负载均衡 registry.k8s.io/kube-proxy:v1.28.3
etcd 3.5.9-0 必需 kubernetes的数据存储核心 registry.k8s.io/etcd:3.5.9-0
coredns v1.10.1 必需 为集群中的服务提供域名解析 registry.k8s.io/coredns/coredns:v1.10.1
pause 3.9 必需 负责Pod容器的创建、启停等 registry.k8s.io/pause:3.9
kube-controllers v3.26.3 必需 cni 网络插件-calico docker.io/calico/kube-controllers:v3.26.3
cni v3.26.3 必需 cni网络插件-calico docker.io/calico/cni:v3.26.3
node v3.26.3 必需 cni网络插件-calico docker.io/calico/node:v3.26.3
# 网络准备
网卡:一张1000M以上速率的网卡。
带宽:局域网100M以上。
公共网络:192.168.100.0/24
pod 子网:10.244.0.0/16
service子网:10.96.0.0/12
# DNS准备
在 DNS 域名服务器上添加以下 DNS 域名解析。主要区域为正向区域,源记录种类为A,TTL为86400秒。
没有 DNS 服务的情况下,可考虑使用本地域名解析。
DNS:192.168.100.254 202.98.198.167
192.168.100.254 为局域网 DNS 解析服务地址,202.98.198.167 为互联网 DNS 解析服务地址。
------ ---------------- ------------------------------ ----------------- -----------------
序号 IPv4地址 IPv6地址 域名 备注
0 192.168.100.60 240e:338:813:e4b1::a9c1:c060 vip.upx.plus
1 192.168.100.61 240e:338:813:e4b1::a9c1:c061
2 192.168.100.62 240e:338:813:e4b1::a9c1:c062
3 192.168.100.63 240e:338:813:e4b1::a9c1:c063
4 192.168.100.64 240e:338:813:e4b1::a9c1:c064
5 192.168.100.65 240e:338:813:e4b1::a9c1:c065
6 192.168.100.66 240e:338:813:e4b1::a9c1:c066
------ ---------------- ------------------------------ ----------------- -----------------
# 拓扑架构
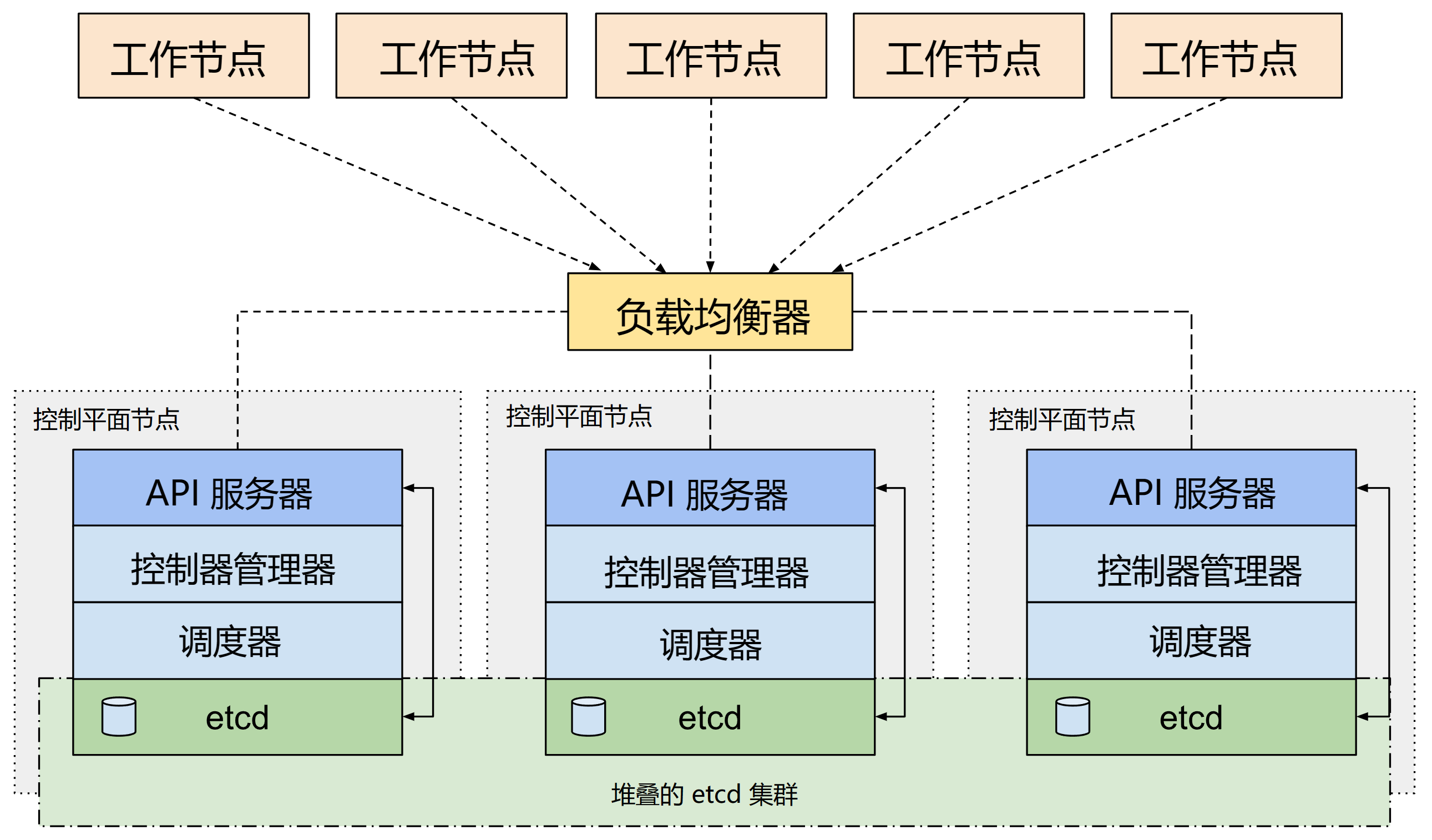
# 实施流程
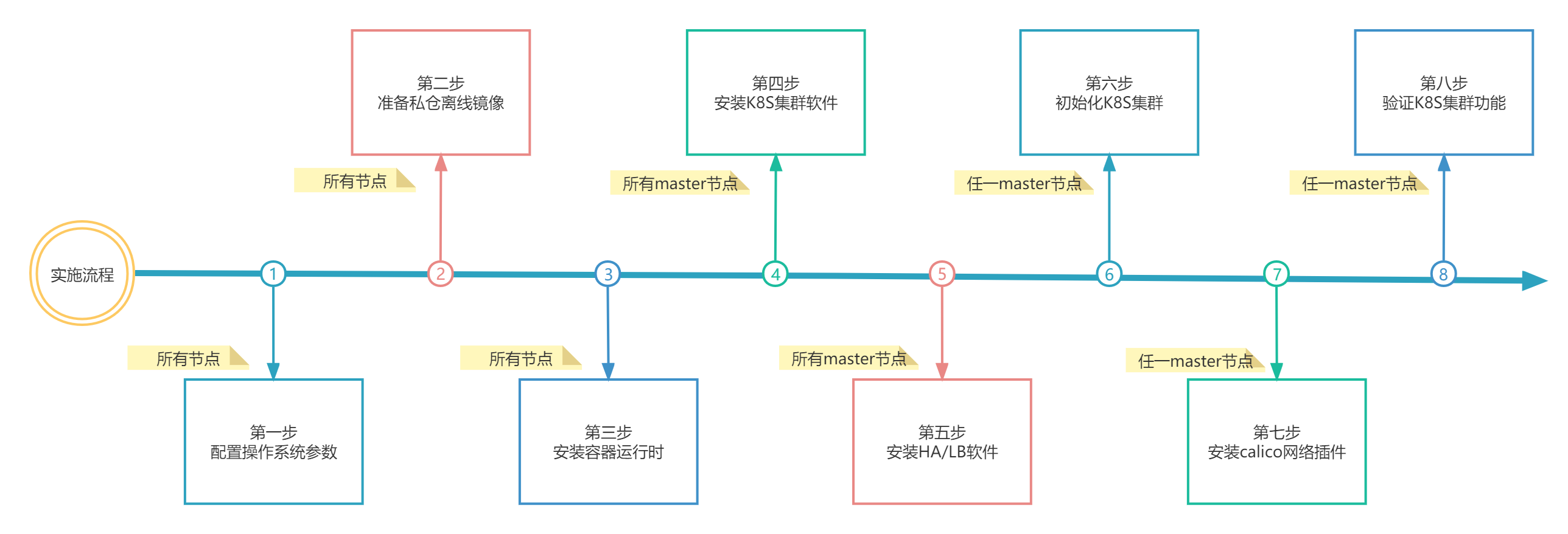
# 部署实操
# 配置操作系统参数
系统配置为初始化配置,在所有 master 和 node 集群节点上进行操作。当所有配置完成之后,重启主机操作系统。如果是虚拟机,可择机拍照备用。
# 设置IP地址
参照下面的命令,分别调整所有主机IP地址,并执行 reboot 命令重启操作系统。
# k8s-vip - 备用 虚拟IP地址无需设置
nmcli con mod enp0s18 ipv4.gateway 192.168.100.1 ipv4.dns 192.168.100.254,202.98.198.167 ipv4.method manual ipv4.address 192.168.100.60/24
nmcli con mod enp0s18 ipv6.gateway fe80::1 ipv6.dns fe80::1 ipv6.method manual ipv6.address 240e:338:813:e4b1::a9c1:c060/64
hostnamectl set-hostname k8s-vip
# k8s-m1
nmcli con mod enp0s18 ipv4.gateway 192.168.100.1 ipv4.dns 192.168.100.254,202.98.198.167 ipv4.method manual ipv4.address 192.168.100.61/24
nmcli con mod enp0s18 ipv6.gateway fe80::1 ipv6.dns fe80::1 ipv6.method manual ipv6.address 240e:338:813:e4b1::a9c1:c061/64
hostnamectl set-hostname k8s-m1
# k8s-m2
nmcli con mod enp0s18 ipv4.gateway 192.168.100.1 ipv4.dns 192.168.100.254,202.98.198.167 ipv4.method manual ipv4.address 192.168.100.62/24
nmcli con mod enp0s18 ipv6.gateway fe80::1 ipv6.dns fe80::1 ipv6.method manual ipv6.address 240e:338:813:e4b1::a9c1:c062/64
hostnamectl set-hostname k8s-m2
# k8s-m3
nmcli con mod enp0s18 ipv4.gateway 192.168.100.1 ipv4.dns 192.168.100.254,202.98.198.167 ipv4.method manual ipv4.address 192.168.100.63/24
nmcli con mod enp0s18 ipv6.gateway fe80::1 ipv6.dns fe80::1 ipv6.method manual ipv6.address 240e:338:813:e4b1::a9c1:c063/64
hostnamectl set-hostname k8s-m3
# k8s-n1
nmcli con mod enp0s18 ipv4.gateway 192.168.100.1 ipv4.dns 192.168.100.254,202.98.198.167 ipv4.method manual ipv4.address 192.168.100.64/24
nmcli con mod enp0s18 ipv6.gateway fe80::1 ipv6.dns fe80::1 ipv6.method manual ipv6.address 240e:338:813:e4b1::a9c1:c064/64
hostnamectl set-hostname k8s-n1
# k8s-n2
nmcli con mod enp0s18 ipv4.gateway 192.168.100.1 ipv4.dns 192.168.100.254,202.98.198.167 ipv4.method manual ipv4.address 192.168.100.65/24
nmcli con mod enp0s18 ipv6.gateway fe80::1 ipv6.dns fe80::1 ipv6.method manual ipv6.address 240e:338:813:e4b1::a9c1:c065/64
hostnamectl set-hostname k8s-n2
# k8s-n3
nmcli con mod enp0s18 ipv4.gateway 192.168.100.1 ipv4.dns 192.168.100.254,202.98.198.167 ipv4.method manual ipv4.address 192.168.100.66/24
nmcli con mod enp0s18 ipv6.gateway fe80::1 ipv6.dns fe80::1 ipv6.method manual ipv6.address 240e:338:813:e4b1::a9c1:c066/64
hostnamectl set-hostname k8s-n3
# harbor
nmcli con mod enp0s18 ipv4.gateway 192.168.100.1 ipv4.dns 192.168.100.254,202.98.198.167 ipv4.method manual ipv4.address 192.168.100.67/24
nmcli con mod enp0s18 ipv6.gateway fe80::1 ipv6.dns fe80::1 ipv6.method manual ipv6.address 240e:338:813:e4b1::a9c1:c067/64
hostnamectl set-hostname harbor
# 更新系统
bash multi-configure-repos-desktop-vnc.sh
# 执行系统组件更新
yum update -y
# 重启操作系统并且移除老旧内核,以期节省磁盘空间。
rpm -qa|grep -E '^kernel'|grep -Ev "$(uname -r)|firmware|kernel-srpm-macros" | xargs -rp yum remove -y
# 安装依赖
使用脚本按照菜单提示,输入 5 并回车,进行常用依赖安装。
bash multi-configure-repos-desktop-vnc.sh
其余依赖安装
yum install -y ipset ipvsadm libseccomp jq curl wget vim bash-completion \
psmisc net-tools nfs-utils telnet yum-utils \
device-mapper-persistent-data lvm2 git tar network-scripts \
sysstat conntrack libseccomp sshpass
# 关闭selinux
使用脚本按照菜单提示,输入 8 并回车,配置 OS常规参数。此操作将自动关闭 selinux 并禁止开机自启。
bash multi-configure-repos-desktop-vnc.sh
或手动操作
setenforce 0
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
# 使用以下两个命令检查当前 selinux 状态 结果为 disabled 即修改成功
sestatus
getenforce
# 关闭firewalld
使用脚本按照菜单提示,输入 8 并回车,配置 OS常规参数。此操作将自动关闭 firewalld 并禁止开机自启。
当 k8s 集群部署完毕之后,可根据需要配置和开启 firewalld。
bash multi-configure-repos-desktop-vnc.sh
或手动操作
systemctl stop firewalld; systemctl disable firewalld; systemctl status firewalld
# 设置hostname
使用脚本按照菜单提示,输入 8 并回车,根据操作提示自动设置。
bash multi-configure-repos-desktop-vnc.sh
或者手动执行
# 在所有节点上按需修改主机名
hostnamectl set-hostname <当前节点主机名>
# 设置hosts
# 删除所有 192.168.100 开头的本地解析设置
sed -i '/^192.168.100.*/d' /etc/hosts
cat >> /etc/hosts << EOF
192.168.100.60 k8s-vip vip.upx.plus
192.168.100.61 k8s-m1
192.168.100.62 k8s-m2
192.168.100.63 k8s-m3
192.168.100.64 k8s-n1
192.168.100.65 k8s-n2
192.168.100.66 k8s-n3
EOF
# 关闭swap
为了提升性能,k8s 默认禁止使用 swap 交换分区。kubeadm 初始化时会检测 swap 是否关闭,如果未关闭,则初始化失败。
swapoff -a
sed -ri 's/.*swap.*/# &/' /etc/fstab
# 开启ipvs
不开启 ipvs 将会使用 iptables 进行数据包转发,效率低,所以官网推荐使用 ipvs。
ipvs (IP Virtual Server) 实现了传输层负载均衡,ipvs 运行在主机上,在真实服务器集群前充当负载均衡器。ipvs 可以将基于 TCP 和 UDP 的服务请求转发到真实服务器上,并使真实服务器的服务在单个 IP地址上显示为虚拟服务。
kube-proxy支持 iptables 和 ipvs 两种模式。 iptables 就是 kube-proxy 默认的操作模式,ipvs 和 iptables 都是基于 netfilter 的,但是 ipvs 采用的是hash 表,因此当 service 数量达到一定规模时,hash 查表的速度优势就会显现出来,从而提高 service 的服务性能。
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in ${ipvs_modules}; do
/sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1
if [ 0 -eq 0 ]; then /sbin/modprobe ${kernel_module}; fi
done
lsmod | grep ip_vs
或
# yum install ipvsadm ipset sysstat conntrack libseccomp -y
cat >> /etc/modules-load.d/ipvs.conf <<EOF
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
EOF
systemctl restart systemd-modules-load.service
lsmod | grep -e ip_vs -e nf_conntrack
附:使用 iptables 转发流量时的配置。使用 ipvs 时略过此步骤。
# 转发 IPv4 并让 iptables 看到桥接流量
cat << EOF | tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
modprobe overlay
modprobe br_netfilter
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sysctl --system
# 确认系统变量在 sysctl 配置中是否被设置为 1
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
# 确认 br_netfilter 和 overlay 模块被加载
lsmod | grep br_netfilter; lsmod | grep overlay
# 优化limit
# limit 优化
ulimit -SHn 65535
cat >> /etc/security/limits.conf <<EOF
* soft nofile 655360
* hard nofile 131072
* soft nproc 655350
* hard nproc 655350
* soft memlock unlimited
* hard memlock unlimited
EOF
# 优化内核
cat <<'EOF' > /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
fs.may_detach_mounts = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_timestamps = 0
net.core.somaxconn = 16384
net.ipv6.conf.all.disable_ipv6 = 0
net.ipv6.conf.default.disable_ipv6 = 0
net.ipv6.conf.lo.disable_ipv6 = 0
net.ipv6.conf.all.forwarding = 1
EOF
# 即时生效
sysctl --system
# 清除邮件提示
# 清除 "您在 /var/spool/mail/root 中有新邮件"信息
echo "unset MAILCHECK" >> /etc/profile
source /etc/profile
# 清空邮箱数据站空间
cat /dev/null > /var/spool/mail/root
# 时间同步配置
局域网的话最好是有时间服务器。互联网的话使用公共的时间服务器即可。
将所有节点服务器时区设置为中国标准时间。
timedatectl set-timezone Asia/Shanghai
如有必要,使用以下命令进行NTP时钟同步可实现服务器时间校准。
yum install -y ntpdate
ntpdate cn.pool.ntp.org
# 网络配置
本文环境使用 calico,所以指定不由 NetworkManager 管理的设备。
# redhat 系列操作系统执行
# interface-name:cali*
# 表示以 "cali" 开头的接口名称被排除在 NetworkManager 管理之外。例如,"cali0", "cali1" 等接口不受 NetworkManager 管理。
# interface-name:tunl*
# 表示以 "tunl" 开头的接口名称被排除在 NetworkManager 管理之外。例如,"tunl0", "tunl1" 等接口不受 NetworkManager 管理。
cat > /etc/NetworkManager/conf.d/calico.conf << EOF
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*;interface-name:vxlan.calico;interface-name:vxlan-v6.calico;interface-name:wireguard.cali;interface-name:wg-v6.cali
EOF
systemctl restart NetworkManager
# 配置免密登录
配置 master 节点之间的 ssh 免密登录。
在中控机上执行,当前环境为 k8s-m1 这台主机。
yum install -y sshpass
ssh-keygen -f /root/.ssh/id_rsa -P ''
export ipList="192.168.100.61 192.168.100.62 192.168.100.63 192.168.100.64 192.168.100.65 192.168.100.66"
# 此处的 110110 为主机的 root 帐号登录密码 为了方便 所有服务器设置为相同的密码
export SSHPASS=110110
for host in $ipList; do sshpass -e ssh-copy-id -o StrictHostKeyChecking=no $host; done
验证免密钥登录是否成功。
ssh root@192.168.100.61
ssh root@192.168.100.62
ssh root@192.168.100.63
# 准备私仓离线镜像
大致处理过程如下:
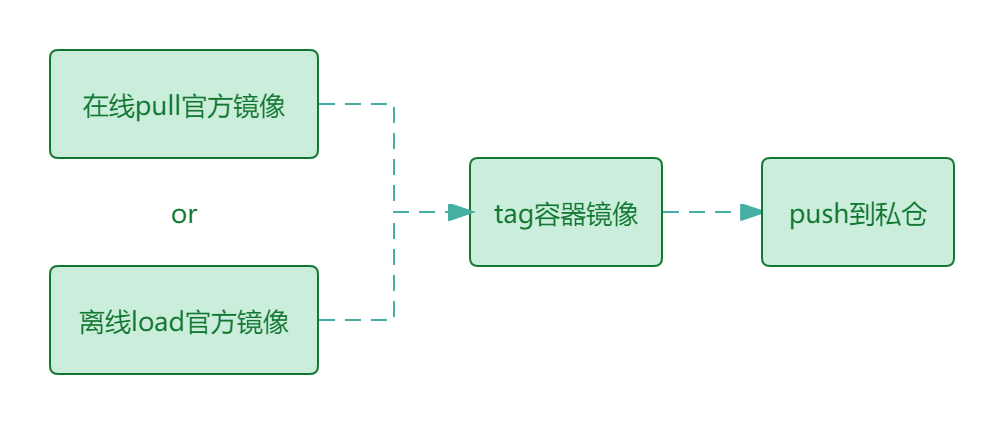
采用官方源或国内源在线安装的方式部署则跳过本节内容。
私有镜像仓库部署文档参考:
从官方下载以下离线容器镜像文件:kubernetes-server-linux-amd64.tar.gz
# load/import
- 使用containerd时
# 以部署 K8S 高可用集群所需的镜像 + calico 网络插件 为例
list=(
coredns-v1.10.1.tgz
etcd-3.5.9-0.tgz
kube-apiserver.tar
kube-controller-manager.tar
kube-proxy.tar
kube-scheduler.tar
pause-3.9.tgz
calico-cni.tar
calico-node.tar
calico-kube-controllers.tar
)
for x in "${list[@]}"; do ctr i import --platform amd64 "${x}"; done
- 使用docker时
# 以部署 K8S 高可用集群所需的镜像 + calico 网络插件 为例
list=(
coredns-v1.10.1.tgz
etcd-3.5.9-0.tgz
kube-apiserver.tar
kube-controller-manager.tar
kube-proxy.tar
kube-scheduler.tar
pause-3.9.tgz
calico-cni.tar
calico-node.tar
calico-kube-controllers.tar
)
for x in "${list[@]}"; do docker load -i "${x}"; done
# tag
docker tag registry.k8s.io/kube-apiserver-amd64:v1.28.3 r.upx.plus/k8s/kube-apiserver:v1.28.3
docker tag registry.k8s.io/kube-controller-manager-amd64:v1.28.3 r.upx.plus/k8s/kube-controller-manager:v1.28.3
docker tag registry.k8s.io/kube-scheduler-amd64:v1.28.3 r.upx.plus/k8s/kube-scheduler:v1.28.3
docker tag registry.k8s.io/kube-proxy-amd64:v1.28.3 r.upx.plus/k8s/kube-proxy:v1.28.3
docker tag calico/kube-controllers:v3.26.3 r.upx.plus/calico/kube-controllers:v3.26.3
docker tag calico/cni:v3.26.3 r.upx.plus/calico/cni:v3.26.3
docker tag calico/node:v3.26.3 r.upx.plus/calico/node:v3.26.3
docker tag registry.k8s.io/etcd:3.5.9-0 r.upx.plus/k8s/etcd:3.5.9-0
docker tag registry.k8s.io/coredns/coredns:v1.10.1 r.upx.plus/k8s/coredns:v1.10.1
docker tag registry.k8s.io/pause:3.9 r.upx.plus/k8s/pause:3.9
# push
docker push r.upx.plus/calico/cni:v3.26.3
docker push r.upx.plus/calico/kube-controllers:v3.26.3
docker push r.upx.plus/calico/node:v3.26.3
docker push r.upx.plus/k8s/coredns:v1.10.1
docker push r.upx.plus/k8s/etcd:3.5.9-0
docker push r.upx.plus/k8s/kube-apiserver:v1.28.3
docker push r.upx.plus/k8s/kube-controller-manager:v1.28.3
docker push r.upx.plus/k8s/kube-proxy:v1.28.3
docker push r.upx.plus/k8s/kube-scheduler:v1.28.3
docker push r.upx.plus/k8s/pause:3.9
# del
docker rmi -f r.upx.plus/calico/cni:v3.26.3
docker rmi -f r.upx.plus/calico/kube-controllers:v3.26.3
docker rmi -f r.upx.plus/calico/node:v3.26.3
docker rmi -f r.upx.plus/k8s/coredns:v1.10.1
docker rmi -f r.upx.plus/k8s/etcd:3.5.9-0
docker rmi -f r.upx.plus/k8s/kube-apiserver:v1.28.3
docker rmi -f r.upx.plus/k8s/kube-controller-manager:v1.28.3
docker rmi -f r.upx.plus/k8s/kube-proxy:v1.28.3
docker rmi -f r.upx.plus/k8s/kube-scheduler:v1.28.3
docker rmi -f r.upx.plus/k8s/pause:3.9
docker rmi -f registry.k8s.io/kube-apiserver-amd64:v1.28.3
docker rmi -f registry.k8s.io/kube-controller-manager-amd64:v1.28.3
docker rmi -f registry.k8s.io/kube-scheduler-amd64:v1.28.3
docker rmi -f registry.k8s.io/kube-proxy-amd64:v1.28.3
docker rmi -f calico/kube-controllers:v3.26.3
docker rmi -f calico/cni:v3.26.3
docker rmi -f calico/node:v3.26.3
docker rmi -f registry.k8s.io/etcd:3.5.9-0
docker rmi -f registry.k8s.io/coredns:v1.10.1
docker rmi -f registry.k8s.io/pause:3.9
# pull
docker pull r.upx.plus/calico/cni:v3.26.3
docker pull r.upx.plus/calico/kube-controllers:v3.26.3
docker pull r.upx.plus/calico/node:v3.26.3
docker pull r.upx.plus/k8s/coredns:v1.10.1
docker pull r.upx.plus/k8s/etcd:3.5.9-0
docker pull r.upx.plus/k8s/kube-apiserver:v1.28.3
docker pull r.upx.plus/k8s/kube-controller-manager:v1.28.3
docker pull r.upx.plus/k8s/kube-proxy:v1.28.3
docker pull r.upx.plus/k8s/kube-scheduler:v1.28.3
docker pull r.upx.plus/k8s/pause:3.9
# 安装容器运行时
# 二进制包下载及安装
注意:本环境基于 containerd 而不是 docker。并且采用二进制包的方式进行安装部署。
为了在 Pod 中运行容器,Kubernetes 使用 容器运行时(Container Runtime)。
Kubernetes 默认使用 容器运行时接口(Container Runtime Interface,CRI)来与容器运行时交互。
从官方地址下载最新的版本。注意匹配对应的平台架构。
# 在 containerd 2.0.0 版本发布之前 建议下载 cri-containerd-cni-1.7.8-linux-amd64.tar.gz 主要是自带的目录结构让人省心
# cri-containerd-xxx 版本解压后默认包含runc,但缺乏相关依赖且不一定是最新的版本 所以使用 runc.amd64 替换包自带的 runc
wget https://github.com/containerd/containerd/releases/download/v1.7.8/cri-containerd-cni-1.7.8-linux-amd64.tar.gz
wget https://github.com/opencontainers/runc/releases/download/v1.1.10/runc.amd64
wget https://github.com/containernetworking/plugins/releases/download/v1.3.0/cni-plugins-linux-amd64-v1.3.0.tgz
上传3个文件到所有集群节点主机上后分别解压。首先解压 cri-containerd-cni,然后对于 cni 和 runc 采用最新版本的独立二进制文件进行覆盖替换。
- 使用 cri-containerd-cni-1.7.8-linux-amd64.tar.gz + cni-plugins-linux-amd64-v1.3.0.tgz + runc.amd64 时
# 使用 cri-containerd-cni-1.7.8-linux-amd64.tar.gz + cni-plugins-linux-amd64-v1.3.0.tgz + runc.amd64 时
tar -xf cri-containerd-cni-1.7.8-linux-amd64.tar.gz -C /
mkdir -p /opt/cni/bin && tar -xf cni-plugins-linux-amd64-v1.3.0.tgz -C /opt/cni/bin
\cp runc.amd64 /usr/local/sbin/runc && chmod +x /usr/local/sbin/runc && runc -v
- 使用 containerd-1.7.8-linux-amd64.tar.gz + cni-plugins-linux-amd64-v1.3.0.tgz + runc.amd64 时
# 使用 containerd-1.7.8-linux-amd64.tar.gz + cni-plugins-linux-amd64-v1.3.0.tgz + runc.amd64 时
tar -xf containerd-1.7.8-linux-amd64.tar.gz -C /usr/local
tar -xf cni-plugins-linux-amd64-v1.3.0.tgz -C /usr/local/bin
# tar -xf cni-plugins-linux-amd64-v1.3.0.tgz -C /opt/cni/bin
\cp runc.amd64 /usr/local/sbin/runc && chmod +x /usr/local/sbin/runc && runc -v
安装 cri-tools - 必需
# cri-tools
# https://github.com/kubernetes-sigs/cri-tools/releases
# wget https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.28.0/crictl-v1.28.0-linux-amd64.tar.gz
tar -xf crictl-v1.28.0-linux-amd64.tar.gz -C /usr/local/bin
cat > /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
cat > /etc/crictl.yaml << 'EOF'
runtime-endpoint: unix:///run/containerd/containerd.sock
EOF
安装 nerdctl - 可选
# nerdctl
# https://github.com/containerd/nerdctl/releases
# nerdctl-1.7.0-linux-amd64.tar.gz 不包含依赖
# nerdctl-full-1.7.0-linux-amd64.tar.gz 包含所有依赖
# wget https://github.com/containerd/nerdctl/releases/download/v1.7.0/nerdctl-1.7.0-linux-amd64.tar.gz
tar -xf nerdctl-1.7.0-linux-amd64.tar.gz -C /usr/local/bin nerdctl
添加环境变量 - 按需
# 按需添加环境变量
# echo 'export PATH=/usr/local/bin:/usr/local/sbin:/opt/cni/bin:$PATH' >> /etc/profile
echo 'export PATH=/usr/local/bin:/usr/local/sbin:$PATH' >> /etc/profile
source /etc/profile
# 配置 containerd 所需模块
cat <<EOF | tee /etc/modules-load.d/containerd.conf
overlay
br_netfilter
EOF
systemctl restart systemd-modules-load
# 配置 containerd 所需内核
cat <<EOF | tee /etc/sysctl.d/99-kubernetes-cri.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
# 修改 containerd 配置文件
# 生成默认配置文件
mkdir -p /etc/containerd && containerd config default > /etc/containerd/config.toml
# 修改 sandbox_image
# 将 3.8 修改为 3.9
vim /etc/containerd/config.toml
# sandbox_image = "registry.k8s.io/pause:3.9"
# 修改前后查询
grep -E 'sandbox_image' /etc/containerd/config.toml
# 或使用以下命令直接修改
sed -i 's%sandbox_image = "registry.k8s.io/pause:3.8"%sandbox_image = "registry.k8s.io/pause:3.9"%' /etc/containerd/config.toml
# sed -i 's%sandbox_image = "registry.k8s.io/pause:3.8"%sandbox_image = "r.upx.plus/k8s/pause:3.9"%' /etc/containerd/config.toml
如果使用本地私有镜像仓库,记得把官方地址也一起改为私仓地址。例如:sandbox_image = "r.upx.plus/k8s/pause:3.9"。否则会有如下警告信息:
detected that the sandbox image "registry.k8s.io/pause:3.9" of the container runtime is inconsistent with that used by kubeadm. It is recommended that using "r.upx.plus/k8s/pause:3.9" as the CRI sandbox image.
# 修改 SystemdCgroup
# 编辑配置文件,修改如下配置
vim /etc/containerd/config.toml
# 使用 systemd 作为 Cgroup 的驱动程序
# SystemdCgroup = true
# 或者执行以下命令直接修改
# 修改前后查询
grep -E 'SystemdCgroup' /etc/containerd/config.toml
# 执行修改
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
# yq 可读取 toml 文件
yq '.plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options.SystemdCgroup' /etc/containerd/config.toml
# yq 暂不完全支持 toml 文件的编辑
# yq '.plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options.SystemdCgroup="true"' /etc/containerd/config.toml
# Error: only scalars (e.g. strings, numbers, booleans) are supported for TOML output at the moment. Please use yaml output format (-oy) until the encoder has been fully implemented.
# 创建服务控制文件
若使用 cri-containerd 或 cri-containerd-cni 二进制包时已自带服务控制文件,则不需要执行这一步。
cat > /etc/systemd/system/containerd.service << 'EOF'
# Copyright The containerd Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target
[Service]
#uncomment to enable the experimental sbservice (sandboxed) version of containerd/cri integration
#Environment="ENABLE_CRI_SANDBOXES=sandboxed"
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/local/bin/containerd
Type=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=infinity
# Comment TasksMax if your systemd version does not supports it.
# Only systemd 226 and above support this version.
TasksMax=infinity
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target
EOF
这里有两个重要的参数:
Delegate:允许 containerd 以及运行时自己管理自己创建容器的 cgroups。如果不设置这个选项,systemd 就会将进程移到自己的 cgroups 中,从而导致 containerd 无法正确获取容器的资源使用情况。
KillMode:用来处理 containerd 进程被杀死的方式。默认情况下,systemd 会在进程的 cgroup 中查找并杀死 containerd 的所有子进程。
# 设置开机自启并立即启动
systemctl daemon-reload && systemctl enable \--now containerd
# 相关服务管理命令
# 查看状态
systemctl status containerd
# 关闭服务
systemctl stop containerd
# 重启服务
systemctl restart containerd
# 查看版本信息
containerd -version
ctr version
crictl --version
/opt/cni/bin/host-local
# 容器相关的数据持久化保存位置
containerd 默认在 /var/lib/containerd
docker 默认在 /var/lib/docker
# 安装k8s集群软件
采用官方推荐的工具 kubeadm 来部署 k8s 集群。
# 安装前注意事项
每个节点主机上都需要安装以下软件包:
kubeadm:用来初始化集群的指令。
kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
kubectl:用来与集群通信的命令行工具。
kubeadm 不能安装或者管理 kubelet 或 kubectl,所以务必确保它们与通过 kubeadm 安装的控制平面的版本相匹配。
所有节点主机的 CPU/Mem 配置不低于 2C/2G
集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)。
节点之中不可以有重复的主机名、MAC 地址或 product_uuid。
开启机器上的某些端口。
禁用交换分区。
# 校验 product_uuid
cat /sys/class/dmi/id/product_uuid
# 检查 port
nc 127.0.0.1 6443
# 使用k8s仓库在线安装
cat << EOF | tee /etc/yum.repos.d/k8s.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
# 安装 kubelet、kubeadm 和 kubectl,并启用 kubelet 以确保它在启动时自动启动
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
systemctl enable --now kubelet
# 安装特定版本并且不检查 gpg 时 可使用以下命令
yum install kubelet-1.28.3 kubeadm-1.28.3 kubectl-1.28.3 --nogpgcheck -y
# 只下载不安装
yum install -y --downloadonly --downloaddir=/seeyon/scripts kubernetes-cni cri-tools kubelet kubeadm kubectl --disableexcludes=kubernetes
yum remove -y kubernetes-cni cri-tools kubelet kubeadm kubectl --disableexcludes=kubernetes
# 使用二进制包离线安装
使用此方式安装时,需要创建 kubelet 的服务控制文件。
# kubectl
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
curl -LO "https://dl.k8s.io/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl.sha256"
echo "$(cat kubectl.sha256) kubectl" | sha256sum --check
# kubeadm
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubeadm"
curl -LO "https://dl.k8s.io/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubeadm.sha256"
echo "$(cat kubeadm.sha256) kubeadm" | sha256sum --check
# kubelet
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubelet"
curl -LO "https://dl.k8s.io/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubelet.sha256"
echo "$(cat kubelet.sha256) kubelet" | sha256sum --check
# 下载指定版本使用以下命令 将 1.28.3 替换为需要下载的版本
curl -LO https://dl.k8s.io/release/v1.28.3/bin/linux/amd64/kubectl
# 安装到 /usr/local/bin 或 /usr/bin
install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
install -o root -g root -m 0755 kubeadm /usr/local/bin/kubeadm
install -o root -g root -m 0755 kubelet /usr/local/bin/kubelet
# 授权
chmod +x /usr/local/bin/kubectl
chmod +x /usr/local/bin/kubeadm
chmod +x /usr/local/bin/kubelet
# 创建 kubelet 服务控制文件
# 注意调整 kubelet 的路径 二进制的路径是 /usr/local/bin/kubelet 如果是 RPM 的可能就是 /usr/bin/kubelet
cat > /etc/systemd/system/kubelet.service << 'EOF'
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=https://kubernetes.io/docs/
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/local/bin/kubelet
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload; systemctl enable --now kubelet
# 使用 kubernetes-server-linux-amd64.tar.gz 时
# 下载安装包
# wget https://github.com/etcd-io/etcd/releases/download/v3.5.10/etcd-v3.5.10-linux-amd64.tar.gz
# wget https://storage.googleapis.com/kubernetes-release/release/v1.28.3/kubernetes-server-linux-amd64.tar.gz
# wget https://dl.k8s.io/v1.28.3/kubernetes-server-linux-amd64.tar.gz
# wget https://dl.k8s.io/v1.28.3/kubernetes-client-linux-amd64.tar.gz
# 解压 kubernetes-server-linux-amd64.tar.gz 文件,并将其中的特定文件提取到 /usr/local/bin 目录下
tar -xf kubernetes-server-linux-amd64.tar.gz --strip-components=3 -C /usr/local/bin kubernetes/server/bin/kube{adm,let,ctl,-apiserver,-controller-manager,-scheduler,-proxy}
# 解压 etcd-v3.5.10-linux-amd64.tar.gz 文件,并将其中的特定文件提取到 /usr/local/bin 目录下
tar -xf etcd-v3.5.10-linux-amd64.tar.gz --strip-components=1 -C /usr/local/bin etcd-v3.5.10-linux-amd64/{etcd,etcdctl,etcdutl}
# 查看版本信息
# 查看版本
kubectl version --client
kubectl version --client --output=yaml
kubectl version
kubeadm version
kubelet --version
# 配置kubelet
# 容器运行时为 docker 时,为了实现 docker 使用的 cgroupdriver 与 kubelet 使用的 cgroup 的一致性,建议修改如下文件内容
vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
# 或使用命令直接修改
sed -i 's/^KUBELET_EXTRA_ARGS.*/KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"/' /etc/sysconfig/kubelet
# 手动下载二进制包安装的可能需要创建此文件
echo 'KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"' >> /etc/sysconfig/kubelet
# 卸载k8s和containerd
卸载前,删除所有镜像,停服务......
systemctl stop kubelet containerd
rm -rf /usr/local/{bin,sbin}/*
rm -rf /etc/kubernetes/
rm -rf /etc/crictl.yaml
rm -f /etc/containerd/config.toml
rm -f /etc/systemd/system/containerd.service
rm -rf /etc/cni
# 安装HA/LB软件
负载均衡配置的官方文档:https://github.com/kubernetes/kubeadm/blob/main/docs/ha-considerations.md#options-for-software-load-balancing
# 安装 keepalived 和 tengine 软件
所有 master 主机安装 keepalived + haproxy + tengine。
keepalived:提供 HA 功能。使用系统自带版本。
haproxy:提供 K8S 集群的6443端口的 LB 功能。使用系统自带版本。
tengine:对外部服务提供反向代理的功能。 采用源码编译的最新版本。
# 安装 keepalived 和 haproxy 之后先不启动,先修改配置文件。
yum install -y keepalived haproxy
# 安装 tengine
bash multi-install-nginx.sh tengine
# 调整 keepalived 和 tengine 的配置
提示:不要使用 script "killall 0 haproxy" 而是使用 script "/usr/bin/pgrep haproxy"
# k8s-m1 的 keepalived 配置文件
cat > /etc/keepalived/keepalived.conf << 'EOF'
! Configuration File for keepalived
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "/usr/bin/pgrep haproxy"
interval 2
timeout 1
weight 2
}
vrrp_instance k8s-vip {
state BACKUP
priority 100
interface enp0s18 # Network card
virtual_router_id 60
advert_int 1
authentication {
auth_type PASS
auth_pass myAuth-0
}
unicast_src_ip 192.168.100.61 # The IP address of this machine
unicast_peer {
192.168.100.62 # Node 2's IP address
192.168.100.63 # Node 3's IP address
}
virtual_ipaddress {
192.168.100.60/24 # The VIP address
}
track_script {
chk_haproxy
}
}
EOF
# k8s-m2 的 keepalived 配置文件
cat > /etc/keepalived/keepalived.conf << 'EOF'
! Configuration File for keepalived
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "/usr/bin/pgrep haproxy"
interval 2
timeout 1
weight 2
}
vrrp_instance k8s-vip {
state BACKUP
priority 100
interface enp0s18 # Network card
virtual_router_id 60
advert_int 1
authentication {
auth_type PASS
auth_pass myAuth-0
}
unicast_src_ip 192.168.100.62 # The IP address of this machine
unicast_peer {
192.168.100.61 # Node 1's IP address
192.168.100.63 # Node 3's IP address
}
virtual_ipaddress {
192.168.100.60/24 # The VIP address
}
track_script {
chk_haproxy
}
}
EOF
# k8s-m3 的 keepalived 配置文件
cat > /etc/keepalived/keepalived.conf << 'EOF'
! Configuration File for keepalived
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "/usr/bin/pgrep haproxy"
interval 2
timeout 1
weight 2
}
vrrp_instance k8s-vip {
state BACKUP
priority 100
interface enp0s18 # Network card
virtual_router_id 60
advert_int 1
authentication {
auth_type PASS
auth_pass myAuth-0
}
unicast_src_ip 192.168.100.63 # The IP address of this machine
unicast_peer {
192.168.100.61 # Node 1's IP address
192.168.100.62 # Node 2's IP address
}
virtual_ipaddress {
192.168.100.60/24 # The VIP address
}
track_script {
chk_haproxy
}
}
EOF
# 所有 master 节点的 haproxy 配置文件
无论是 haproxy 还是 nginx 都注意不要与 K8S 的 6443 端口冲突。
cat > /etc/haproxy/haproxy.cfg <<'EOF'
global
log /dev/log local0 warning
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
frontend kube-apiserver
bind *:9443
mode tcp
option tcplog
default_backend kube-apiserver
backend kube-apiserver
mode tcp
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server kube-apiserver-1 192.168.100.61:6443 check # Replace the IP address with your own.
server kube-apiserver-2 192.168.100.62:6443 check # Replace the IP address with your own.
server kube-apiserver-3 192.168.100.63:6443 check # Replace the IP address with your own.
EOF
# 所有 master 节点的 nginx 配置文件
如果不使用 haproxy 而是使用 nginx 做 K8S 的 6443 端口的负载均衡时,可使用以下配置。
cat > /apps/nginx/conf.d/stream/k8s.conf << 'EOF'
upstream backend {
server 192.168.100.61:6443 max_fails=3 fail_timeout=30s;
server 192.168.100.62:6443 max_fails=3 fail_timeout=30s;
server 192.168.100.63:6443 max_fails=3 fail_timeout=30s;
}
server {
listen 9443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
EOF
# 记得还需要把 include /apps/nginx/conf.d/stream/k8s.conf; 添加到 stream 代码段。
# 启动并检查服务
systemctl daemon-reload
systemctl enable --now keepalived haproxy nginx
systemctl status keepalived haproxy nginx
systemctl restart keepalived
systemctl restart haproxy
systemctl restart nginx
# 使用以下命令 在 3 个 master 节点上观察节点的 vip 接管情况
ip a s enp0s18
# 检查端口使用情况
netstat -lntup|grep haproxy
netstat -lntup|grep nginx
# 测试高可用是否生效
# 关闭主节点 k8s-m1,检查 vip 是否漂移到备节点
# 我这里直接把 k8s-m1/k8s-m2 依次关机做测试
# halt -p
# 能 ping 通
ping 192.168.100.60
# 能 telnet 通 由于 API 服务器尚未运行,预期会出现一个连接拒绝错误。 然而超时意味着负载均衡器不能和控制平面节点通信。
telnet 192.168.100.60 9443
# 初始化K8S集群
# 创建初始化配置文件
kubeadm config print init-defaults > kubeadm-init.yaml
# 初始化前预拉取镜像
拉取镜像有多种方式,离线导入官方tar镜像,在线拉取官方镜像,国内镜像源都可以。本文使用自建的私有仓库镜像。
拉取私仓镜像需要调整以下参数:
1、确保配置文件 kubeadm-init.yaml 中 imageRepository 的地址为私仓地址。例如:imageRepository: r.upx.plus/k8s
2、确保配置文件 /etc/containerd/config.toml 中 sandbox_image 的取值为私仓地址。例如:sandbox_image = "r.upx.plus/k8s/pause:3.9"
# 使用默认配置时
kubeadm config images list
kubeadm config images pull
# 使用自定义配置
kubeadm config images list --config kubeadm-init.yaml
kubeadm config images pull --config kubeadm-init.yaml
提示:不管是使用命令直接初始化还是使用配置文件,建议都加上 --upload-certs 参数,否则初始化成功后的提示中不会生成 --control-plane --certificate-key
# 使用配置文件初始化
cat << EOF > kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.100.61
bindPort: 6443
nodeRegistration:
criSocket: unix:///run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: k8s-m1
taints: null
---
apiServer:
timeoutForControlPlane: 3m0s
certSANs:
- 192.168.100.60
- 192.168.100.61
- 192.168.100.62
- 192.168.100.63
- 192.168.100.64
- 192.168.100.65
- 192.168.100.66
- k8s-m1
- k8s-m2
- k8s-m3
- k8s-n1
- k8s-n2
- k8s-n3
- k8s-vip
- cluster.local
- vip.upx.plus
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: k8s-cluster
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: r.upx.plus/k8s
kind: ClusterConfiguration
kubernetesVersion: 1.28.3
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16,2001:db8:42:0::/56
serviceSubnet: 10.96.0.0/12,2001:db8:42:1::/112
scheduler: {}
controlPlaneEndpoint: "192.168.100.60:9443"
# controlPlaneEndpoint: "vip.upx.plus:9443"
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
EOF
# 使用命令直接初始化
# 集群初始化命令行 添加参数 --dry-run 可以模拟运行
# 使用私有仓库时 --image-repository=r.upx.plus/k8s
# 使用阿里云镜像时 --image-repository=registry.aliyuncs.com/google_containers
# 使用阿里云镜像时 --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers
kubeadm init \
--kubernetes-version=1.28.3 \
--cert-dir=/etc/kubernetes/pki \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=Swap \
--upload-certs \
--apiserver-advertise-address="192.168.100.61" \
--apiserver-cert-extra-sans="192.168.100.60,192.168.100.61,192.168.100.62,192.168.100.63,192.168.100.64,192.168.100.65,192.168.100.66,cluster.local,vip.upx.plus,openapi-vip.upx.plus,static-vip.upx.plus" \
--control-plane-endpoint="192.168.100.60:9443" \
--image-repository=r.upx.plus/k8s
记录下成功初始化后如下提示:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.100.60:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:d3d03979290670689d3664b99dc634ec23b008ba24c954f2bbf3155ecff97bcd \
--control-plane --certificate-key 3c02c98ca6e49db74437a2f88fe9d56556aba02fa824fffcd6430b94f514dc87
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.100.60:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:d3d03979290670689d3664b99dc634ec23b008ba24c954f2bbf3155ecff97bcd
# 添加 kube 环境变量
# k8s-1 节点执行,也就是执行 kubeadm init 这台主机
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
# export KUBECONFIG=$HOME/.kube/config
echo 'export KUBECONFIG=$HOME/.kube/config' >> ~/.bashrc
source ~/.bashrc
# 查看集群节点信息
# 此时 status 是 NotReady 是正常的
kubectl get nodes
kubectl get nodes -o wide
watch kubectl get all --all-namespaces -o wide
# 重置 k8s 集群信息
集群初始化失败后,需要重置才能再次进行初始化。
kubeadm reset -f; ipvsadm --clear; rm -rf ~/.kube
# 加入集群节点
分别在 master 和 node 各自节点上执行。
# 其他节点加入集群的命令格式
# kubeadm join --token <token> <master-node-ip>:<master-port>
# kubeadm join --token <token> <node-ip>:<node-port>
# 加入集群节点期间或后续随时可以使用以下命令查看集群节点情况
# kubectl get nodes
# 所有 master 节点
kubeadm join 192.168.100.60:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:d3d03979290670689d3664b99dc634ec23b008ba24c954f2bbf3155ecff97bcd \
--control-plane --certificate-key 3c02c98ca6e49db74437a2f88fe9d56556aba02fa824fffcd6430b94f514dc87
# 所有 master 节点加入成功后 添加 kube 配置
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
# export KUBECONFIG=$HOME/.kube/config
echo 'export KUBECONFIG=$HOME/.kube/config' >> ~/.bashrc
source ~/.bashrc
# 所有 worker 节点
kubeadm join 192.168.100.60:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:d3d03979290670689d3664b99dc634ec23b008ba24c954f2bbf3155ecff97bcd
# 检查节点加入情况
所有节点加入集群后,可在任意 master 节点上检查节点情况。
此时 status 依旧是 NotReady,是因为 pod 网络插件未安装。安装之后就恢复正常了。
kubectl get nodes
# 安装 calico 网络插件
Kubernetes 需要网络插件来提供集群内部和集群外部的网络通信。
常用的 k8s 网络插件主要有:Flannel、Calico、Canal、Cilium、Contiv、Antrea 等等。
各网络插件的功能和对比可参看网络资料:Kubernetes 之7大CNI网络插件用法和对比 (opens new window)。
本环境采用 calico 作为 cni 网络插件。
# 配置 NetworkManager
# 使用 calico,需要指定不由 NetworkManager 管理的设备。
cat > /etc/NetworkManager/conf.d/calico.conf << EOF
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*;interface-name:vxlan.calico;interface-name:vxlan-v6.calico;interface-name:wireguard.cali;interface-name:wg-v6.cali
EOF
systemctl restart NetworkManager
# 调整 kubeproxy 模式为 ipvs
# 编辑 在一个 master 节点执行即可
kubectl edit configmaps kube-proxy -n kube-system
kind: KubeProxyConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
metricsBindAddress: ""
mode: "ipvs"
# 默认这里 mode: "" 是空值 改为 ipvs
<!-- -->
# 重启
kubectl delete pods -n kube-system -l k8s-app=kube-proxy
# 检查
ipvsadm -L -n --stats
# 准备 calico 的 release 包
# 从官网下载 calico-release-v3.26.3.tgz
# 发行包里面已经包含了所有配置文件和离线容器镜像文件。
wget https://github.com/projectcalico/calico/releases/download/v3.26.3/release-v3.26.3.tgz
# 先解压 calico.yaml 文件
tar -xf calico-release-v3.26.3.tgz --strip-components=2 -C ./ release-v3.26.3/manifests/calico.yaml
# 调整 calico.yaml 参数
# 修改 CIDR
vim calico.yaml
# 取消以下注释 修改网段为 kubeadm init 时 --pod-network-cidr 指定的网段 10.244.0.0/16
# - name: CALICO_IPV4POOL_CIDR
# value: "10.244.0.0/16"
grep -A 2 CALICO_IPV4POOL_CIDR calico.yaml
# 指定网卡
# Cluster type to identify the deployment type
- name: CLUSTER_TYPE
value: "k8s,bgp"
# 下面添加
- name: IP_AUTODETECTION_METHOD
value: "interface=enp0s18"
# enp0s18 按需修改为本地网卡名
grep -A 2 IP_AUTODETECTION_METHOD calico.yaml
# 修改镜像拉取地址
如果要联网拉取官方镜像不使用私仓则可跳过此步骤。
grep image calico.yaml
sed -i 's#image: docker.io/calico#image: r.upx.plus/calico#g' calico.yaml
# 使用 kubectl 部署应用
kubectl apply -f calico.yaml
# 检查 calico 的安装情况
kubectl get pod -A
kubectl get pod -n kube-system
# 验证K8S集群功能
# pod状态
[root@k8s-m1 scripts]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6956476c6-ccvhz 1/1 Running 0 8h
kube-system calico-node-2mwrb 1/1 Running 0 8h
kube-system calico-node-5xzlj 1/1 Running 0 8h
kube-system calico-node-b8z4p 1/1 Running 0 8h
kube-system calico-node-j5fmd 1/1 Running 0 8h
kube-system calico-node-jrlwl 1/1 Running 0 8h
kube-system calico-node-xkd2q 1/1 Running 0 8h
kube-system coredns-95cfb6c5b-4tmtc 1/1 Running 0 9h
kube-system coredns-95cfb6c5b-brftn 1/1 Running 0 9h
kube-system etcd-k8s-m1 1/1 Running 2 9h
kube-system etcd-k8s-m2 1/1 Running 0 8h
kube-system etcd-k8s-m3 1/1 Running 0 8h
kube-system kube-apiserver-k8s-m1 1/1 Running 2 9h
kube-system kube-apiserver-k8s-m2 1/1 Running 0 8h
kube-system kube-apiserver-k8s-m3 1/1 Running 0 8h
kube-system kube-controller-manager-k8s-m1 1/1 Running 2 9h
kube-system kube-controller-manager-k8s-m2 1/1 Running 0 8h
kube-system kube-controller-manager-k8s-m3 1/1 Running 0 8h
kube-system kube-proxy-8blvl 1/1 Running 0 7h53m
kube-system kube-proxy-9drpt 1/1 Running 0 7h53m
kube-system kube-proxy-fvffq 1/1 Running 0 7h52m
kube-system kube-proxy-hf9q7 1/1 Running 0 7h53m
kube-system kube-proxy-j89nr 1/1 Running 0 7h52m
kube-system kube-proxy-zpkc4 1/1 Running 0 7h52m
kube-system kube-scheduler-k8s-m1 1/1 Running 2 9h
kube-system kube-scheduler-k8s-m2 1/1 Running 0 8h
kube-system kube-scheduler-k8s-m3 1/1 Running 0 8h
# 节点状态
[root@k8s-m1 scripts]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-m1 Ready control-plane 9h v1.28.3
k8s-m2 Ready control-plane 8h v1.28.3
k8s-m3 Ready control-plane 8h v1.28.3
k8s-n1 Ready <none> 8h v1.28.3
k8s-n2 Ready <none> 8h v1.28.3
k8s-n3 Ready <none> 8h v1.28.3
# 服务状态
[root@k8s-m1 scripts]# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 9h
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 9h
# 问题处理记录
# 推拉镜像报错:tls: failed to verify certificate: x509: certificate signed by unknown authority
按照以下配置修改之后,拉取镜像时,使用 crictl 进行拉取和推送 则不会报错:tls: failed to verify certificate: x509: certificate signed by unknown authority
但使用 ctr 命令进行 pull/push 时不得行,只能使用 --user 和 -k 参数规避。
当 insecure_skip_verify = true 时,不再需要设置 [plugins."io.containerd.grpc.v1.cri".registry.configs."r.upx.plus".auth]。
# 在文件 /etc/containerd/config.toml 中进行调整
vim /etc/containerd/config.toml
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = ""
[plugins."io.containerd.grpc.v1.cri".registry.auths]
[plugins."io.containerd.grpc.v1.cri".registry.configs]
[plugins."io.containerd.grpc.v1.cri".registry.configs."r.upx.plus".tls]
insecure_skip_verify = true # 是否跳过证书认证
ca_file = "/etc/containerd/certs.d/r.upx.plus/ca.cer" # CA 证书
cert_file = "/etc/containerd/certs.d/r.upx.plus/upx.plus.cer" # harbor 证书
key_file = "/etc/containerd/certs.d/r.upx.plus/upx.plus.key" # harbor 私钥
[plugins."io.containerd.grpc.v1.cri".registry.configs."r.upx.plus".auth] # harbor 认证的账号密码 配置
username = "seeyon" # harbor 用户
password = "i4Seeyon" # harbor 密码
# auth = ""
# identitytoken = ""
[plugins."io.containerd.grpc.v1.cri".registry.headers]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugin."io.containerd.grpc.v1.cri".registry.mirrors."r.upx.plus"]
endpoint = ["https://r.upx.plus"] # harbor 自建私有仓库
[plugins."io.containerd.grpc.v1.cri".x509_key_pair_streaming]
tls_cert_file = ""
tls_key_file = ""
mkdir -p /etc/containerd/certs.d/r.upx.plus
mkdir -p /etc/containerd/certs.d/r.upx.plus
# 上传证书文件
# init集群时报错:checkpoint="kubelet_internal_checkpoint" err="checkpoint is not found"
略
# kube-proxy报错:failed complete: unrecognized feature gate: SupportIPVSProxyMode
kubectl logs kube-proxy-z6ps7 -n kube-system
E1112 10:39:18.926558 1 run.go:74] "command failed" err="failed complete: unrecognized feature gate: SupportIPVSProxyMode"
在1.19版本之前,kubeadm部署方式启用ipvs模式时,初始化配置文件需要添加以下内容:
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
如果部署是1.20以上版本,且使用kubeadm进行集群初始化时,虽然可以正常部署,但是查看pod情况的时候可以看到kube-proxy无法运行成功,但是就有了标题的报错。
解决办法:在集群初始化时去掉 featureGates.SupportIPVSProxyMode: true 参数
参考文章:https://www.cnblogs.com/shanhubei/p/17372047.html (opens new window)
由于集群已经初始化成功了,所以现在改kubeadm初始化配置文件没有意义,所以需要直接修改kube-proxy的启动配置。
kubectl edit cm kube-proxy -n kube-system
# 删掉以下两行字段
featureGates:
SupportIPVSProxyMode: true
# 然后删除所有 kube-proxy 进行重启,再查看 pod 运行情况
[root@k8s-m1 scripts]# kubectl delete pod -n kube-system kube-proxy-52fhb
pod "kube-proxy-52fhb" deleted
[root@k8s-m1 scripts]# kubectl delete pod -n kube-system kube-proxy-6dsw5
pod "kube-proxy-6dsw5" deleted
[root@k8s-m1 scripts]# kubectl delete pod -n kube-system kube-proxy-ldkph
pod "kube-proxy-ldkph" deleted
[root@k8s-m1 scripts]# kubectl delete pod -n kube-system kube-proxy-nhzfj
pod "kube-proxy-nhzfj" deleted
[root@k8s-m1 scripts]# kubectl delete pod -n kube-system kube-proxy-wlftd
pod "kube-proxy-wlftd" deleted
[root@k8s-m1 scripts]# kubectl delete pod -n kube-system kube-proxy-z6ps7
# watchpod -n kube-system
# 查看ipvs模式是否启用成功
ipvsadm -Ln
# 其他可能用到的
# 删除当前目录下临时文件
rm -rf \
cni-plugins-linux-amd64-v1.3.0.tgz \
kubectl-1.28.3-150500.1.1.x86_64.rpm \
containerd-1.7.8-linux-amd64.tar.gz \
kubelet-1.28.3-150500.1.1.x86_64.rpm \
cri-tools-1.28.0-150500.1.1.x86_64.rpm \
kubernetes-cni-1.2.0-150500.2.1.x86_64.rpm \
kubeadm-1.28.3-150500.1.1.x86_64.rpm \
runc.amd64
# k8s的版本偏差策略
对于使用 kubectl 管理多套集群时,发现还不能垮大版本进行管理,于是官方扫了一眼。
官方文档:https://kubernetes.io/zh-cn/releases/version-skew-policy (opens new window)
# 使用kubectl管理多集群
快速跳转
