# K8s Java 全景诊断雷达操作手册
适用人群 :新手运维、刚接触K8s/Java应用排查的人员。
适用场景 :客户系统环境异常变慢、客户系统服务异常重启、随巡检周期一起进行容器巡检诊断。
核心目标 :无需复杂命令,按步骤操作,快速完成K8s集群Java应用诊断,获取可视化报告。
前置说明 :工具仅支持Linux系统(amd64架构),需在K8s Master节点运行,确保节点能正常访问K8s集群和目标Pod。
# 采集内容说明:
| 一级分类 | 二级分类 | 采集内容 | 说明 |
|---|---|---|---|
| 应用 | Node | 节点 CPU/内存容量与使用率 | 通过 kubectl get nodes、kubectl top nodes 采集 |
| 应用 | Node | 节点磁盘容量与使用率 | 通过 stats/summary 采集节点磁盘容量、使用率 |
| 应用 | Node | 节点 OS 异常日志 | 采集 OOM-killer、kernel panic、segfault、reboot 等 |
| 应用 | Pod | Pod 拓扑与归属关系 | 采集 Namespace、Pod、所在 Node、状态 |
| 应用 | Pod | Pod 重启、退出码、 | 重启原因从 containerStatuses 提取 |
| 应用 | Pod | Pod Warning 事件 | 通过 kubectl get events 采集 |
| 应用 | Pod | Pod CPU/内存 request、limit | 从 Pod Spec 中汇总容器资源配额 |
| 应用 | JVM | Java PID 探测 | 通过 jcmd、jps 探测 |
| 应用 | JVM | GC 指标 | 采集 YGC、FGC、老年代、元空间等 |
| 应用 | JVM | 线程诊断 | 采集 jstack、死锁、热点线程、阻塞线程 |
| 应用 | JVM | 对象增长/泄漏嫌疑 | 通过 jmap 直方图差值识别 |
| 应用 | 配置 | JVM 启动参数 | 解析 Xms、Xmx、Metaspace、HeapDump、ErrorFile |
| 应用 | 配置 | Dump/ErrorFile 路径与卷挂载风险 | 检查路径存在性、挂载卷类型、持久化风险 |
| 应用 | 性能 | Pod/节点 CPU 趋势 | 通过 kubectl top 周期采样 |
| 应用 | 性能 | Pod/节点内存趋势 | 通过 kubectl top 周期采样 |
| 应用 | 性能 | 网络流量 | 通过 /proc/net/dev 采集收发流量 |
| 应用 | 性能 | TCP 连接状态 | 采集 ESTABLISHED、CLOSE_WAIT 数量 |
| 应用 | 性能 | 磁盘读写与磁盘空间 | 采集 blkio/io.stat 与 df / |
| 应用 | 诊断 | 健康等级与风险结论 | 输出 success/warning/danger 和诊断消息 |
| 应用 | 输出 | JSON/CSV/HTML 报告 | 生成结构化结果与可视化页面 |
# 操作视频与工具
** k8s_scan-linux-amd64工具操作视频:** https://fcndlqpk2w3r.feishu.cn/wiki/XWyYw7VCgikZ9ZkgdUoclhqlnGh?fromScene=spaceOverview
** k8s_scan-linux-amd64工具下载地址:** https://frontend-project-dev.oss-cn-beijing.aliyuncs.com/software/k8s_scan-v1.1.3.zip
# 第一章:前期准备(必做,否则无法正常运行)
1.1 工具获取与放置
将工具文件 k8s_scan-linux-amd64 上传至K8s Master节点或运维机的的任意目录(推荐目录:/data/tool/k8s_scan,后续所有操作均在此目录执行)。
上传后,进入工具所在目录: cd /data/tool/k8s_scan
1.2 给工具添加执行权限
工具默认没有执行权限,直接运行会报错"Permission denied",必须执行以下命令授权:chmod +x ./k8s_scan-linux-amd64
验证:输入 ls -l,查看工具文件权限,若显示"-rwxr-xr-x",说明授权成功。
1.3 必备环境检查
检查kubectl权限(工具依赖kubectl获取集群信息):kubectl get pods,能正常显示Pod列表即正常;若报错"command not found",需先安装kubectl。
检查磁盘空间:工具会生成报告,需预留至少1GB空闲空间,检查命令:df -h,查看当前目录所在磁盘的空闲空间(可用值≥1G即可)。
时间同步:确保Master节点时间与集群其他节点一致,避免Prometheus指标拉取错乱,无需手动操作,确认节点时间正常即可。
# 第二章:配置文件修改
工具支持两种运行方式:通过配置文件运行(推荐新手)、通过命令行参数运行(快速排查),优先讲解配置文件方式,配置文件名为config.yaml。
配置文件模板:
# ---------------------------------------------------------------------
# 1. 目标过滤配置 (Target Filtering)
# ---------------------------------------------------------------------
# 目标 Namespace。如果留空 (""),则扫描全集群所有 Namespace。
target_namespace: "seeyon-xxx"
# 目标 Pod 关键字过滤 (数组格式)。
# 只要 Pod 名称中包含以下任意一个关键字,就会被纳入扫描范围。
# 如果留空 (不写任何 - "xxx"),则代表不限制,扫描该 Namespace 下的所有 Pod。
target_pods:
- "ai"
- "ctp-webapi-gateway"
- "ctp-user"
# ---------------------------------------------------------------------
# 2. 宏观指标配置 (Prometheus Integration)
# ---------------------------------------------------------------------
# Prometheus 的 API 地址。
# 如果配置了此项,脚本会额外拉取过去 30 分钟的 CPU 峰值和异常重启增量。
# 如果留空 (""),则跳过宏观指标拉取,仅做本地 15 秒微观采样。
prom_url: "http://xxx.xxx.xxx.xxx:xxx"
# ---------------------------------------------------------------------
# 3. 资源水位告警阈值 (Resource Thresholds)
# ---------------------------------------------------------------------
# Node 节点 CPU 使用率危险阈值 (%)。超过此值,Node 卡片会标黄警告。
node_cpu_danger_pct: 85.0
# Node 节点物理内存使用率危险阈值 (%)。超过此值,Node 卡片会标黄警告。
node_mem_danger_pct: 85.0
# Pod 容器物理内存 (Cgroup) 使用率危险阈值 (%)。
# 计算公式: 实际使用量 / Limit 限制量。超过此值,极易触发 OOMKilled,会标红警告。
pod_mem_danger_pct: 90.0
# ---------------------------------------------------------------------
# 4. 网络与 JVM 诊断阈值 (Network & JVM Diagnostics)
# ---------------------------------------------------------------------
# TCP CLOSE_WAIT 状态连接数警告阈值 (个)。
# 超过此值,说明代码中可能存在未正常 close() 的连接,存在连接池泄漏风险。
tcp_wait_warn: 50
# 采样窗口期内,Full GC 发生次数的危险阈值 (次)。
# 只要达到或超过此值,说明 JVM 正在经历严重的 Stop-The-World 停顿,会标红警告。
fgc_danger: 1
# JVM 老年代 (Old Gen) 内存使用率警告阈值 (%)。
# 超过此值,说明濒临 Full GC 边缘,或者存在内存泄漏,会标黄警告。
old_gen_warn: 85.0
# 内存泄漏判定最小增量 (Bytes)。默认 1048576 Bytes = 1MB。
# 在 T0 和 T15 两次 Jmap 快照对比中,如果某类对象的净增长超过此值,会被列为泄漏嫌疑对象。
leak_min_bytes: 1048576
# ---------------------------------------------------------------------
# 5. 动态采样引擎配置 (Sampling Engine)
# ---------------------------------------------------------------------
# 每次资源采样 (CPU/Mem/IO/Net) 的间隔时间 (秒)。
sample_interval: 3
# 资源采样的总次数。
# 总诊断耗时 ≈ sample_interval * sample_count。默认 3 * 5 = 15 秒。
sample_count: 5
2.1 配置文件获取与放置
将配置文件 config.yaml 上传至工具所在目录(与 k8s_scan-linux-amd64同目录)。
确认文件存在: ls -l,能看到config.yaml 即正常。
2.2 配置文件核心修改(仅改3处,其余默认不动)
用文本编辑器打开配置文件: vi config.yaml
打开后,找到以下3处,修改为自己集群的信息,修改后按 i 开始编辑,按Ctrl+X 退出编辑器。
修改1:目标命名空间(必填)
找到 target_namespace: "seeyon-xxx",将双引号内的内容改为你要扫描的K8s命名空间。
修改2:目标Pod关键字(必填)
找到target_pods:,下方的列表是需要扫描的Pod关键字,只保留你关心的应用名。 示例: 若只扫描包含"ai"和"ctp-webapi"的Pod,修改后如下:
target_pods:
- "ai"
- "ctp-webapi"
说明:只要Pod名称包含列表中的任意一个关键字,就会被扫描;若留空(不写任何"-xxx"),则扫描该命名空间下所有Pod(不推荐,容易超时)。
修改3:Prometheus地址(可选)
找到 prom_url: "http://xxx.xx.xx.xx:xxxx",有两种情况:
有Prometheus服务:将双引号内的地址改为自己的Prometheus地址(如http://10.1.1.1:9090),确保之前执行的curl命令能连通。
无Prometheus服务:直接将双引号内内容清空,改为 prom_url: "",工具会跳过宏观指标拉取,仅做本地采样。
# 第三章:工具运行
所有操作均在工具所在目录(/data/tool/k8s_scan)执行,运行时不要关闭终端,等待诊断完成。
命令(直接复制执行,无需修改): ./k8s_scan-linux-amd64 -c config.yaml
运行后,终端会打印进度日志,正常进度如下(无需关注中间细节,等待最后提示即可)
[root@master k8s_scan]# ./k8s_scan-linux-amd64 -c config.yaml
2026/04/15 16:08:54 === K8s Java 全景诊断雷达 (v14.0.0-Capacity-Pro) ===
2026/04/15 16:08:54 [1/6] 解析集群拓扑、资源配额与精准过滤 Pod...
2026/04/15 16:08:55 [2/6] 穿透采集 Node OS 日志与 K8s 事件 (死亡溯源)...
2026/04/15 16:08:56 [4/6] 启动全维动态采样引擎 (CPU/Mem/IO/Net/JVM)...
2026/04/15 16:08:56 [3/6] 异步拉取 Prometheus 宏观指标 (过去30分钟)...
2026/04/15 16:08:56 -> 计划从 Prometheus 拉取 10 个 Pod 的指标 (并发度: 5)...
2026/04/15 16:09:06 [进度] Prometheus 指标拉取中: 5/10 (50%)
2026/04/15 16:09:16 [进度] Prometheus 指标拉取中: 10/10 (100%)
2026/04/15 16:09:16 -> Prometheus 指标拉取完毕。
2026/04/15 16:09:21 [5/6] 运行智能诊断与大盘数据组装...
2026/04/15 16:09:21 [6/6] 导出结构化数据与全景可视化 HTML 报告...
2026/04/15 16:09:21 === 诊断完成 | 耗时: 26.402950185s | 报告目录: output/radar_report_20260415_160854 ===
将结果文件夹压缩打包,发出做分析即可。
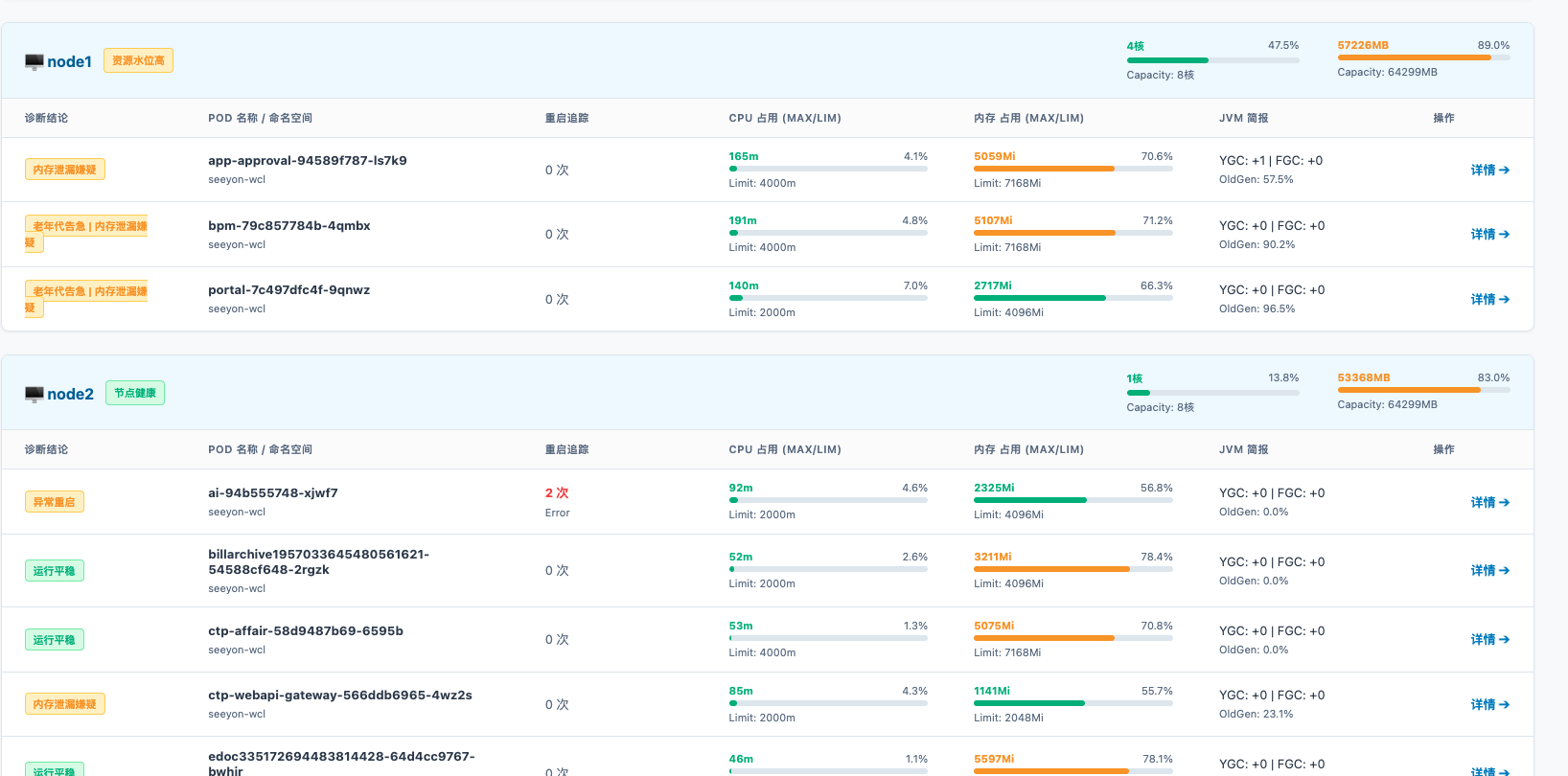
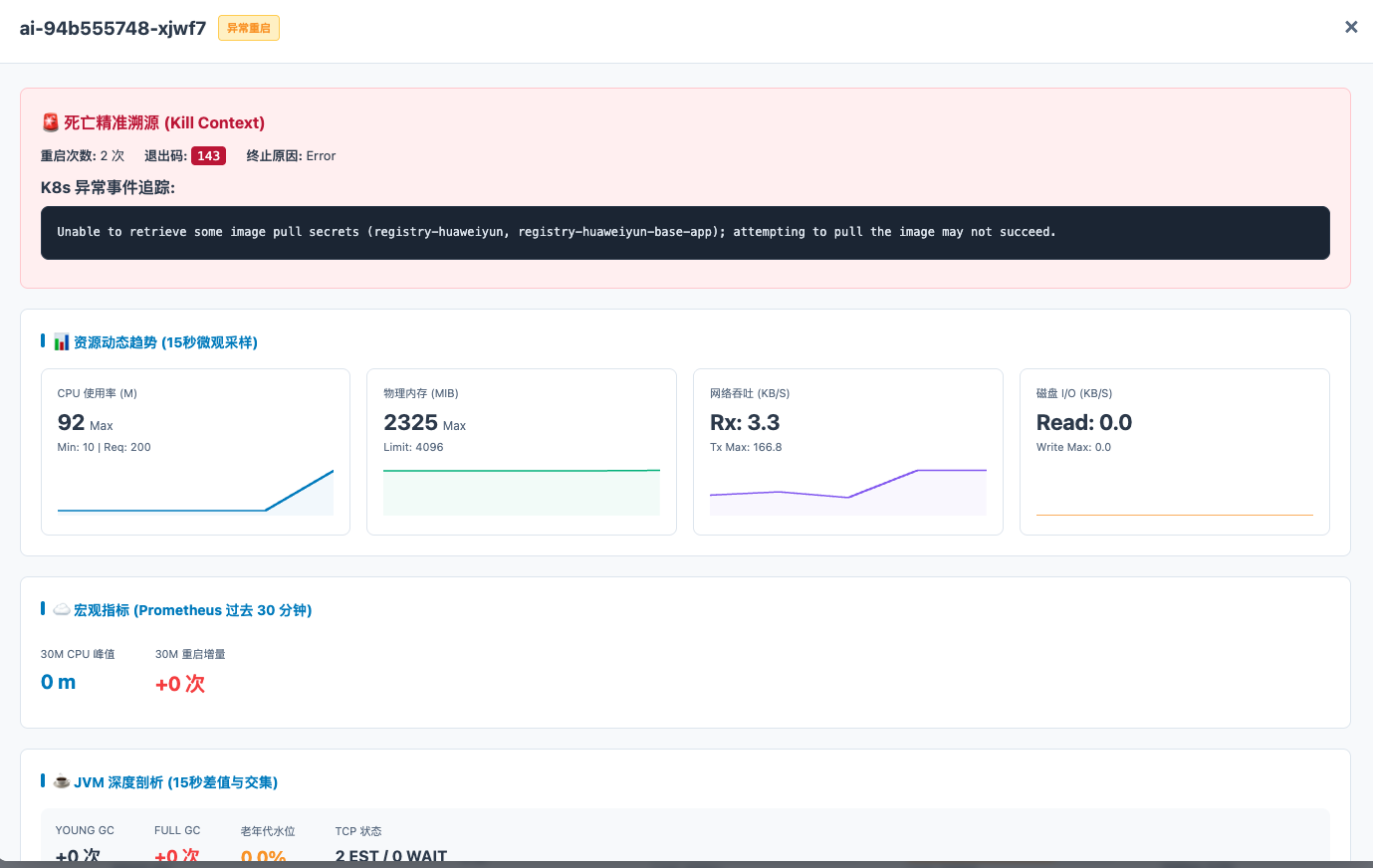
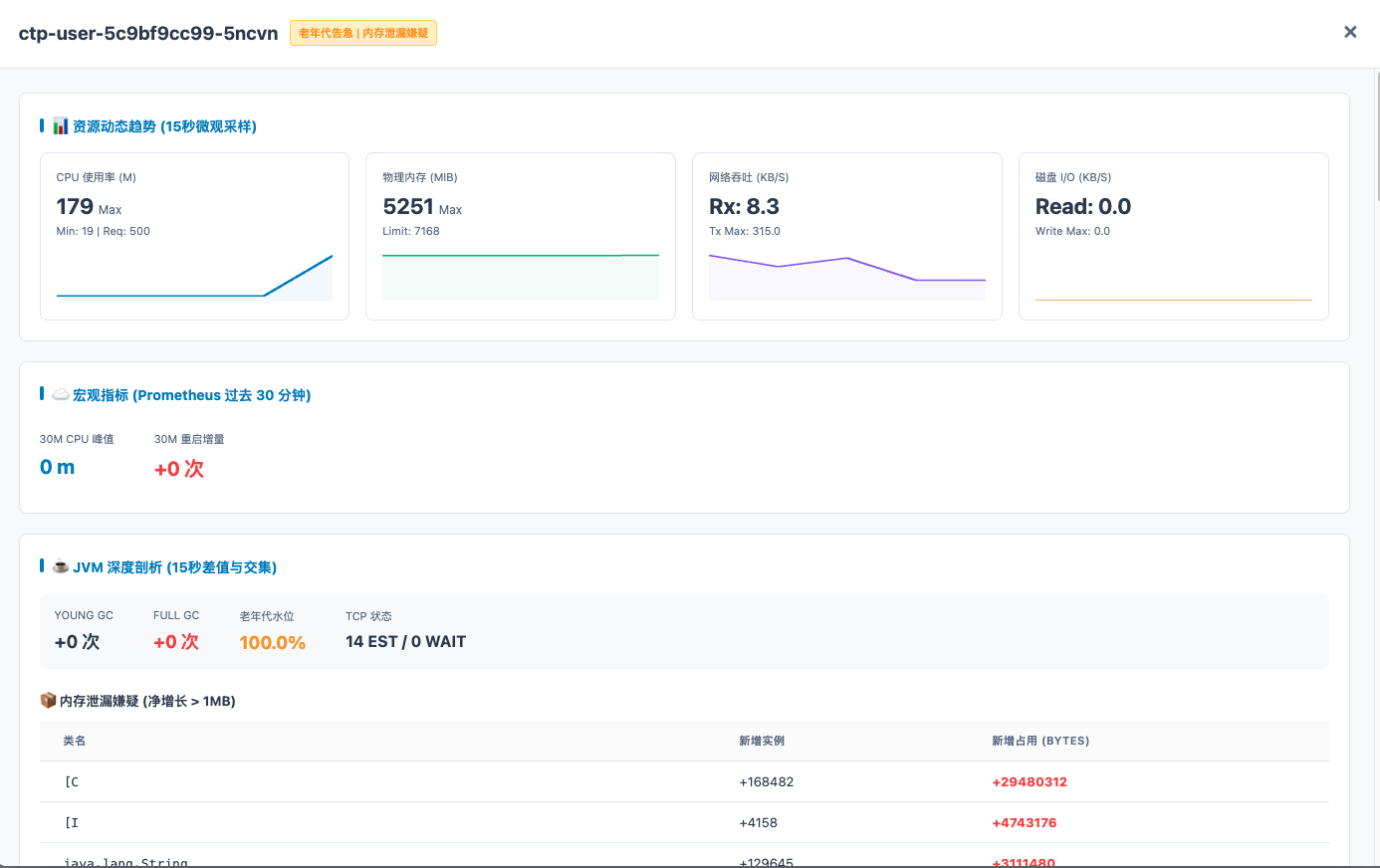
结果页面示例: