常见服务监控查看
监控中重点关注如 延迟信息、cpu使用率、内存使用率、fullgc、磁盘、线程排队等,如发现相关指标飙高,可考虑优先增加对应资源配置,后快速恢复服务(如常见增加内存配置)。
根据监控中异常指标,确定主要的分析路劲,结合日志等重点分析异常指标关联业务。
将监控时间段调整至服务异常时间段,然后查看:
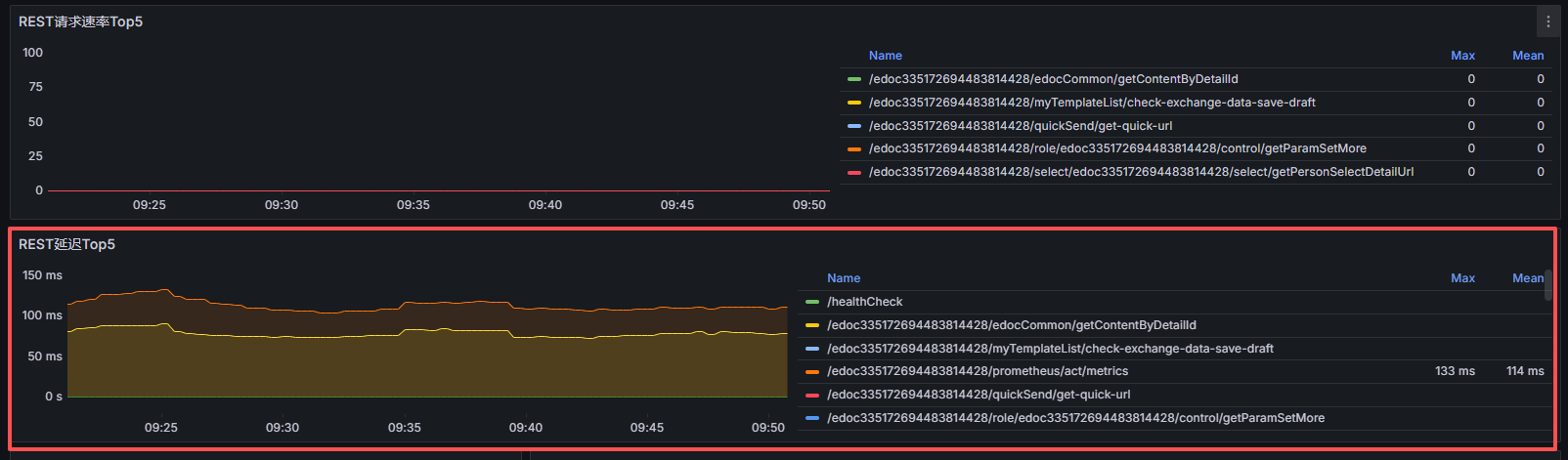
Rest相关
重点关注高延迟rest请求,如出现单个请求耗时很高或top5的请求都很高,重点进入日志分析相关http线程请求信息。
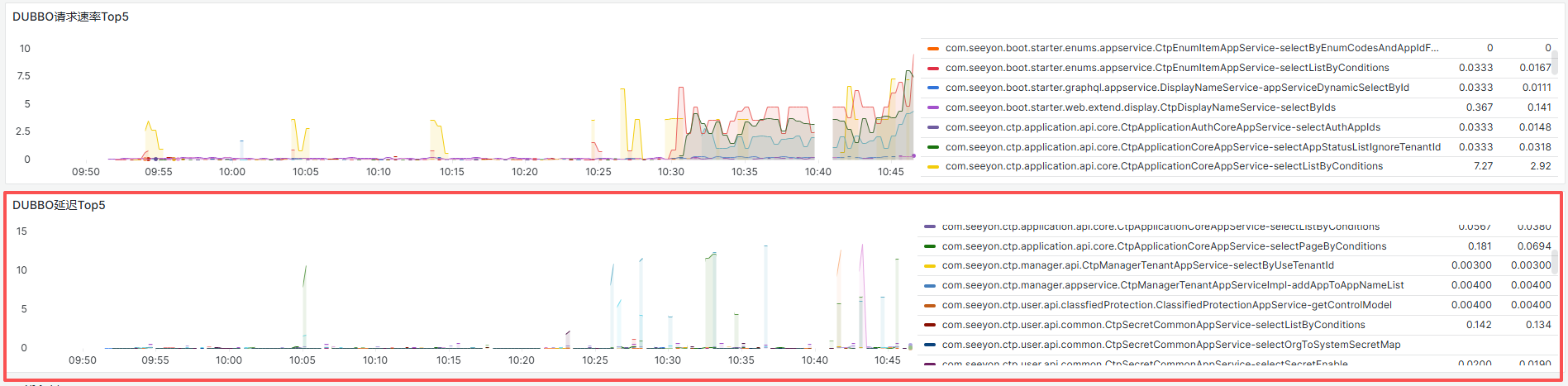
dubbo相关
重点关注高延迟dubbo请求,如出现单个dubbo耗时很高或top5的dubbo耗时都高,查看服务日志重点查看dubbo相关信息。
线程相关
关注当前活动线程数占比最大线程比率,关注线程队列,如果活动线程数高,则表明异步任务量大,服务负载较高;如果线程队列值不为0 ,表明有任务排队的现象。可进入日志进一步分析。

Redis相关
关注速率和执行失败数,如出现速率接近或超过500,可表明服务业务负载高;如出现执行失败的,表明服务redis请求存在失败情况,要进入日志重点分析。

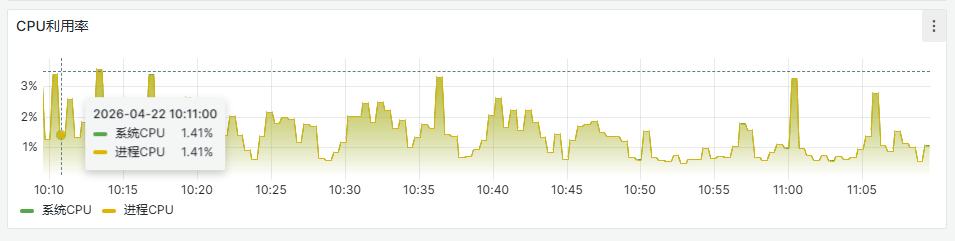
CPU相关
查看CPU使用情况,是否使用率超过80%,如果出现则考虑服务高负载,进入日志重点分析是什么业务触发。
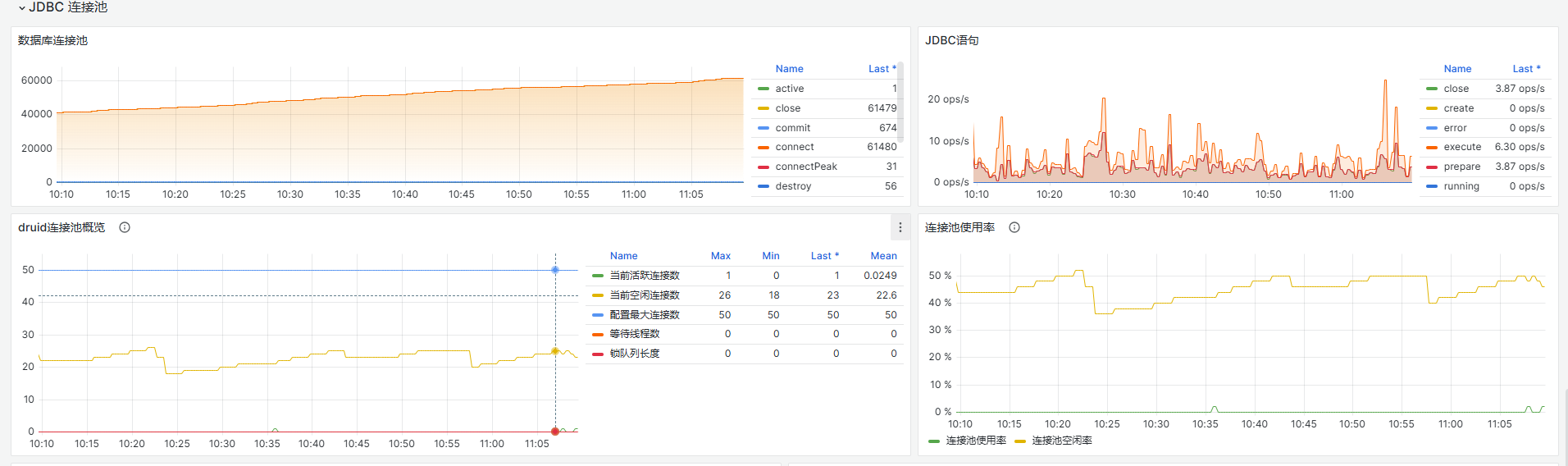
SQL连接池
根据客户现场的配置,如果采用的dbpool,则关注 表: 数据库连接池,如果配置的druid,则关注表:druid连接池概览,查看是否存在连接池使用率高的情况,如果存在,结合日志重点查看。
内存使用
堆使用率和元空间使用率,如果堆使用率高,可结合日志重点分析大内存占用业务点;如果元空间使用率高,重点分析表单相关业务,进一步通过日志进行分析。

GC情况
关注是否近期是否存在高频YGC或fullGC,如果YGC频次很高或短时间出现多次fullGC,则表明服务有内存不足风险,关注相关大内存使用点业务。结合日志进一步分析。

其他更多监控图表信息,根据具体问题表象而定,看是否需要进一步查看和分析。监控主要查看相关指标的变化趋势等,相关指标的异常,可以大体定位到服务状态异常或恶化的方向,但具体的异常原因等还需结合日志等多个分析维度进一步定位。
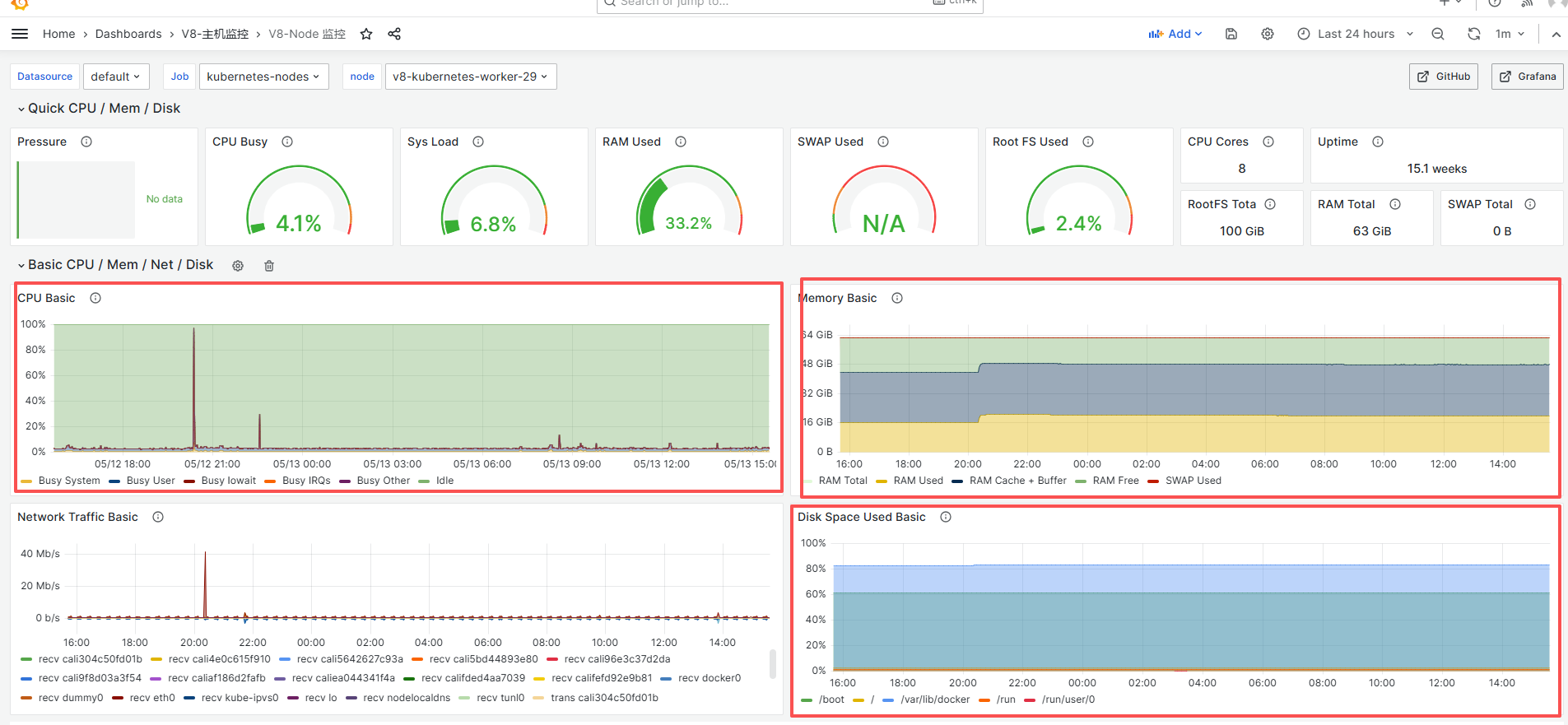
服务器监控
查看k8s主机监控信息页面,重点关注图表中服务器的cpu、内存、磁盘等指标,检测是否存在高负载的异常指标。