# CoMi模型配置操作手册
# 简述
本手册介绍LLM模型、Embedding模型等参数接入到CoMi的详细操作方法。
# 大模型准备和调试
部署前,需要客户提前准备产品适配范围内的模型,通过CURL命令测试大模型是否可用,待部署后取对应参数配置到CoMi中使用。
CoMi V1.1依赖两个模型:
LLM大语言模型:支持公有云和本地化模型,需要遵守OpenAI接口规范,同时模型支持FunctionCalling功能,如qwen3、deepseek-v3。
Embedding文本向量模型:支持公有云和本地化模型,需要遵守OpenAI接口规范,如bge-m3、qwen3-embedding。
为了验证客户提供的大模型是否支持OpenAI接口,可以从客户侧获取大模型的CURL测试命令(OpenAI接口格式),在CoMi服务器执行CURL命令测试大模型是否返回正确数据以及返回时间以评估模型响应性能。
# LLM大语言模型测试示例
{baseurl}/v1/chat/completions 请求是OpenAI推出的与LLM语言模型对话的标准接口,执行成功会获得模型的对话信息。
我们需要从客户侧拿到curl测试命令,然后在CoMi服务器上执行curl命令,如果有正确返回信息则测试通过,并且可以根据curl参数提取comi配置模型所需信息。
1、Linux测试LLM模型示例:
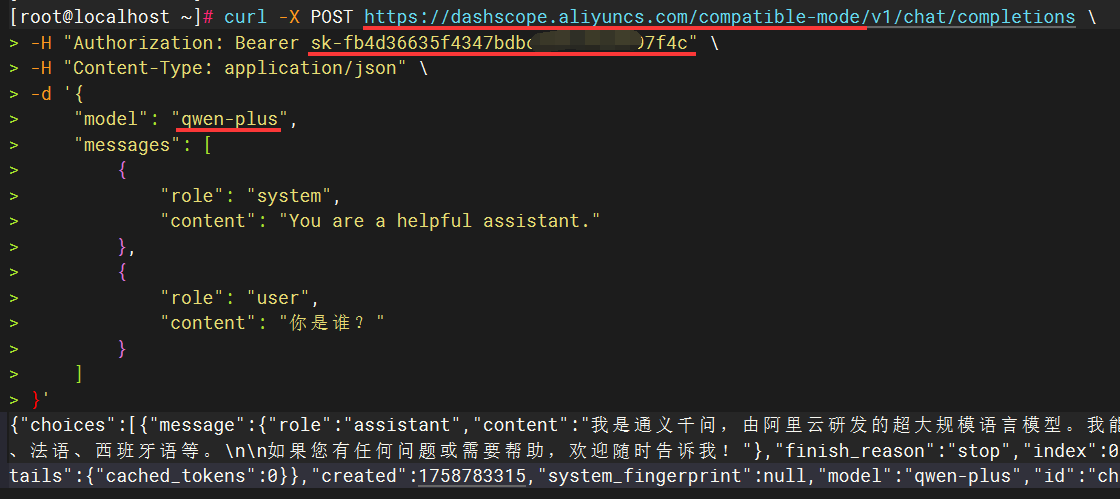
如下示例是标准的阿里百炼平台公有云LLM模型的测试示例(其它模型服务可以参考如下格式做调整),在Linux服务器执行如果有正确的输出则表示测试通过:
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer sk-fb4d36635f4347bdxxxxxxxxx7f4c" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen-plus",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "你是谁?"
}
]
}'
在Linux或信创服务器执行curl命令通过后,可以提取三个关键参数信息,供后续CoMi模型配置时使用:
- 参数一
baseurl:取/v1/chat/completions前面的URL地址,如https://dashscope.aliyuncs.com/compatible-mode就是CoMi配置所需baseurl - 参数二
apikey:取Authorization: Bearer后面那段参数,如sk-fb4d36635f4347bdxxxxxxxxx7f4c,apikey在本地化模型可能不存在,可以留空 - 参数三
model模型名称:取curl中的"model"参数值,如qwen-plus
下图红线处标记了三个关键参数信息:
2、Windows测试LLM模型示例:
Windows服务器只能运行单行命令(使用Linux带换行符的curl会报错),此时可以让AI帮忙转换成Windows能运行的单行命令,以下是单行测试的示例可供参考:
curl -X POST "http://192.168.188.162:9998/v1/chat/completions" -H "Authorization: Bearer $DASHSCOPE_API_KEY" -H "Content-Type: application/json" -d "{\"model\":\"qwen3-awq-32b\",\"messages\":[{\"role\":\"user\",\"content\":\"你是谁?\"}]}"
在Windows服务器执行curl命令通过后,同样提取命令中的关键参数,如下图所示:
- 参数一
baseurl:取/v1/chat/completions前面的URL地址,如http://192.168.188.162:9998就是CoMi配置所需baseurl - 参数二
apikey:取Authorization: Bearer后面那段参数,apikey在本地化模型可能不存在,可以留空 - 参数三
model模型名称:取curl中的"model"参数值,如qwen3-awq-32b

小结:使用上面的curl命令在comi服务器测试通过,则说明LLM模型基本可用,可做后续操作。
# Embedding模型测试示例
{baseurl}/v1/embeddings 请求是OpenAI推出的与Embedding模型对话的标准接口,执行成功会获得模型的向量化结果。
注:Embedding的OpenAI接口跟LLM是不一样的,注意甄别!
我们需要从客户侧拿到curl测试命令,然后在CoMi服务器上执行curl命令,如果有正确返回信息则测试通过,并且可以根据curl参数提取comi配置模型所需信息。
1、Linux测试Embedding模型示例:
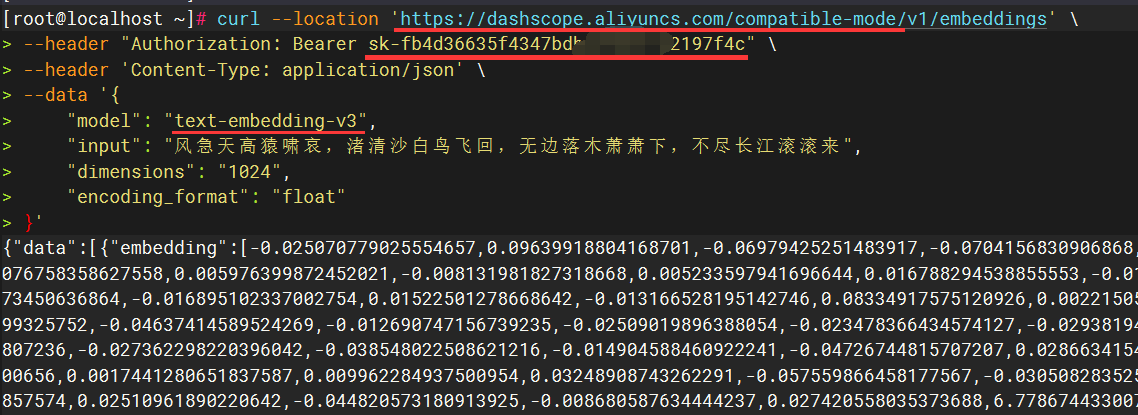
如下示例是标准的阿里百炼平台公有云LLM模型的测试示例(本地模型也可以参考如下格式做调整),在Linux服务器执行如果有正确的输出则表示测试通过:
curl --location 'https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings' \
--header "Authorization: Bearer sk-fb4d36635f4347bdxxxxxxxxx7f4c" \
--header 'Content-Type: application/json' \
--data '{
"model": "text-embedding-v3",
"input": "风急天高猿啸哀,渚清沙白鸟飞回,无边落木萧萧下,不尽长江滚滚来",
"dimensions": 1024,
"encoding_format": "float"
}'
在Linux或信创服务器执行curl命令通过后,可以提取三个关键参数信息,供后续CoMi模型配置时使用:
- 参数一
baseurl:取/v1/chat/embeddings前面的URL地址,如https://dashscope.aliyuncs.com/compatible-mode就是CoMi配置所需baseurl - 参数二
apikey:取Authorization: Bearer后面那段参数,如sk-fb4d36635f4347bdxxxxxxxxx7f4c,apikey在本地化模型可能不存在,可以留空 - 参数三
model模型名称:取curl中的"model"参数值,如text-embedding-v3
下图红线处标记了三个关键参数信息:
2、Windows测试Embedding模型示例:
Windows服务器只能运行单行命令(使用Linux带换行符的curl会报错),此时可以让AI帮忙转换成Windows能运行的单行命令,以下是单行测试的示例可供参考:
curl --location "http://192.168.188.162:9997/v1/embeddings" --header "Authorization: Bearer DASHSCOPE_API_KEY" --header "Content-Type: application/json" --data "{\"model\":\"Qwen3-Embedding-4B\",\"input\":\"风急天高猿啸哀,渚清沙白鸟飞回,无边落木萧萧下,不尽长江滚滚来\",\"dimensions\":1024,\"encoding_format\":\"float\"}"
在Windows服务器执行curl命令通过后,同样提取命令中的关键参数,如下图所示:
- 参数一
baseurl:取/v1/chat/embeddings前面的URL地址,如http://192.168.188.162:9998就是CoMi配置所需baseurl - 参数二
apikey:取Authorization: Bearer后面那段参数,apikey在本地化模型可能不存在,可以留空 - 参数三
model模型名称:取curl中的"model"参数值,如qwen3-awq-32b

小结:使用上面的curl命令在comi服务器测试通过,则说明Embedding模型基本可用,可做后续操作。
# CoMI模型配置步骤
登录协同OA系统管理员(分保插件模式下,是在安全管理员)后台,访问CoMi Builer菜单-模型页签,点击 接入模型维护:
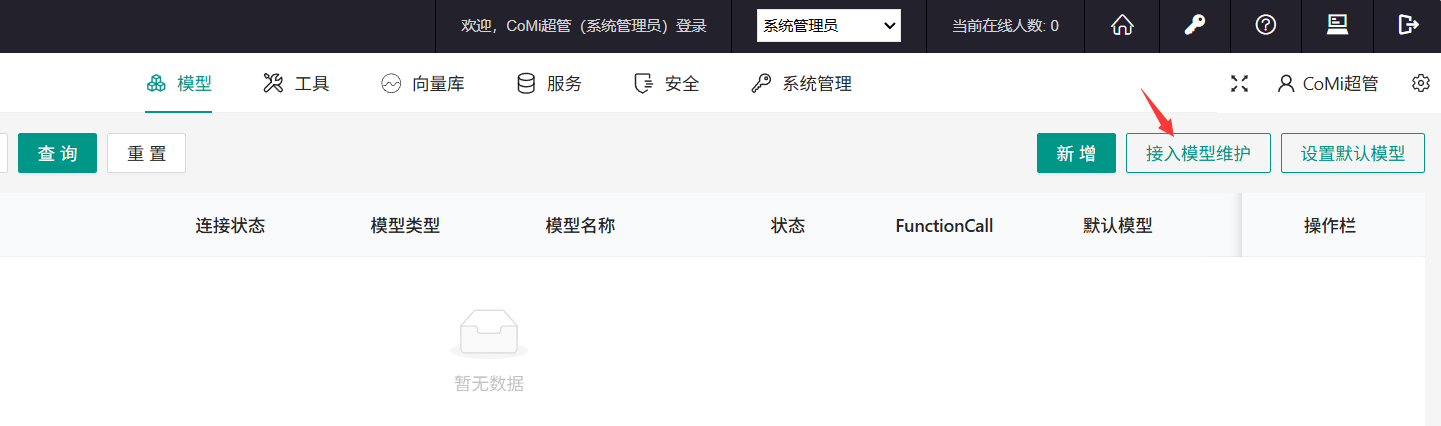
点击 "+" ,新建分类(分类名称可自定义)

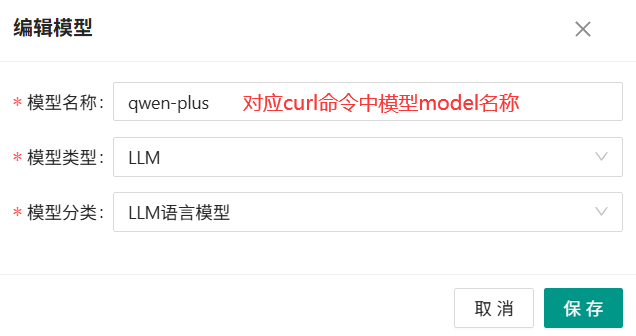
再点击 "新增",新增模型,根据模型类型,选择LLM或者Embedding模型:
- 模型名称:必须是真实准确的名称,对应大模型curl测试中的model参数
- 必须至少新建一个LLM模型和一个Embedding模型,用于后面的数据初始化
再次点击模型栏,返回上一级,点击新增,填写模型完整信息,LLM和Embedding需要分别新增一个:
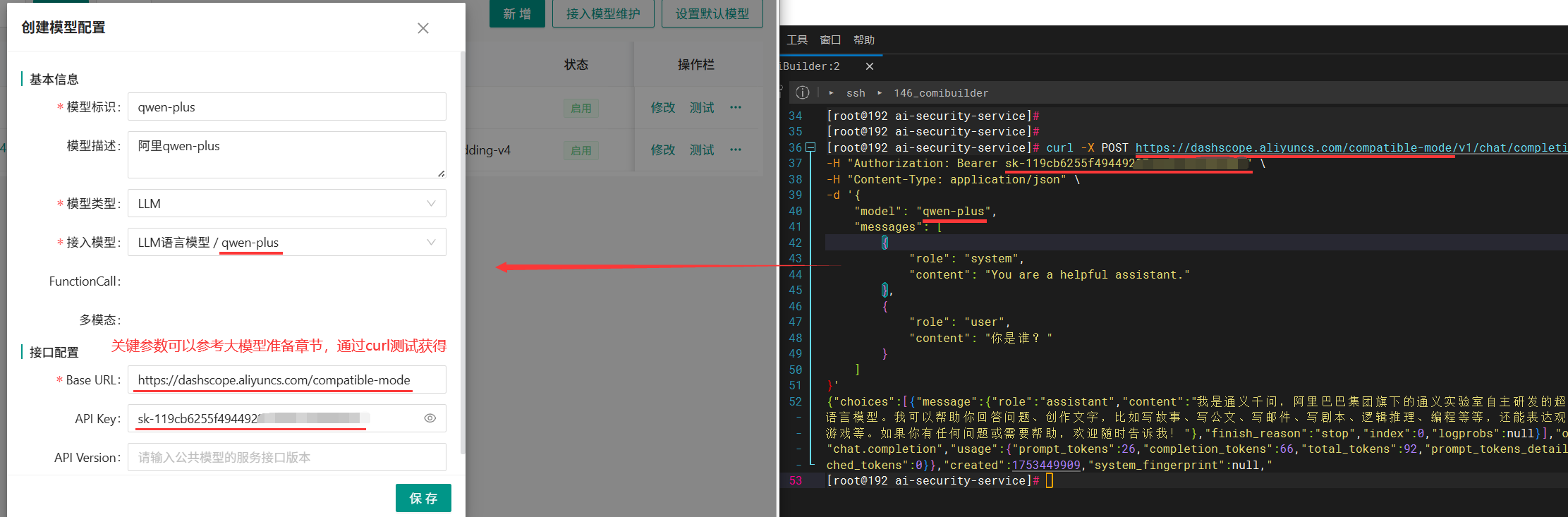
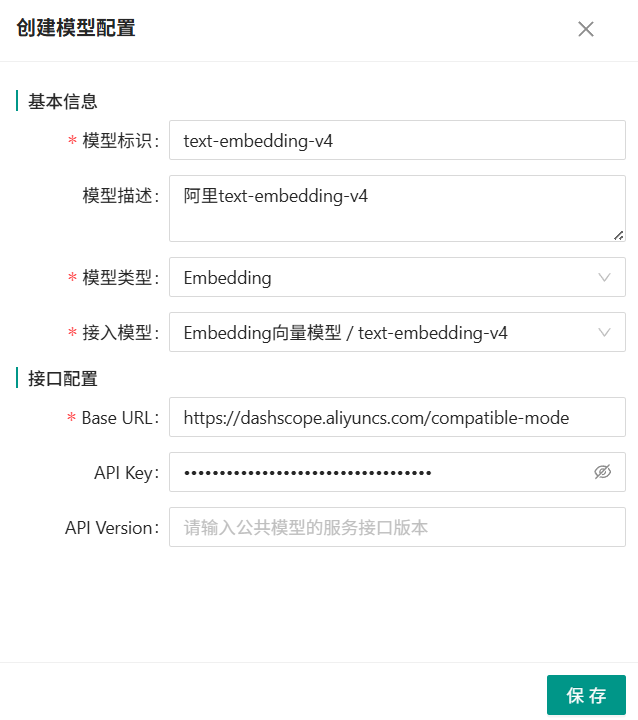
- 模型标识:唯一,可自定义,常用模型建议尽量与model一致,方便管理
- 模型描述:非必填
- 模型类型:LLM对应 语言模型;Embedding对应向量模型;ReRank对应重排模型
- 接入模型:对应“接入模型维护”按钮中配置的信息
- Base URL:对应模型的openAI请求地址,参考【大模型准备和调试】章节说明获取
- API Key:公有云模型涉及此参数,私有模型可能没有,参考【大模型准备和调试】章节说明获取
LLM语言模型配置示例:
Embedding模型配置示例:
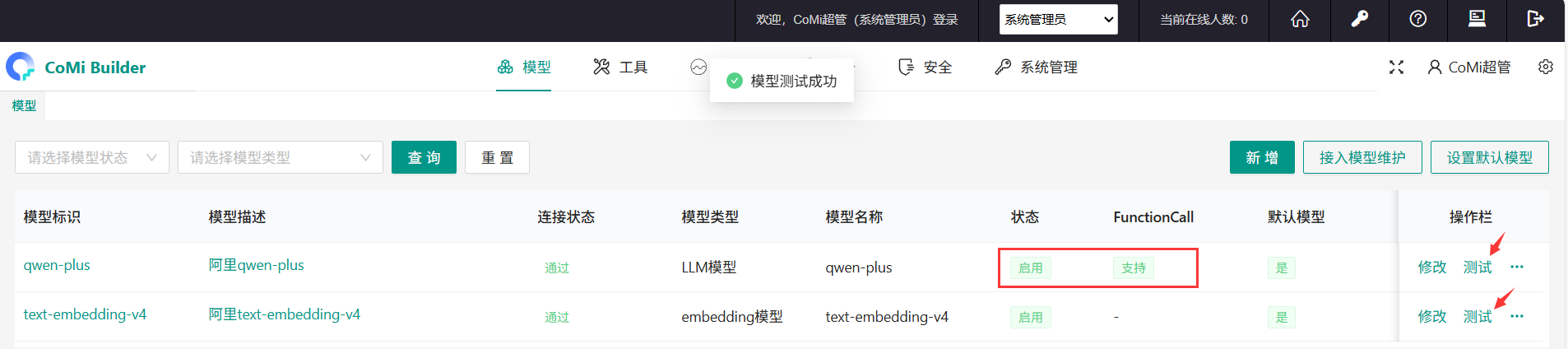
模型信息保存后,默认模型为禁用,需要右侧隐藏按钮启用模型:

通过“测试”确保大模型的连接状态为“通过”,并且尽量使用支持Functioncalling的LLM大语言模型:
如大语言模型不支持FunctionCalling会导致所有涉及调用协同OA工具的Agent无法使用
# 后台设置默认模型
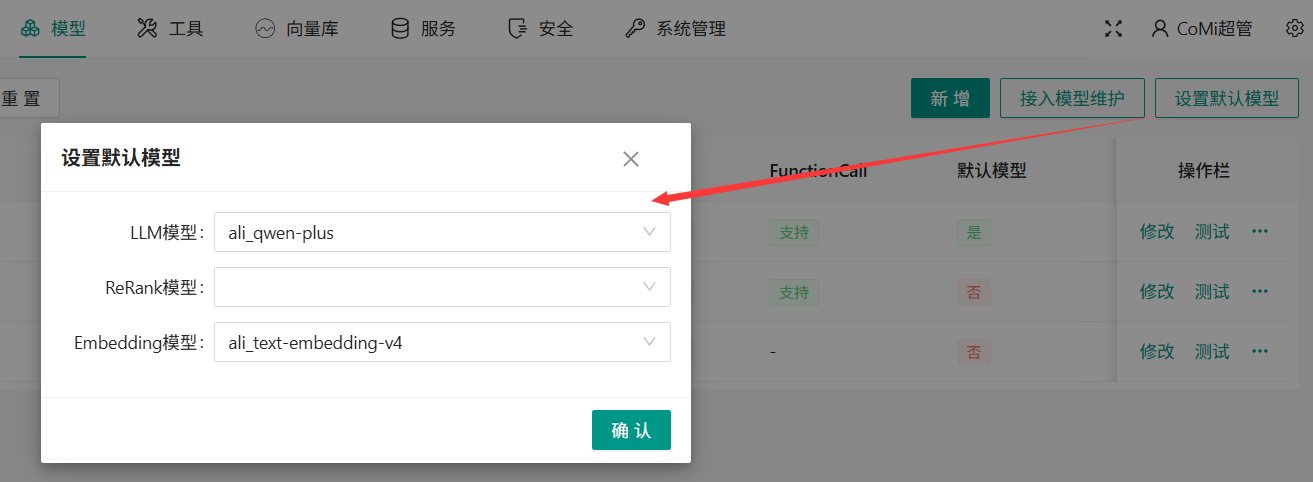
模型页签,点击“设置默认模型”按钮,选择默认运行的模型:
- LLM大语言模型,必须
- ReRank模型,非必须
- Embedding模型,必须,选择质量较好的Embedding文本向量模型,默认Embedding模型一旦配置不允许修改!
为什么Embedding文本向量模型一旦配置不允许修改?因为不同文本向量模型算法不一,如混合使用会导致向量数据库错乱,无法给出高质量的数据
# 常见模型配置错误
1、baseurl配置错误
2、apikey配置错误或过期
3、model模型配置错误
