# 问题现象
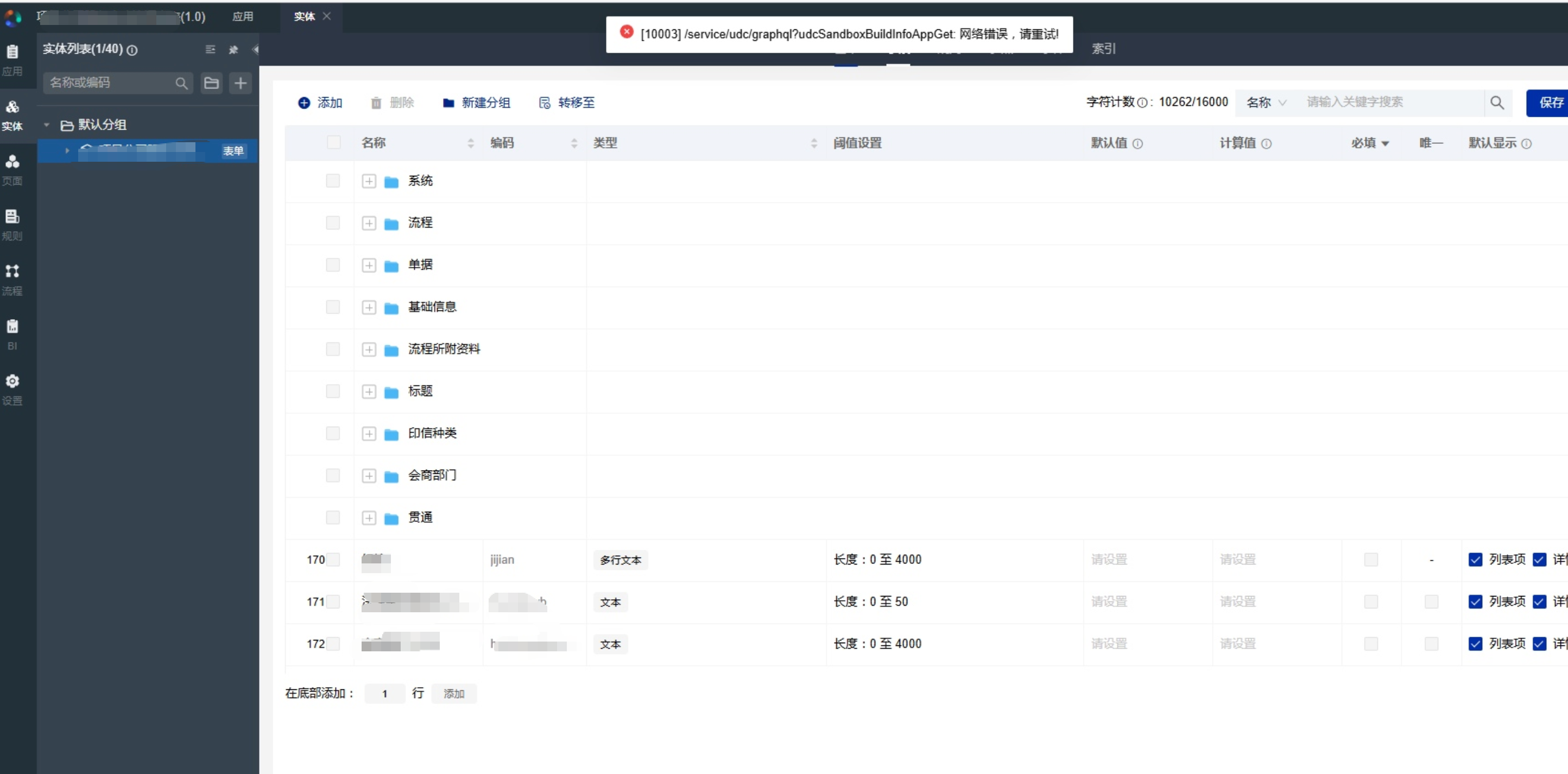


- 时间:2025年7月16日起
- 影响范围:
- 页面弹报错,页面常弹出10003网络错误,对应后端服务不固定
- 页面无法正常展示
- 初步怀疑:
- 服务发生重启,导致应用调用超时
# 排查记录
- 信息收集:
- 距离故障时间较近,登录集群中查看集群event信息(event默认保留1h)
- 初步诊断(命令详解)
# 登录到kubernetes master节点,对集群event信息收集
$ kubectl get events -A
# 看到集成服务(capability)pod发生过重启
# 出现此状态一般为以下几种情况
# 1. 服务自身资源占用较高,触发QOS OOM
# 2. 服务自身健康检查未通过
# 3. 服务自身异常退出,panic
# 根据以上可能情况进行深入排查发现,重启原因为OOMKill,导致服务重启。
# 关键命令
$ kubectl -n seeyon-oa logs -p cip-capability-xxx
$ kubectl -n seeyon-oa describe po cip-capability-xxx
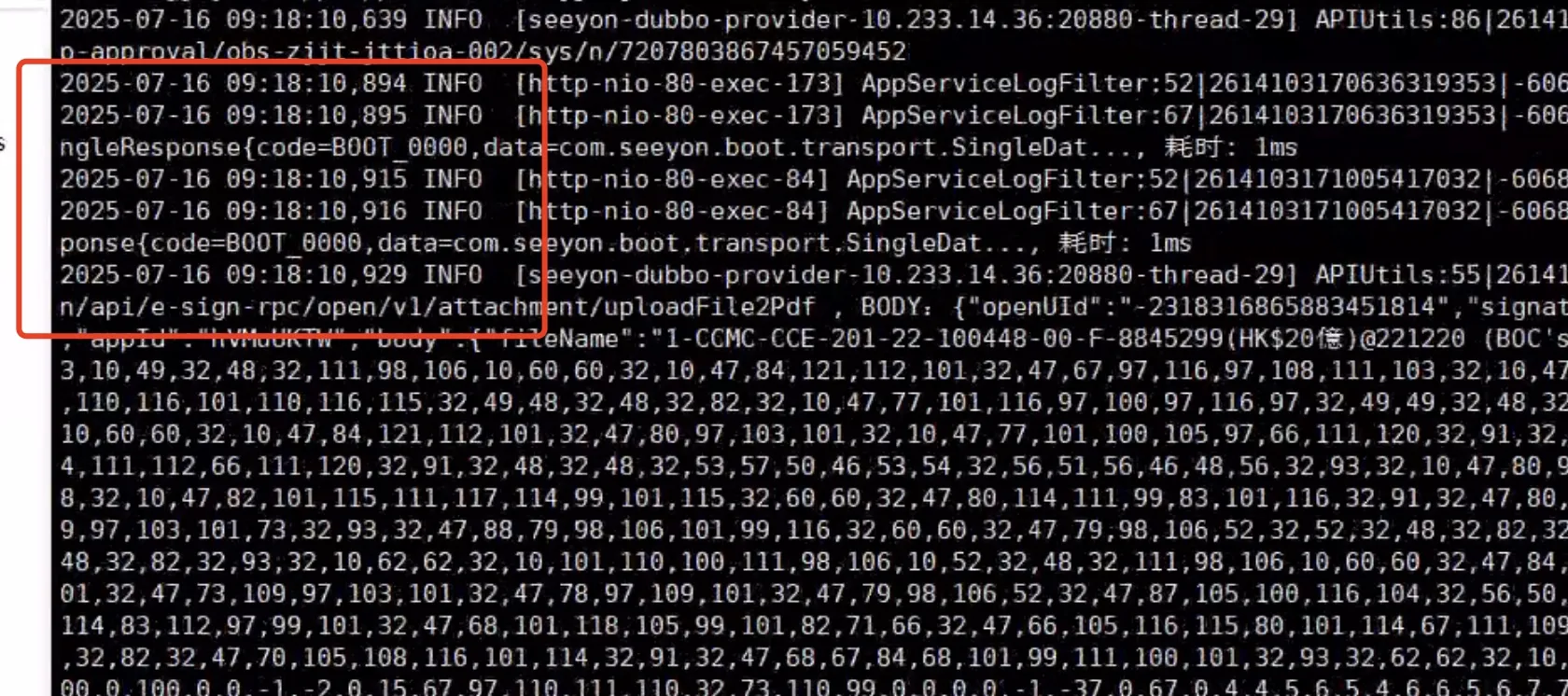
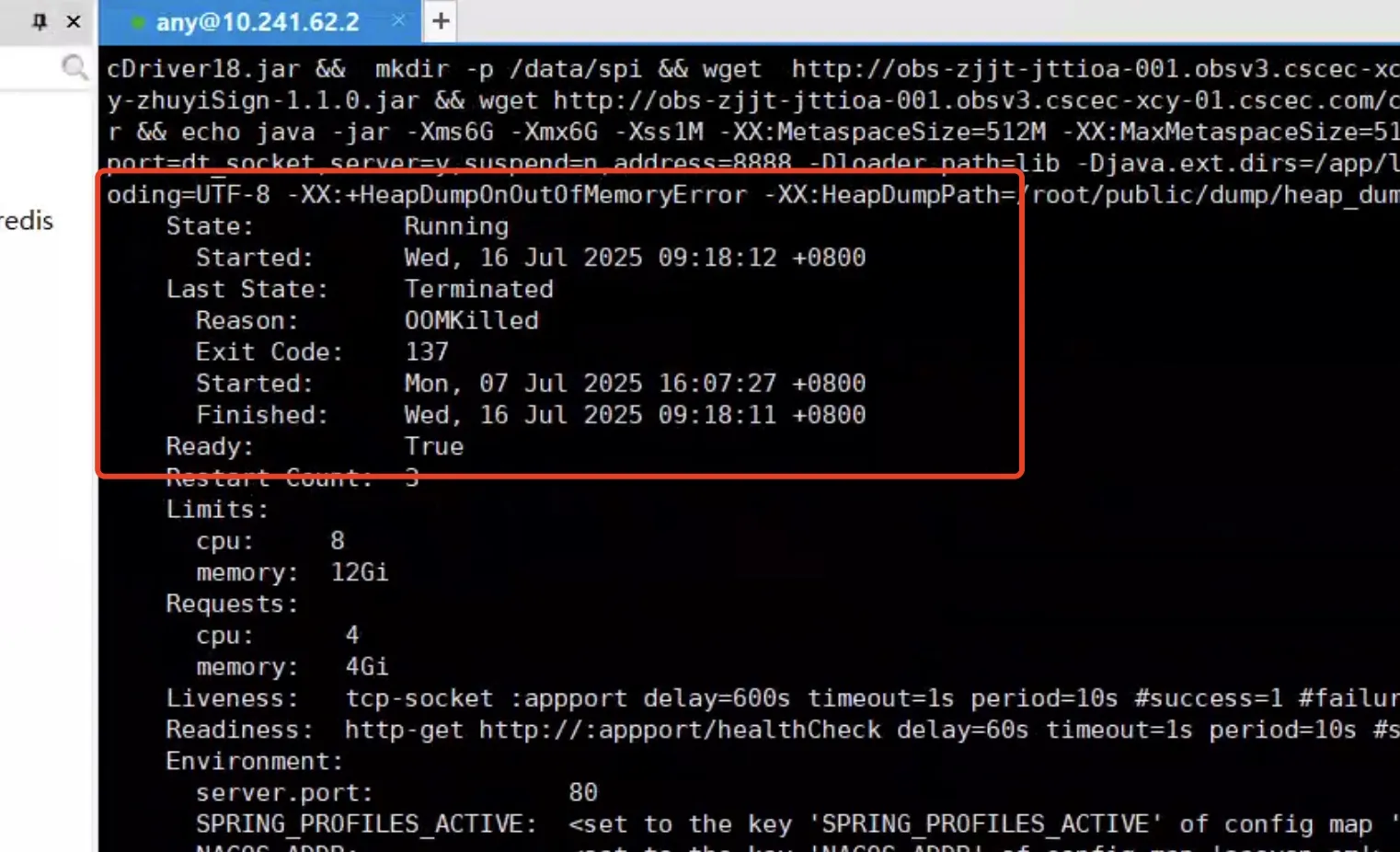
- 根因分析-链路排查
通过prometheus检查发现该服务内存由于超过limit导致触发oom
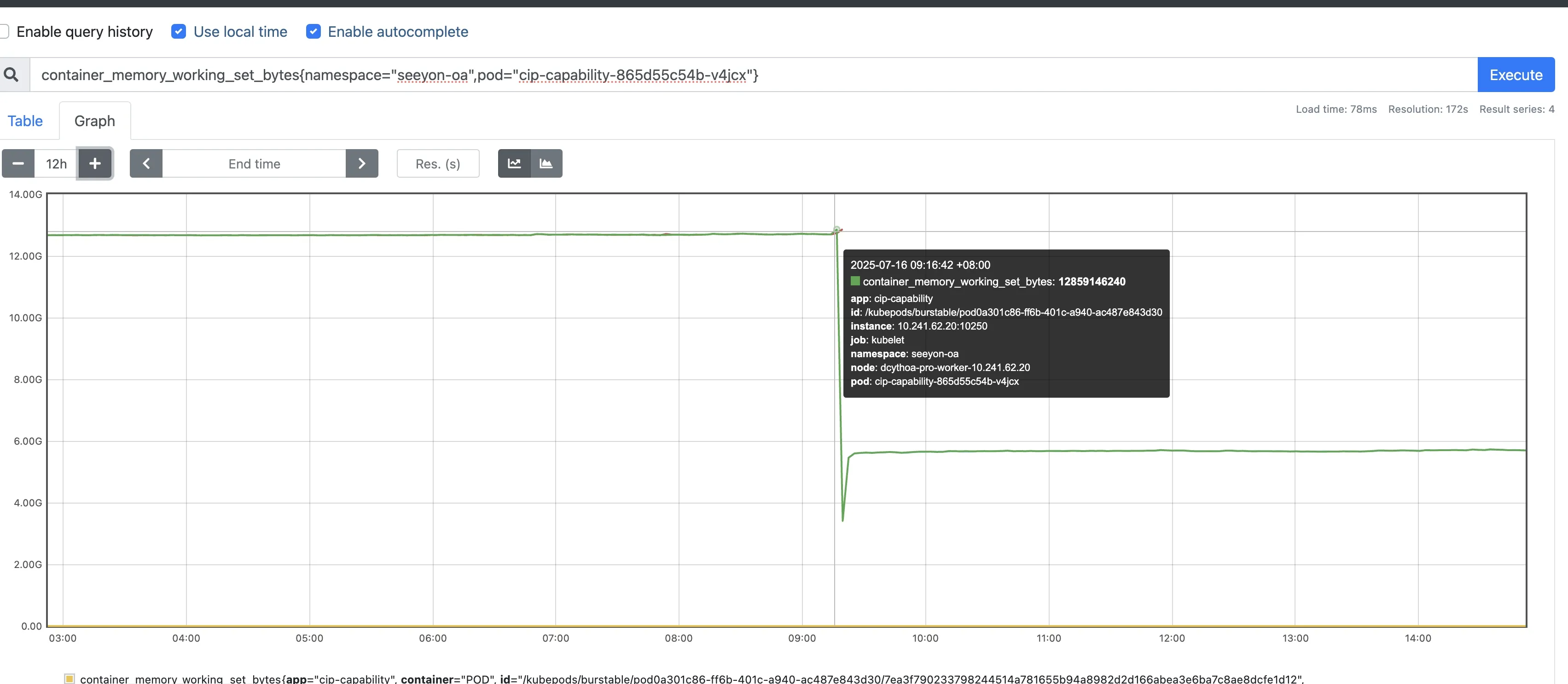
虽然pod发生重启,但是影响面不应该这么大,继续深入排查
大面积异常,通常是服务有共性调用、共性入口,继续排查网关和nginx
排查网关日志,期间无异常
排查nginx日志,发现error.log中存在异常worker_connections are not enough while connectiong to upstream
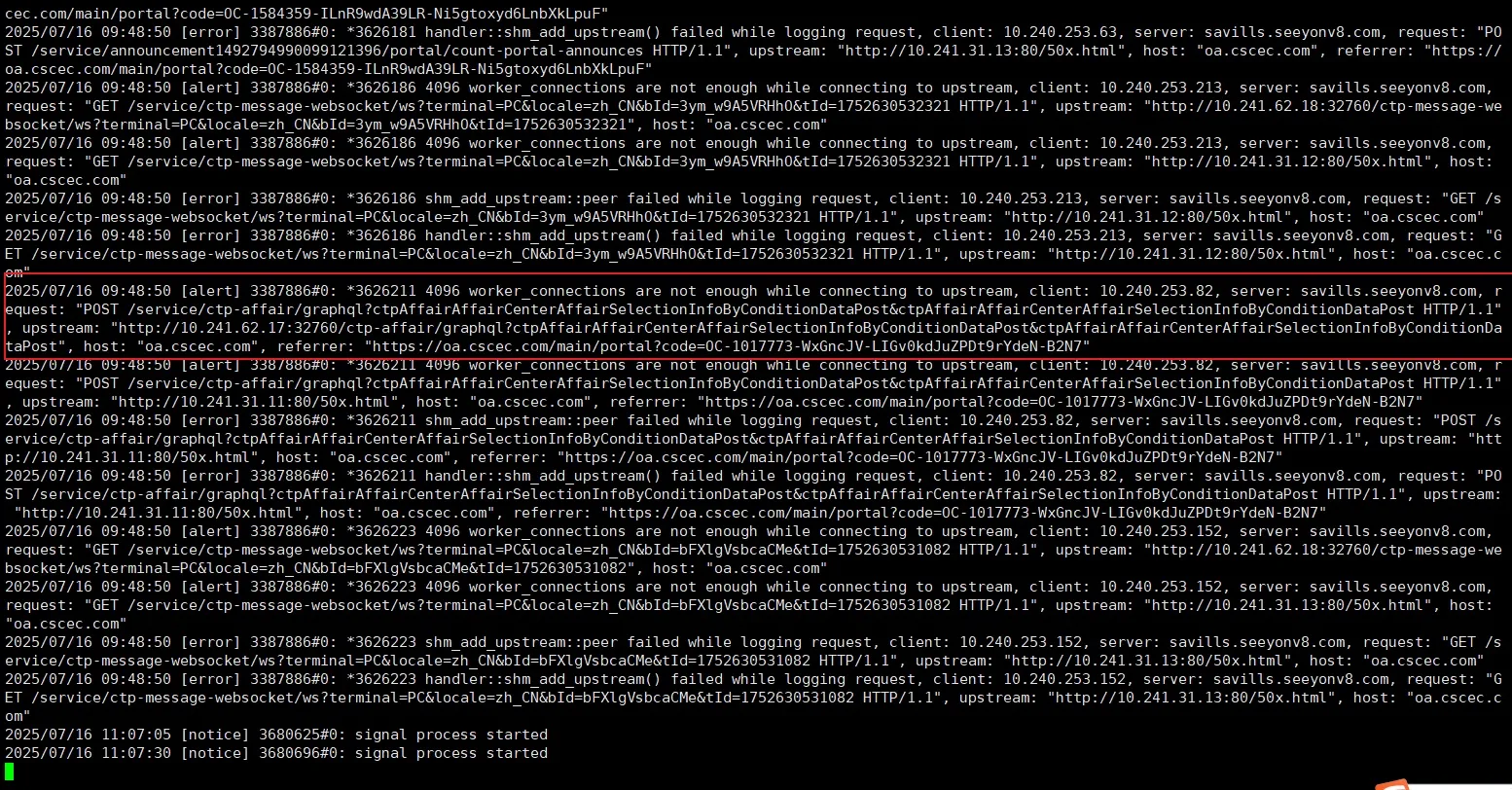
检查nginx配置,
worker_connections 4196,翻倍调整为8192,报错消除。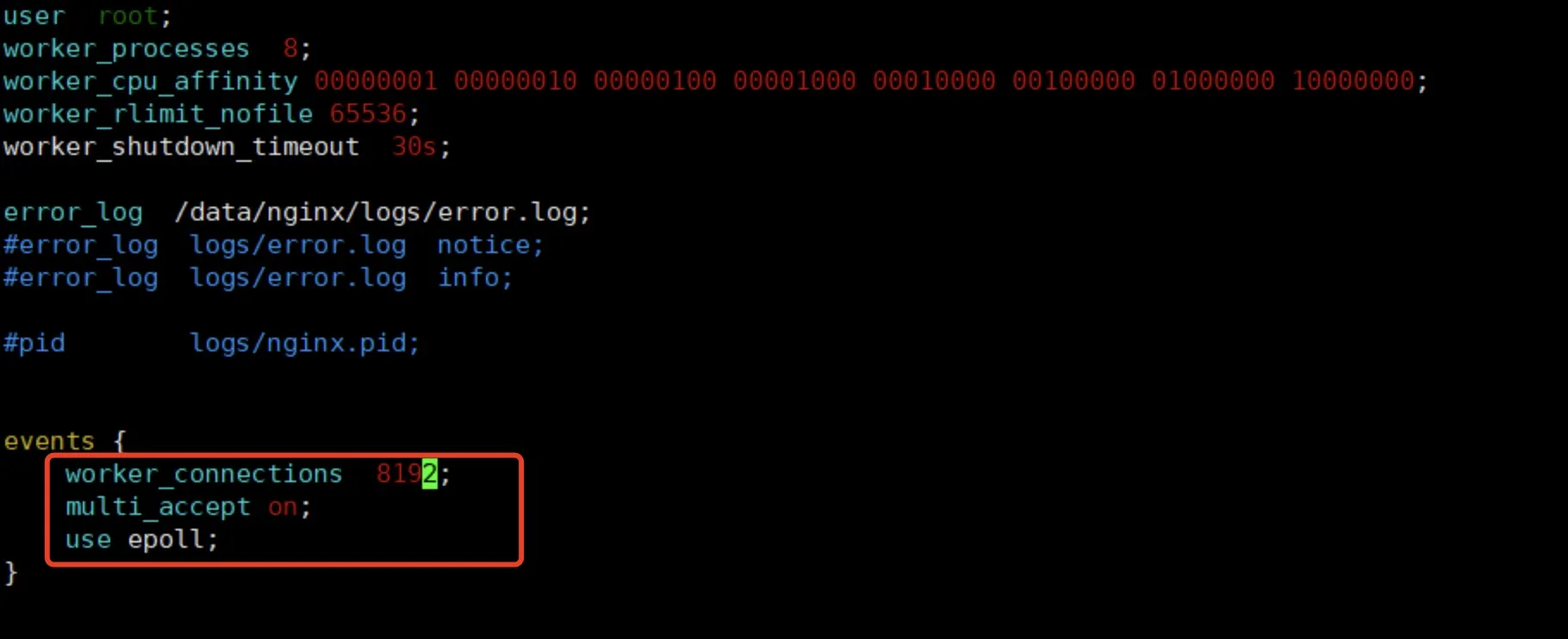
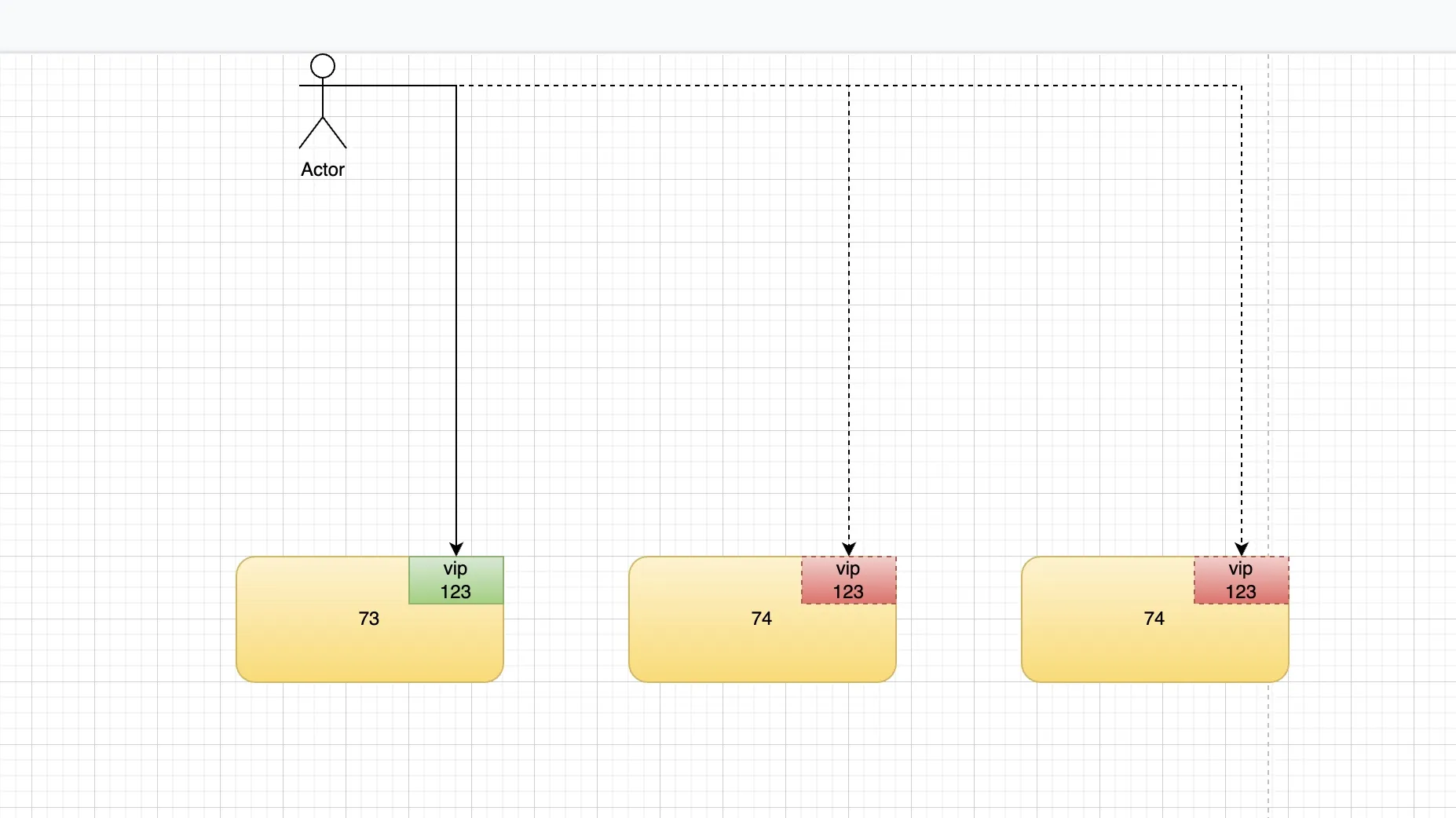
排查过程中发现,该环境共有三个nginx组成集群,但真实使用的nginx只有一个。如图
- 建议调整为下图
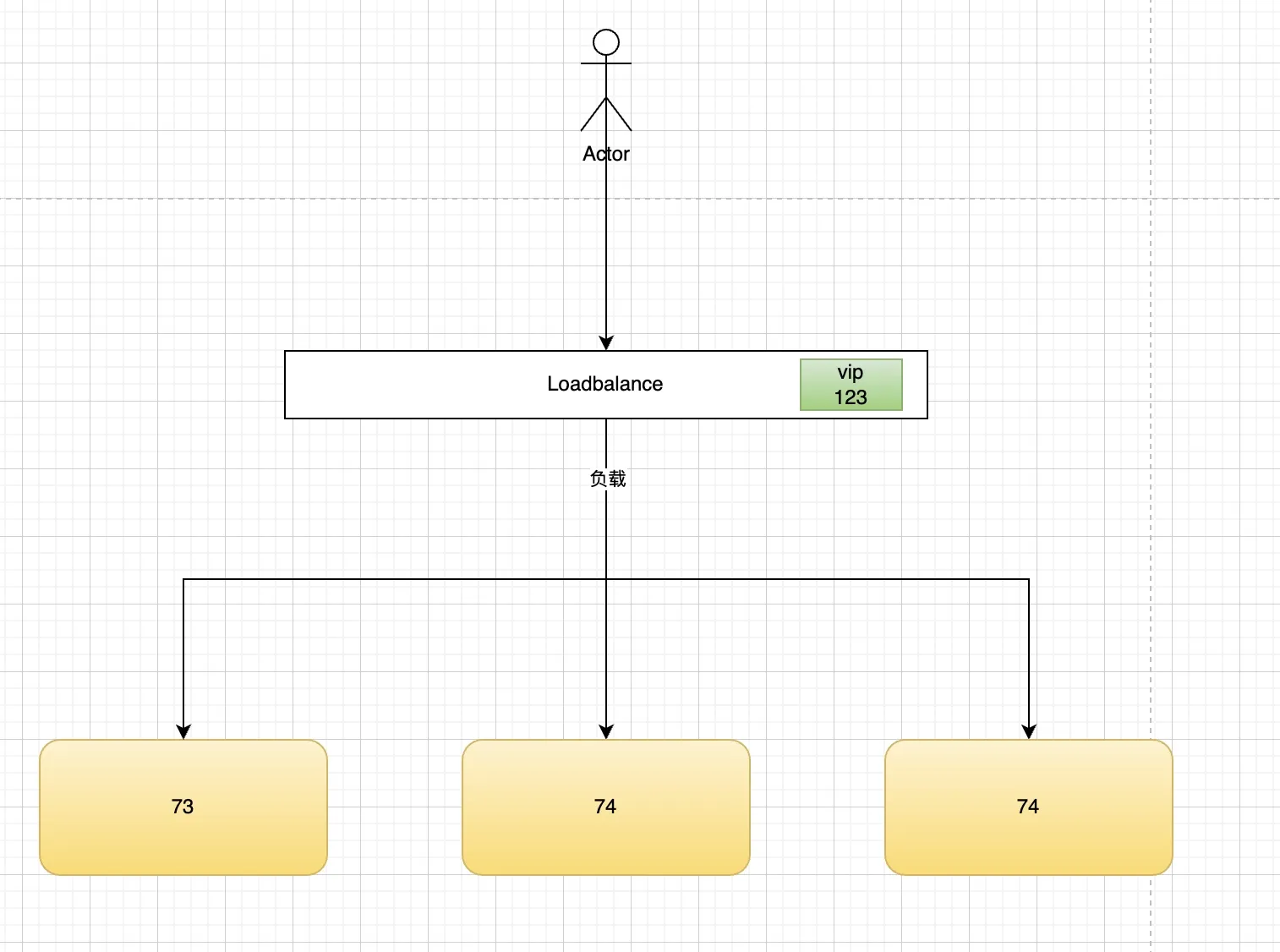
- 调整后异常消除
# 故障定位
问题1:pod 内存占用大于limit,在Kubernetes集群维度被kill掉
问题2:nginx worker_connections配置较小,无法接收更多连接。当连接数大于原4096之后,连接将会进入等待或者超时状态。前端访问的过程中,前端有超时异常捕获(15秒熔断),页面返回10003。
# 问题解决
# 问题1
- 两个方案
- 临时方案:调整limit配置,需要更多资源
- 根本解决:研发分析内存占用,提供更合理的资源需求
# 问题2
- 调整nginx
worker_connections翻倍,最终值需要结合nginx监控暴露出来的连接数信息动态调整
# 后续整改
- 排查过程中发现Kubernetes集群中,内存资源利用分摊不均,易触发资源驱逐,可参考该链接调整控制器的QOS:https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/pod-qos/#guaranteed 尽量保证resources.requests和resources.limits保持一致,达到Guaranteed级别。同时希望将requests值设置为接近真实占用的值,避免出现资源超卖的场景
- 将nginx调整为三节点都存活的架构,保证高可用
- 增加监控告警预警,确定能否提供邮箱,供告警推送使用
编撰人:zhenxy、het
