# 智能助理部署配置手册
本手册适用于部署配置“智能助理”下的智能问答、智能办公、智能创作、智能填单应用
2025年3月
# 修订记录
| 修订内容 | 修订时间 |
|---|---|
| 增加信创支持的说明,优化参数配置 | 2025-4-18 |
| 新增DeepSeek的适配及手册 | 2025-3-19 |
# 在线化资料支持
手册存在不定期更新,为了方便您获取最新资料,本手册在致远开放平台也放置了一份,建议您收藏以下地址,并尽量使用在线手册以获得最新的部署信息:https://open.seeyoncloud.com/#/faq/vuepressFile/v1/share?url=Z2ptZkplPjM0NDg= (opens new window)
# 一、环境准备
# 依赖协同版本
本手册适用部署在如下产品版本:
| 版本 | 支持的BuildID | 部署方式 |
|---|---|---|
| V9.0SP1 | B250320.132210.CTP182303072及更高BuildID | 仅支持该版本,不需要打补丁 |
注:智能助理应用已逐步被CoMi新一代智能体平台替代,请优选选择CoMi。
# 适用产品功能
使用如下一个或多个产品功能,需要使用本手册进行部署配置:
| 产品功能 | 商务插件 | 备注 |
|---|---|---|
| 智能问答 | 智能助理-智能问答aiAssistantQandA | 依赖全文检索、aiapp、qdrant、大模型、ocr(选配) |
| 智能办公 | 智能助理-智能办公aiAssistantOffice | 依赖aiapp、qdrant、大模型 |
| 智能填单 | 智能助理-智能填单aiFillOut | 依赖aiapp、qdrant、大模型 |
| 智能创作 | 智能助理-智能创作aiContentCreation | 依赖aiapp、qdrant、大模型 |
注意:
- 部署一套智能问答所需服务,其余智能助理功能就可以直接使用
- 如需使用智能助理下的 模型对话应用,需要参考《模型对话部署配置手册》
- 模型对话和智能问答的区别:模型对话不支持回答系统内知识,智能问答支持回答系统内知识
# 依赖组件
如需使用本手册支持的智能助理应用,涉及如下几个相关组件部署,各自组件的作用及提供方如下:
| 编号 | 组件名 | 组件作用 | 部署模式 | 提供方 |
|---|---|---|---|---|
| 1 | 协同服务-智能助理相关插件 | 提供应用访问入口和交互 | 购买“智能助理”相关插件,更新加密狗 | 致远 |
| 2 | aiapp应用服务 | 扩展服务,需要独立部署,用于将协同业务数据向量化,必须 | 参考本手册安装部署章节 | 致远 |
| 3 | dqrant向量数据库 | 扩展服务,需要独立部署,用于存储协同业务向量数据,必须 | 参考本手册安装部署章节 | 致远 |
| 4 | 全文检索服务 | 扩展服务,协同全文检索功能需要,本场景用于将业务数据推送给aiapp向量化,已经部署全文检索项目不必做任何调整,必须 | 参考协同全文检索部署章节 | 致远 |
| 5 | OCR图片识别服务 | 扩展服务,需要独立部署,用于将协同图片、PDF扫描件等解析成文字,非必须 | 参考本手册安装部署章节 | 致远 |
| 6 | 三方大模型 | DeepSeek、千问等大语言模型,用于接收问题并通过模型内部运算给出问题回复 | 客户自行准备 | 客户 |
注意:
- OCR图片识别服务,非必须,如未部署,协同内图片无法被解析成文字给aiapp
- 对部分CPU型号兼容性较差,目前测试在以下两个cpu架构上可以正常运行
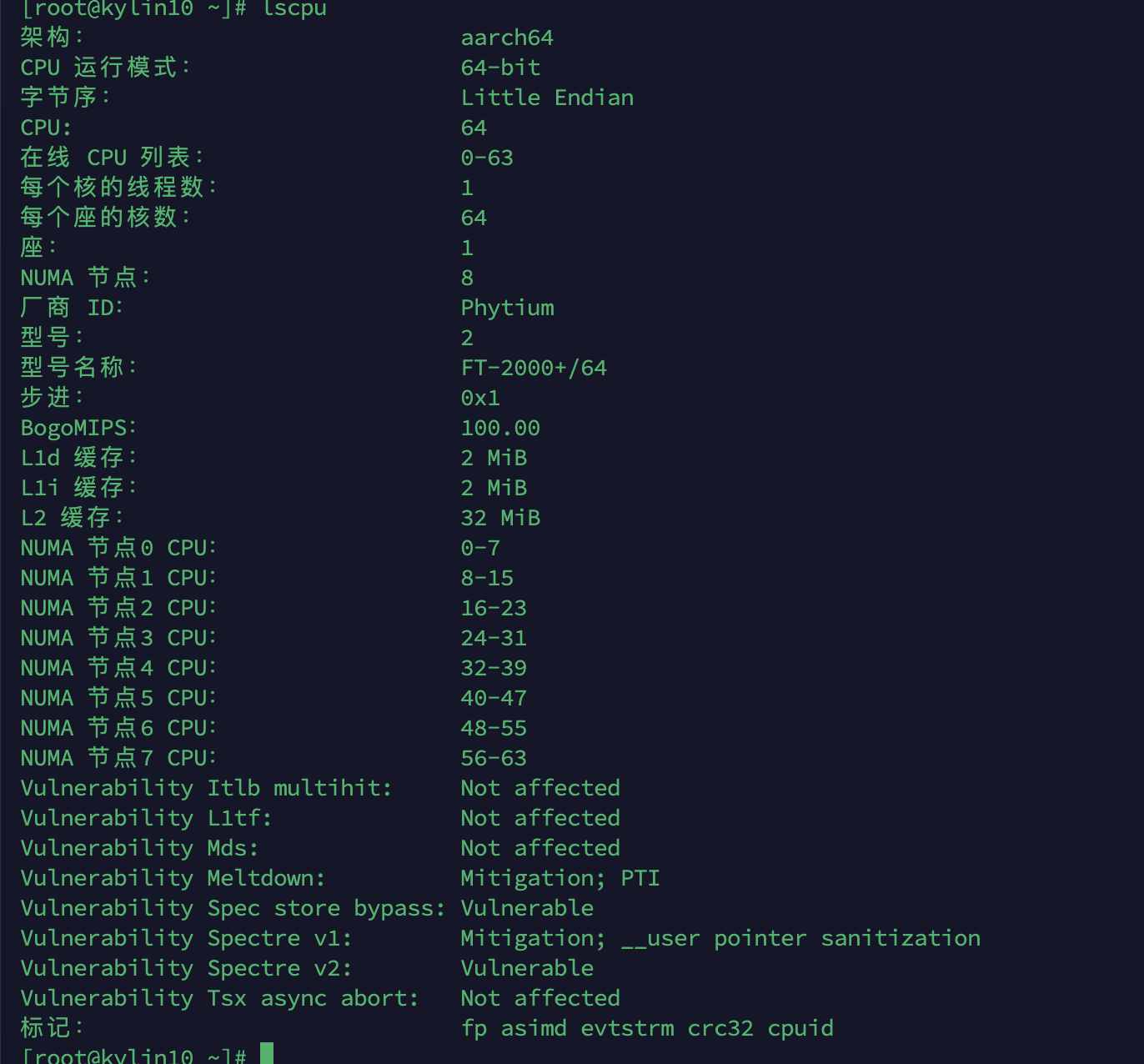
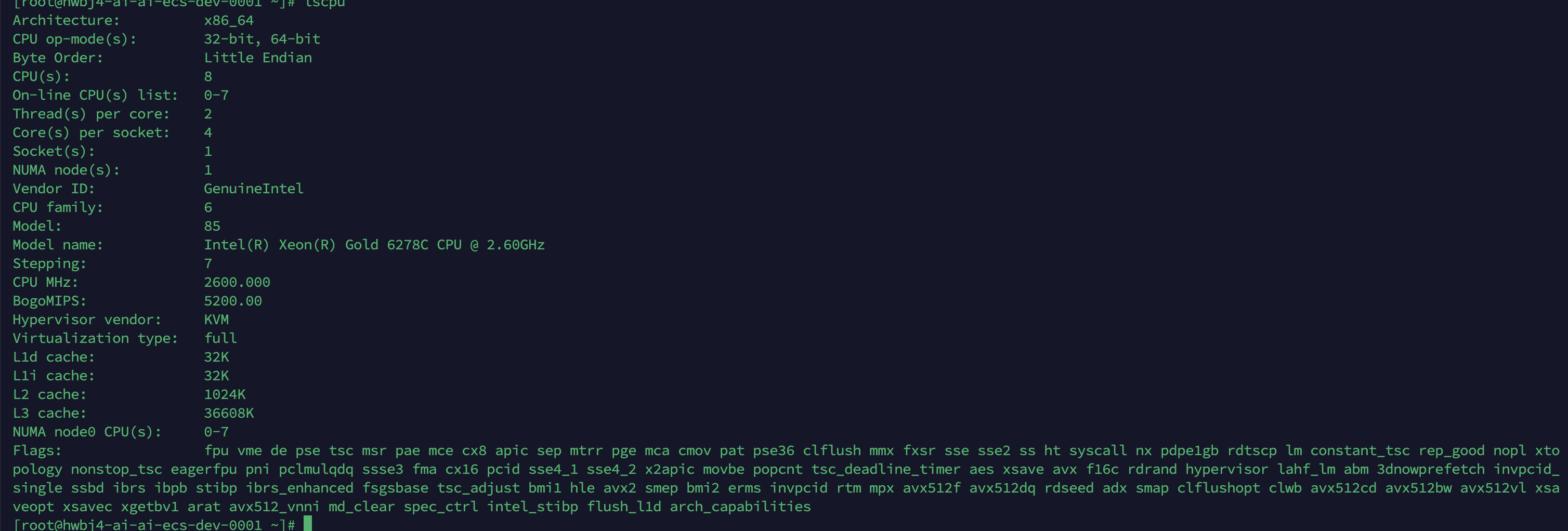
- 三方大模型组件不在致远的服务范围,需要客户选型并实施落地,公有云或私有均支持
# 服务器资源要求
| 编号 | 组件名 | 部署要求 | 备注 |
|---|---|---|---|
| 1 | 协同服务-智能助理相关插件 | 无需调整,保持现有协同服务配置 | - |
| 2 | aiapp应用服务 | CPU>=8C/内存>=16G/磁盘200GB | 支持Linux和信创操作系统,docker镜像部署 |
| 3 | dqrant向量数据库 | CPU>=8C/内存>=16G/磁盘1TB | 支持Linux和信创操作系统,docker镜像部署,向量数据库存储依赖磁盘空间,建议配备与全文检索相同或更大的磁盘空间 |
| 4 | 全文检索服务 | 已部署本服务无需调整,未部署本服务参考全文检索部署手册 | 适配系统参考全文检索部署手册 |
| 5 | OCR图片识别服务 | CPU>=4C/内存>=32G/磁盘100G | 支持Linux和信创操作系统,docker镜像部署,如需部署显卡加速建议系统选择Ubuntu |
| 6 | 三方大模型 | 支持公有云大模型(无服务器资源要求),也支持私有模型(以大模型专业厂商方案为准) | - |
# 大模型适配范围
产品支持如下大模型(需要遵守openai接口标准,公有或私有均支持),具体支持模型如下:
- DeepSeek(V3、r1),智能办公场景不要用deepseek-r1满血版
- 通义千问(qwen2.5、qwen-plus)
注意:
- deepseek-r1 671B满血版不支持智能办公。r1存在思考过程,满血版思考过程更长,正常一个稍微复杂的提示词需要半分钟以上才有结果。而智能办公的意图识别和关键字生成提取都依赖大模型的能力,需要多次调用模型接口,最终回复问题会等待很久,甚至超时。
- deepseek-r1蒸馏版可以使用智能办公,回复速度相比其它不带思考过程的模型稍慢。
- 三方大模型必须遵守OpenAI标准接口规范,不能增加或调整请求参数,不能增加或调整返回值格式,非标模型需要自行定制开发。
- 私有模型大小推荐:deepseek-r1:32b及以上、qwen2.5:32b及以上
- 大模型中一些较低参数的蒸馏版(如1.5b、7b)仅适用学习或轻量级应用;产品支持接入低参数的蒸馏版,但可能出现回复不准确问题
- 私有模型硬件配置和实施建设咨询华为、腾讯等三方专业厂商
# 网络架构图
# 公有云大模型
本方案支持接入公有云大语言模型,相关部署要求如下:
1、需要部署向量数据库服务(本手册会提供部署方法)
2、需要部署aiapp应用服务(本手册会提供部署方法),此服务需要确保访问向量数据库和公有云大模型
3、依赖协同的全文检索服务,需要确保全文检索服务能访问aiapp应用服务
4、确保协同OA服务能访问全文检索和aiapp应用服务

# 私有化部署大模型
本应用同样支持接入私有大语言模型,相关部署要求如下:
1、需要部署向量数据库服务(本手册会提供部署方法)
2、需要部署aiapp应用服务(本手册会提供部署方法),此服务需要确保访问向量数据库和私有大模型
3、依赖协同的全文检索服务,需要确保全文检索服务能访问aiapp应用服务
4、确保协同OA服务能访问全文检索和aiapp应用服务

# 服务默认端口
| 服务 | 默认对外端口 | 备注 |
|---|---|---|
| aiapp服务 | 5556 | 向oa和全文检索服务开放 |
| qdrant向量数据库 | 6333、6334 | 向aiapp开放 |
| OCR图片识别服务 | 12841 | 向aiapp、全文检索服务开放 |
# 准备和测试大模型
客户提前准备产品适配范围内的大模型( 必须兼容OpenAI规范 ),并提供一些必要的信息供产品后续配置使用,主要包含:
1、Base URL:模型的api接口地址,并开通网络策略确保产品能访问到模型地址
2、model模型名称:务必是准确的model,如deepseek-r1:8b、deepseek-r1:32b
3、API Key:授权信息,公有云都会有这个;私有化有的没有API Key,以私有部署厂商回复为准
无论是公有云还是私有大模型,都可以通过CURL命令来对模型进行调试,通过调试参数就能获得Base URL、API Key以及模型名称,也能确定模型是否可用,如模型不可用则先解决CURL不可用问题再进行后续部署!
# 公有云大模型测试示例
以阿里云百炼平台公有云大模型为例,获取模型CURL和模型重要参数方法为:
1、先访问百炼平台官网 https://bailian.console.aliyun.com/ 使用阿里系的帐号登录官网
2、通过模型广场找到需要接入的大模型:

3、访问大模型的API调用示例,参考下图指引就能获得有效的base url、APIKey、model模型名称,并且在Linux测试:

Linux下测试效果,看到返回值就表示测试通过:

Windows可以用如下转换后的格式发送请求,将$DASHSCOPE_API_KEY替换为有效的API KEY,将model值deepseek-r1替换为有效的模型名称测试:
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions -H "Authorization: Bearer $DASHSCOPE_API_KEY" -H "Content-Type: application/json" -d "{\"model\": \"deepseek-r1\",\"messages\": [{\"role\": \"user\",\"content\": \"9.9和9.11谁大\"}]}"
填入准确的参数后,通过Windows的cmd命令同样获得了结果:

综上,通过curl测试确定当前环境能连通大模型并获得答案,同时根据curl获得了百炼大模型的几个重要参数,在后续配置时即可直接使用:
1、Base URL:对应https://dashscope.aliyuncs.com/compatible-mode(取curl地址/v1/chat/前面的路径)
2、model模型名称:对应curl中"model"的值,如本示例的deepseek-v3
3、API Key:取百炼官网个人的API KEY,取本示例Authorization: Bearer后面这段内容
扩展资料:
- 其它公有云大模型自行参考模型官网的手册
- DeepSeek多平台接入方式-百度 阿里 抖音 硅基流动 https://www.bilibili.com/video/BV1PLN9ecEws
- 阿里云错误码地址(排查问题用)https://help.aliyun.com/zh/model-studio/developer-reference/error-code
# 私有大模型测试示例
私有大模型需要联系部署模型的技术人员提供curl地址,也可以使用如下转换后的编码,再填入客户真实的私有大模型信息测试:
# 不带API KEY的私有大模型测试命令(注意替换/v1/chat前面的地址,和model的值为客户真实的信息)
curl -X POST http://10.1.131.174:11434/v1/chat/completions -H "Content-Type: application/json" -d "{\"model\": \"deepseek-r1:32b\",\"messages\": [{\"role\": \"user\",\"content\": \"写一首诗\"}]}"
测试一个不带API KEY的私有模型效果如下:

综上,通过curl测试确定当前环境能连通私有大模型并获得答案,同时根据curl获得了私有大模型的几个重要参数,在后续配置时即可直接使用:
1、Base URL:对应http://10.xx.xxx.xxx:1xxx4(取curl地址/v1/chat/前面的路径)
2、model模型名称:对应curl中"model"的值,如本示例的deepseek-r1:32b蒸馏模型
3、API Key:本例不涉及,后续配置时也不用录入
如果私有模型curl带有API KEY ,参考如下代码示例,则我们也能得到私有模型的几个重要参数:
1、Base URL:对应https://10.1.131.174:11434(取curl地址/v1/chat/前面的路径)
2、model模型名称:对应curl中"model"的值,如本示例的deepseek-r1:32b
3、API Key:对应ks-12121(取本示例Authorization: Bearer后面这段内容)
# 带API KEY的私有大模型测试命令
curl -X POST http://10.1.131.174:11434/v1/chat/completions -H "Authorization: Bearer ks-12121" -H "Content-Type: application/json" -d "{\"model\": \"deepseek-r1:32b\",\"messages\": [{\"role\": \"user\",\"content\": \"写一首诗\"}]}"
总结:在进行后续部署之前,务必先确保大模型已经准备到位,并且通过curl能测通,能根据curl获取base url、model、api-key这几个重要的参数!
# 二、相关服务部署
# 安装包获取
网盘下载链接: https://pan.baidu.com/s/1UfyGDfMV4BJYuinuKPxuig?pwd=yws3 提取码: yws3
下载如下安装包:
基础组件
│── 智能助理
│── X86容器镜像
│── 国产化ARM容器镜像
注意:
- 信创环境如果是arm架构cpu,请使用国产化arm容器镜像目录下的镜像,如果是x86(海光),还是使用X86容器镜像。
- X86容器镜像中,OCR推荐使用cpu版的镜像,GPU版镜像兼容性较差,对硬件和系统均有要求。
- 上述资源的部署顺序固定:必须是先部署qdrant,再部署aiapp,最后部署ocr,请严格遵守。
# Linux依赖安装
在服务器上执行如下命令安装依赖,服务通外网才能使用,不通外网按照前面的要求预置,已预置的可忽略此步骤。
# Ubuntu系统执行
sudo apt-get update
sudo apt-get install -y curl vim
# RedHat系列(CentOS、openEuler等)执行
sudo yum update -y
sudo yum install -y curl vim
# Linux磁盘空间检查
通过df -h检查磁盘空间,需要确保系统的磁盘空间满足服务器资源要求
建议将充足的空间挂载到系统根目录(/)下,如按照本手册部署,程序和数据的分布为:
/var/lib/docker/目录存放程序/data/SeeyonAI/目录存放数据(如向量数据库数据)
# Docker安装
服务器需要docker组件,没有docker环境可以参考安装部署Docker(二进制包方式) https://open.seeyoncloud.com/#/faq/vuepressFile/v1/share?url=Z2ptZkplPjMzNDE=
# qdrant向量数据库部署
确保qdrant.tar程序包已经下载,并且上传到向量数据库服务器指定目录(如/data目录),随后进行安装:
# 没有/data目录则先创建
mkdir -p /data
# 将qdrant.tar程序包上传到/data目录下,随后导入镜像
docker load -i /data/qdrant.tar
# 创建向量库数据目录
mkdir -p /data/SeeyonAI/qdrant/
# 启动向量库(默认开启6333、6334端口)
docker run --privileged --restart=always -d -p 6333:6333 -p 6334:6334 -v /data/SeeyonAI/qdrant/qdrant_storage:/qdrant/storage --name qdrant qdrant/qdrant:prod
# aiapp服务部署
确保qdrant.tar程序包已经下载,并且上传到向量数据库服务器指定目录(如/data目录),随后进行安装:
# 将aiapp.tar程序包上传到/data目录下,随后导入镜像
docker load -i /data/aiapp.tar
# 创建aiapp配置文件目录
mkdir -p /data/SeeyonAI/aiapp/aiapp_config
# 创建/修改配置文件
vim /data/SeeyonAI/aiapp/aiapp_config/config.yaml
公有云大模型配置文件
大模型配置中的apikey、model模型名称、url模型base url地址均需要提前准备,参考准备和测试大模型章节操作准备相关参数信息。
model_define:
classify:
type: qwen # 不用修改,公有云大模型都配置为qwen即可
apikey: xxx # 公有云上创建的api key
model: qwen-plus # 公有云厂商提供的实际模型名称
url: https://dashscope.aliyuncs.com/compatible-mode # 修改为厂商提供的 Base Url
# 以下是不同场景的信息,默认都使用相同模型配置,请参照上面classify配置修改以下所有配置
exact:
type: qwen
apikey: xxx
model: qwen-plus
url: https://dashscope.aliyuncs.com/compatible-mode
exact_entity:
type: qwen
apikey: xxx
model: qwen-plus
url: https://dashscope.aliyuncs.com/compatible-mode
create:
type: qwen
apikey: xxx
model: qwen-plus
url: https://dashscope.aliyuncs.com/compatible-mode
temperature: 0.8
create_groovy:
type: qwen
apikey: xxx
model: qwen-plus
url: https://dashscope.aliyuncs.com/compatible-mode
qa:
type: qwen
apikey: xxx
model: qwen-plus
url: https://dashscope.aliyuncs.com/compatible-mode
temperature: 0.1
seed: 1
top_p: 0.7
qa_analyze:
type: qwen
apikey: xxx
model: qwen-plus
url: https://dashscope.aliyuncs.com/compatible-mode
# 视觉大模型配置,用于归档助手功能;上文网络结构图中没有包含此模型服务,可以直接略过此项配置,但不要删除
vl_common:
type: qwen
apikey: xxx
model: qwen-vl-max # 修改为视觉模型名称(没有用到归档助手则保持现有配置不变,不要删除)
url: https://dashscope.aliyuncs.com/compatible-mode # 修改为视觉模型的base url(没有用到归档助手则保持现有配置不变,不要删除)
temperature: 0.1
sql:
type: qwen
apikey: xxx
model: qwen-plus
url: https://dashscope.aliyuncs.com/compatible-mode
bi_recommend_question:
type: qwen
apikey: xxx
model: qwen-plus
url: https://dashscope.aliyuncs.com/compatible-mode
temperature: 1
bi_advice:
type: qwen
apikey: xxx
model: qwen-max
url: https://dashscope.aliyuncs.com/compatible-mode
temperature: 0.7
third_party:
qa_doc:
path:
doc_permission: /seeyon/rest/seeyon-ai/plugin/assistant/auth
assistant_list: /seeyon/rest/seeyon-ai/plugin/assistant/list
resource_check: /seeyon/rest/seeyon-ai/v5Wrapper/source/exists
keywords_search: /seeyon/rest/seeyon-ai/v5Wrapper/source/keywords_search
create-task: /seeyon/rest/seeyon-ai/smartdata/create-task
ocr:
host: http://ip:port/ocr # 修改为OCR服务的地址,比如 http://10.101.68.9:12841/ocr;如果没有部署ocr,请保持该配置不变(勿删除)
path:
pic_content: /pic/get_table_all_text
qa_config:
refer_doc_length: 7
qdrant:
host: "qdrant ip" # 修改为qdrant向量数据库的IP地址
port: "6333" # 修改为qdrant向量数据库的端口号,默认6333
grpc_port: "6334" # 修改为qdrant向量数据库的gprc端口号,默认63334
collection: "v5"
vector_size: "512"
use_grpc: true
timeout: 10
embedding:
backup:
BACKUP_ENABLE: false
BACKUP_PATH: ''
QDRANT_STORAGE_PATH: ''
threads:
cpu-count: 4 # 修改为cpu核数除以2,必须修改为整数,比如8核心CPU则填写cpu-count: 4
data_dir:
data_dir_prefix: /app/data # 此处请不要修改,此路径是docker路径
# 是否输出思考过程:注意只有R1模型才开启 ,true为开启false为关闭
output_think: false
私有化大模型配置文件
大模型配置中的apikey、model模型名称、url模型base url地址均需要提前准备,参考准备和测试大模型章节操作准备相关参数信息。
model_define:
classify:
type: local # 不用修改,私有大模型都配置为local
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 比如:deepseek-r1:8b
url: http://x.x.x.x:9000 # 修改为模型的base url, 比如:http://10.1.131.174:11434
exact:
type: local
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 同上
url: http://x.x.x.x:9000 # 修改为模型的base url,同上
exact_entity:
type: local
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 同上
url: http://x.x.x.x:9000 # 修改为模型的base url,同上
create:
type: local
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 同上
url: http://x.x.x.x:9000 # 修改为模型的base url,同上
create_groovy:
type: local
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 同上
url: http://x.x.x.x:9000 # 修改为模型的base url,同上
qa:
type: local
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 同上
url: http://x.x.x.x:9000 # 修改为模型的base url,同上
temperature: 0.1
seed: 1
top_p: 0.7
qa_analyze:
type: local
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 同上
url: http://x.x.x.x:9000 # 修改为模型的base url,同上
# 视觉大模型配置,用于归档助手功能;上文系统架构图中没有包含此模型服务,可以直接略过此项配置,但不要删除
vl_common:
type: local
model: Qwen2-VL-72B-Instruct-AWQ # 修改为视觉模型名称(没有用到归档助手忽略该配置)
url: http://x.x.x.x:9001 # 修改为视觉模型的base url(没有用到归档助手忽略该配置)
sql:
type: qwen
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 同上
url: http://x.x.x.x:9001 # 修改为模型的base url,同上
bi_recommend_question:
type: qwen
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 同上
url: http://x.x.x.x:9001 # 修改为模型的base url,同上
temperature: 1
bi_advice:
type: qwen
model: Qwen2-72B-Instruct-AWQ # 修改为实际的模型名称, 同上
url: http://x.x.x.x:9001 # 修改为模型的base url,同上
temperature: 0.7
third_party:
qa_doc:
path:
doc_permission: /seeyon/rest/seeyon-ai/plugin/assistant/auth
assistant_list: /seeyon/rest/seeyon-ai/plugin/assistant/list
resource_check: /seeyon/rest/seeyon-ai/v5Wrapper/source/exists
keywords_search: /seeyon/rest/seeyon-ai/v5Wrapper/source/keywords_search
ocr:
host: http://ip:port/ocr # 修改为OCR服务的地址,比如 http://10.101.68.9:12841/ocr;如果没有部署ocr,请保持该配置不变(勿删除)
path:
pic_content: /pic/get_table_all_text
qa_config:
refer_doc_length: 7
qdrant:
host: "qdrant ip" # 修改为qdrant向量数据库的IP地址
port: "6333" # 修改为qdrant向量数据库的端口号,默认6333
grpc_port: "6334" # 修改为qdrant向量数据库的gprc端口号,默认6334
collection: "v5"
vector_size: "512"
use_grpc: true
timeout: 10
embedding:
backup:
BACKUP_ENABLE: false
BACKUP_PATH: ''
QDRANT_STORAGE_PATH: ''
threads:
cpu-count: 4 # 修改为cpu核数除以2,必须修改为整数,比如8核心CPU则填写cpu-count: 4
data_dir:
data_dir_prefix: /app/data # 此处请不要修改,此路径是docker路径
# 是否输出思考过程:注意只有R1模型才开启,非R1模型请修改配置为false
output_think: false
以上配置保存后,执行启动命令:
# 启动
docker run --privileged --restart=always -d --name aiapp -v /data/SeeyonAI/aiapp/logs:/app/logs -v /data/SeeyonAI/aiapp/aiapp_config:/app/ai_app/resources/config -p 5556:5556 harbor-chengdu.seeyoncloud.com/ai/aiapp:prod
如果有定制智能问答的身份的需求时则可以在config.yaml同级目录下加model.prompt文件,文件内容请参考
格式:
当用户询问您身份相关问题时,请您回答: xxxx(需要模型回答的内容)
例子:
当用户询问您身份相关问题时,请您回答:您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-V3。如您有任何任何问题,我会尽我所能为您提供帮助。
# ocr(图片文字提取服务)部署
# 创建目录
mkdir -p /data/SeeyonAI/ocr/config
# 创建配置文件
cat > /data/SeeyonAI/ocr/config/config.json << EOF
{
"app_name": "ocr",
"log_dir": "./logs",
"log_level": "info",
"port" : 12841,
"log_file_size": 10485760,
"log_backup_count": 5,
"workers": 1
}
EOF
# 导入镜像
docker load -i /data/ocr_cpu.tar
# 启动
docker run -d --privileged --restart=always --name ocr -p 12841:12841 -v /data/SeeyonAI/ocr/config:/app/config harbor-chengdu.seeyoncloud.com/ai/ocr_cpu:prod
# 验证服务可用性
以上关联组件全部部署、配置完成后,依次验证服务可用性
# 检查所有服务是否正常启动
必须确认所有服务都正常启动了,再去验证可用性
# 查看服务状态,必须所有服务都是up状态
docker ps -a

# 查看aiapp启动日志,如果启动完成会显示如下信息
docker logs -f --tail 100 aiapp

- 如果发现aiapp服务启动报错,一般都是配置文件没有修改正确导致,请仔细检查配置文件
# 验证qdrant可用性
# 健康检查命令 (xx.xx.xx.xx 请替换成qdrant的ip地址
curl http://xx.xx.xx.xx:6333/collections/v5
# 返回结果检查:(返回结果 result里面的 status 为green 证明启动成功)
{"result":{"status":"green","optimizer_status":"ok","vectors_count":0,"indexed_vectors_count":0,"points_count":0,"segments_count":16,"config":{"params":{"vectors":{"size":512,"distance":"Cosine","on_disk":true},"shard_number":2,"replication_factor":1,"write_consistency_factor":1,"on_disk_payload":true},"hnsw_config":{"m":16,"ef_construct":100,"full_scan_threshold":10000,"max_indexing_threads":0,"on_disk":false},"optimizer_config":{"deleted_threshold":0.2,"vacuum_min_vector_number":1000,"default_segment_number":0,"max_segment_size":null,"memmap_threshold":null,"indexing_threshold":2000,"flush_interval_sec":5,"max_optimization_threads":null},"wal_config":{"wal_capacity_mb":32,"wal_segments_ahead":0},"quantization_config":null},"payload_schema":{"owner":{"data_type":"keyword","points":0},"prefix_id":{"data_type":"keyword","points":0},"appType":{"data_type":"integer","points":0}}},"status":"ok","time":0.000095766}(base)
# 验证aiapp可用性
# (xx.xx.xx.xx 请替换成aiapp助手服务的ip地址
curl -X GET http://xx.xx.xx.xx:5556/prompt/health_check
# 正确结果案例
{"code":"200","message":"Success","data":{"content":"ok"}}
# 验证ocr模型可用性
# 请替换xx.xx.xx.xx 为实际的OCR服务器IP 再执行命令
curl -X POST http://xx.xx.xx.xx:12841/ocr/pic/health
# 返回结果包含“单位”关键字,证明服务正常
{
"code": "200",
"message": "Success",
"data": {
"text_content": [
"单位"
]
}
}
# 三、协同服务配置
# 修改OA配置文件
编辑OA配置文件:base/conf/plugin.properties,添加以下配置
配置文件参数值后面请不要添加注释或者空格,可能会导致配置解析异常
# true表示开启
aicoreshell.ai.assistant.enabled=true
# ai算法服务地址即aiapp服务地址,格式:http://ip:port,端口默认5556
aicoreshell.ai.service.python.url=http://192.168.0.2:5556
# oa服务的ip和端口,格式: ip:port
aicoreshell.oa.host.ip=192.168.0.1:8080
以上配置完成之后,请重启OA并参考产品使用手册(商务公布的安装程序下载地址-文档-操作手册-V9.0sp1 新特性手册),完成智能助理配置后才能正常使用(启用智能助理、授权单位等)
手册参考位置如图:

# 四、全文检索配置
如需问答助手、办公助手(部分功能)可用,则需致远全文检索服务参与工作,全文检索服务需要在基础配置上增加AI特性配置
全文检索服务需要配置AI算法服务(aiapp服务)IP和端口,
全文检索配置文件:Searchservice/config/application.properties

ai.server.url = http://192.168.0.2:5556 # 配置成aiapp服务的地址。(格式:http://ip:port,端口默认5556)
ai.server.full.url = http://192.168.0.2:5556 # 配置成aiapp服务的地址。(格式:http://ip:port,端口默认5556)
ai.server.ssh.url = http://127.0.0.1:6006 # 保持默认即可。
ai.index.sync.mode = 1 # 配置为0。
ai.index.sync.datas.sizes = 100 # 保持默认即可。(可以根据AI服务器的性能适当调高。只有全量同步时会使用到)。
ai.index.sync.thread.size = 2 # 保持默认即可。(可以根据AI服务器的性能适当调高。只有全量同步时会使用到)。
ai.index.again.sync = 0 # 保持默认即可。
ai.index.again.sync.from.id = D:/1seeyonApp/v90_425/Seeyon/mydic # 保持默认即可。
ai.isSyncNode = false # 注释放开,设置为true(如果全文检索为集群部署,该配置保持默认即可)
ai.OCRUrl = http://192.168.0.3:12841 # 配置成OCR服务的地址。(格式:http://ip:port,端口默认12841)
配置完成后重启全文检索服务,OA已配全文检索的前提下,无需重启OA
在【系统管理员】-【全文检索服务配置】中,可检查全文检索是否成功配置连接aiapp
# 五、日常运维
# 问题排查
# 服务启停
# 重启服务
docker restart qdrant
docker restart ocr
docker restart aiapp
# 停止服务
docker stop aiapp
docker stop ocr
docker stop qdrant
# 启动服务
docker start qdrant
docker start ocr
docker start aiapp
# 查看服务状态
docker ps -a
# 删除容器
docker rm -f aiapp
docker rm -f ocr
docker rm -f qdrant
# 日志管理
# 卸载与重装
# 六、常见问题
1、V9.0SP1 0320版本,单位管理员后台,智能应用设置,智能助理授权时,提示:"未读取到AI助理相关系统或配置开启,请检查!"
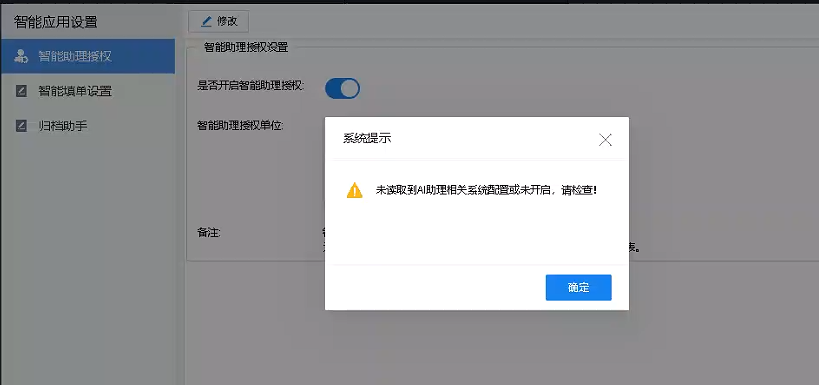
解决方法:修改 ApacheJetspeed/webapps/seeyon/WEB-INF/cfgHome/plugin/aicoreshell/config/aiapplication.properties
修改完成后请重启OA服务
...
# 注意下列配置中等号前后以及true末尾不要有空格,否则会导致不生效
ai.assistant.enabled=true
...
# 向量数据库(qdrant)
# 数据备份
qdrant备份 需要停止qdrant服务和OA服务
备份频率: 1-2周备份一次
备份方式: 停服后直接拷贝qdrant_storage整个路径
# 服务器其他相关设置
# 服务器编码设置
请保障 1、OA服务;2、AIAPP服务;统一编码格式为UTF-8
# 该命令查看编码设置
locale
# 或者
echo $LANG
# 查看LANG属性是否为LANG=zh_CN.UTF-8
← 模型对话部署配置手册 内容审校配置手册 →
