1.适用范围
适用于以下场景:
- 页面访问突然变慢
- 后端接口请求大面积超时或响应时间显著上升
- 系统在某一时间点后整体性能明显下降
- K8S、微服务、Nginx 代理、数据库、Redis、Kafka 等任一环节异常导致整体变慢
不适用于以下场景:
- 单个用户本地网络异常
- 单个浏览器缓存或插件问题
- 长期性能偏低但并非突发异常
2. 问题现象和排查目标
系统整体变慢时,优先要判断问题属于哪一层:
- 前端处理慢
- 网络链路慢
- nginx/网关组件慢
- 后端接口慢--重点分析
- 中间件慢--重点分析
- 基础设施或部署资源问题--重点分析
3. 快速排查流程
可优先重点排查高概率方向
系统整体变慢
├── 前端页面加载慢(低概率)
│ ├── YES → 转入前端页面慢问题SOP
│ └── NO → 继续排查
├── 检测是否网络慢(低概率)
│ ├── YES → 转入网络慢问题SOP
│ └── NO → 继续排查
├── nginx服务慢(低概率)
│ ├── YES → NG慢分析sop
│ └── NO → 继续排查
├── 网关服务慢(低概率)
│ ├── YES → 网关服务慢异常SOP
│ └── NO → 通用慢问题SOP
└── 后端接口慢(高概率,重点)
├── 服务节点状态异常,宕机/假死等
├── CPU打满/Load高
├── 内存不足/OOM
├── 慢SQL
├── 慢Redis操作
├── 消息消费链路变慢
├── dubbo请求慢
└── 其他:发版变化导致变慢
4. 快速判断
4.1 快速判断法
- 确认是否为全局现象,还是局部业务现象。
|---如果局部慢问题,可初步排除网络和ngnix/网关服务问题
- 打开浏览器
F12 -> Network,查看请求处理耗时。
|---如果查看接口耗时基本都在150ms以内,初步定位是前端问题.
|---如果存在接口耗时高(有大于500ms或者达到几秒),初步定位后端问题
- 确认近期是否有发版、配置变更、节点波动、Pod 重启。
|---如果有相关变动后出现异常,优先考虑和表格是否关联。
- 查看核心监控 CPU、内存、磁盘 IO、网络带宽、错误率突增等指标异常(如:超过图表中风险阈值)。
|--- 通过耗时高接口初步筛选异常应用,然后查看应用的上述监控指标。
|--- 是否收到相关告警信息,如有相关告警,请优先分析告警相关异常点。
- 查看数据库、Redis、Kafka、网关、Nginx 是否同时出现耗时升高。
- 考虑是否业务量突增,导致服务负载升高后慢问题。
4.2 快速判断决策表
| 现场特征 | 关键观察点 | 初步判断 | 下一步 |
|---|---|---|---|
| 页面白屏,接口返回慢 | Network 中 请求 Waiting (TTFB) 高 | 后端或网络慢 #6. 判断 是否网络慢(低概率,高风险) | 先查网络和后端接口 |
| 页面很快出来,但图片、JS、CSS 很慢 | 静态资源请求耗时高 | 前端资源链路慢 #5. 判断:是否前端页面慢(低概率) | 查 MinIO、Nginx组件和静态资源体积 |
| 接口普遍都慢,静态资源也慢 | 小文件请求也慢,耗时波动大 | 网络或节点资源问题 #6. 判断 是否网络慢(低概率,高风险) | 查链路延迟、丢包、节点负载 |
| 仅某几个接口慢 | 某些 API TTFB 高,其他接口正常 | 特定后端服务慢 #9.判断:后端服务问题(高概率,重点分析) | 查该服务日志、内存、线程、GC等 |
| 某时段突然整体变慢 | 故障有明确时间拐点 | 变更、资源抢占或中间件抖动、业务量激增 | 对齐事件、监控、发布记录 |
5. 判断:是否前端页面慢(低概率)
快速判断:
- 如果
接口响应时间长,尤其是TTFB很高,通常偏后端或链路问题。 - 如果
接口很快返回,但页面还是白屏久、点击后卡顿、列表渲染慢,通常偏前端问题。 - 如果首屏资源
JS/CSS/图片下载很慢,可能是前端资源体积、CDN、缓存策略或网络问题,大概率不是后端业务接口本身。 - 如果是“偶发慢”,要重点排查
接口抖动、前端长任务、浏览器缓存失效、第三方脚本。
具体操作:
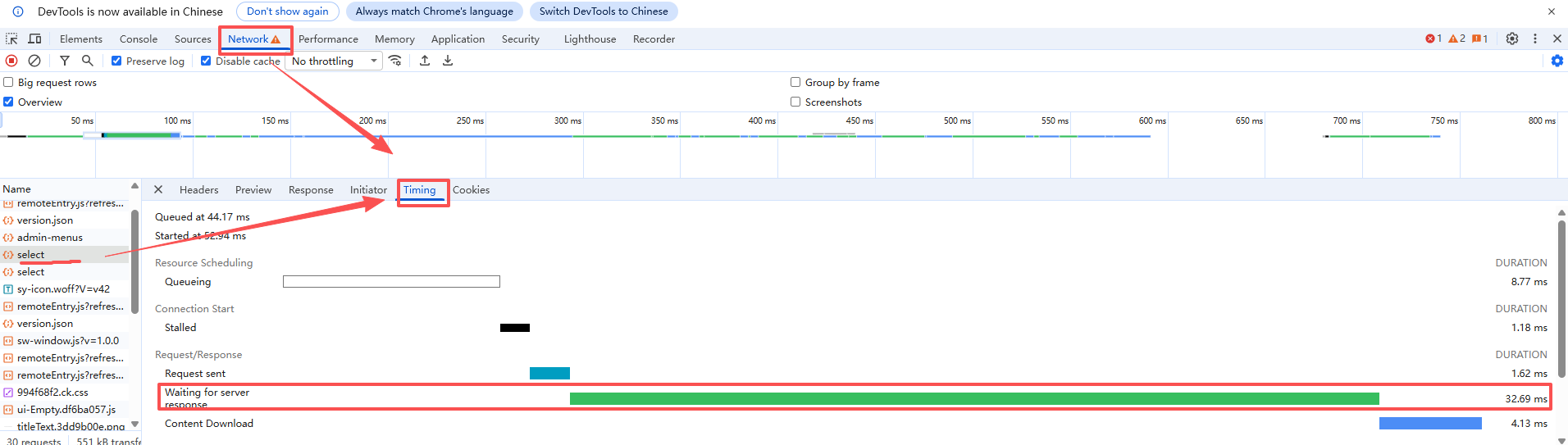
1、如上图,浏览器F12打开调试界面,找到耗时长的相关接口,进入Timing,查看请求各阶段耗时:
1.1 Waiting for server response (TTFB)` 很长
说明请求发出后,服务器很久才开始返回,优先怀疑后端处理慢、网络慢等,初步排除前端问题。
1.2 `Content Download` 很长
说明返回体过大,可能是接口返回数据过多,也可能是网络带宽问题。
1.3 `JS/CSS/图片` 下载很慢
更偏静态资源问题,如包太大、CDN慢、缓存没命中、图片未压缩,分析可偏网络,NG/网关等方面。
1.4 请求都很快,但页面迟迟不展示
更偏前端解析、执行、渲染、数据处理问题,可分析为前端问题。2、多查看相关接口,查看现象是否1中分析的结论一致。如果一致,则可跳过前端问题,继续后续其他方向分析。
3、如果初步考虑前端问题,确认进一步判断:
3.1. 同一个接口,在 `浏览器` 和 `Postman/curl` 都慢
大概率是后端接口慢,不是前端页面问题。
3.2 接口在 `Postman` 很快,但页面里慢
说明可能不是后端本身,而是前端问题,可能触发方式、串行请求、重复请求、阻塞渲染等问题。
3.3 多个页面都卡在同一个接口
优先查后端。
3.4 只有某个页面卡,但接口平均耗时正常
优先查前端页面实现。结论:
前端慢: 上述分析策略如果初步确认为前端问题,联系研发前端同时介入分析。
否则:继续后续分析...
6. 判断: 是否网络慢(低概率,高风险)
出现下面这些特征,网络问题的可能性比较大:
1. 同一个接口或文件,在不同网络环境下耗时差异很大
2. `DNS`、`TCP连接`、`SSL握手`、`下载传输` 耗时明显偏高
3. 服务端处理时间正常,但客户端总耗时很长
4. 某个地区、某个运营商、某个办公网、某条 VPN/专线特别慢
5. 切换热点、家宽、VPN 开关后,性能明显变化
6. 同时影响多个系统,不只是某一个页面具体操作:
1、判断网络问题最有效的是对比,做这几组对比:
1. `同一台机器,不同网络`
2. `同一网络,不同机器`
3. `客户端访问` vs `服务端访问`
4. `公司内网` vs `手机热点`
5. `开VPN` vs `关VPN`
6. `本地用户` vs `异地用户`如果上述几种不同网络环境测试,发现接口耗时差异较大,可判断为网络问题,否则进行其他方面分析。
2、进一步确认:可直接登录应用服务器,用curl 等方式确认慢接口,如果再应用服务器curl对应接口不慢,但是客户端访问慢,可推测为请求链路中网络问题导致。 如果服务器测试该接口,发现也很慢,则可初步排除网络问题,直接进行服务接口慢分析。
常见curl命令使用案例:
-- 基本 GET
curl https://dev.seeyonv8.com/main/builds/ui-Empty.df6ba057.js
-- GET 携带cookie
curl -b "session_id=abc123; user_token=xyz456"
https://dev.seeyonv8.com/service/portal/main/admin-menus
-- POST
curl -X POST https://api.example.com/users \
-H "Content-Type: application/json" \
-b "session_id=abc123; user_token=xyz456"
-d '{"name":"John","age":30}'结论:
确认网络问题:联系客户相关负责人,修复网络问题。
否则:继续后续分析...
7. 判断:是否为Ngnix服务慢(低概率)
Nginx服务异常概率较低,可优先排查其他方向。
要确认是否是 Nginx 导致,链路可简单拆成:
1. 客户端 -> Nginx (请求request)
2. Nginx -> 应用 (请求request)
3. 应用处理 (服务处理请求)
4. 应用 -> Nginx (返回response)
5. Nginx -> 客户端 (返回response)快速判断:
1. 如果 `客户端总耗时高`,但 `应用处理很快`,且慢点集中在 Nginx 前后,怀疑 Nginx
2. 如果 `Nginx 到应用的连接/等待很长`,可能是 Nginx 与应用通信配置或转发问题
3. 如果 `应用返回给 Nginx 很快,但 Nginx 回客户端很慢`,可能是 Nginx 出口带宽、缓冲、限速、磁盘写临时文件等问题
4. 如果 `Nginx access log` 显示请求总耗时高,但 `upstream_response_time` 很低,说明慢不主要在上游应用,Nginx 自身或客户端链路值得重点排查
5. 如果 `upstream_response_time` 本身就高,更多是上游服务慢,不是 Nginx 本身慢Nginx慢的常见表现包括:
1. `accept backlog`、连接数高,导致新连接处理慢
2. `keepalive` 没配好,频繁建连等配置不合理
3. 限流、连接限制误伤
4. 磁盘 I/O 慢,导致临时文件写入慢
5. worker 进程 CPU 打满或连接数达到瓶颈结论:
确认Nginx问题:联系相关运维优化调整nginx配置等进行恢复
否则:继续后续分析...
8.判断:是否为网关服务慢(低概率)
首先确认是否网关服务自身问题导致慢,还是网关下游服务问题导致的慢。
快速判断:
有下述现象时,可初步任务网关服务异常。
1. 直连上游服务快,经过网关慢
2. 网关总耗时高,但上游服务处理时间正常
3. 网关实例 CPU、线程、事件循环、连接池、GC 有明显异常
4. 网关中某些自定义逻辑耗时很高
5. 网关调用上游前后都不慢,但网关整体响应仍慢1、针对慢的接口,直接在对应服务pod中执行验证,可采用curl 等方式请求验证,确认在不经过网关服务时请求处理耗时是否正常。如果正常,则有较大概率网关服务问题,否则直接分析应用服务。
2、查看网关服务监控或登录网关服务所在容器,查看cpu使用情况,内存使用情况,GC使用情况、网络等,如相关指标都正常,则可初步考虑非网关服务问题。
2.1 如果直接登录网关容器分析,执行命令:top
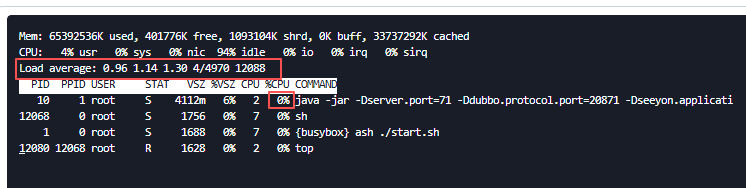
- 如果cpu使用率正常,低于70%,并且load正常,则认为网关服务cpu正常。
规则: 一般 load < (0.7 × CPU核心数) 则可认为正常。
2.2 登录网关服务容器查看服务内存使用,执行命令:free /top命令, 查看内存使用率,如果内存使用率低于80%,可认为网关服务正常。
2.3 登录网关服务容器查看服务GC使用,关注fullGC次数
-- 1. GC统计摘要(最常用)
-- 输出格式:S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
-- 每1秒采集一次,共采集10次
jstat -gcutil <pid> 1000 10 确认是否存在较多fullGC (FGC) ,如果没有,或次数很少,可认为网关服务正常
2.4 如异常问题不涉及文件上传下载,可暂时不用分析网络。
3、查看网关服务监控,确认是否存在异常指标,重点关注:内存、GC
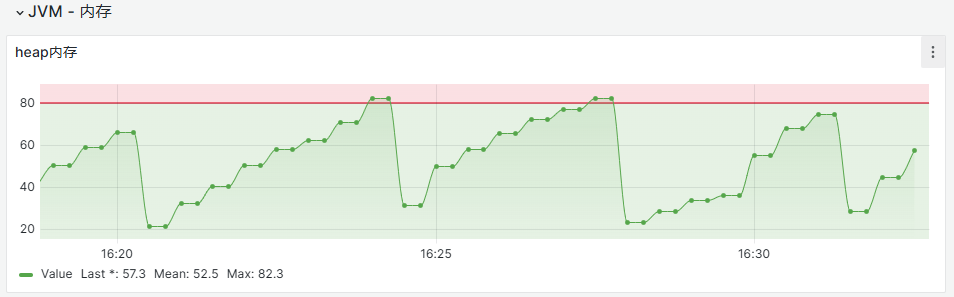
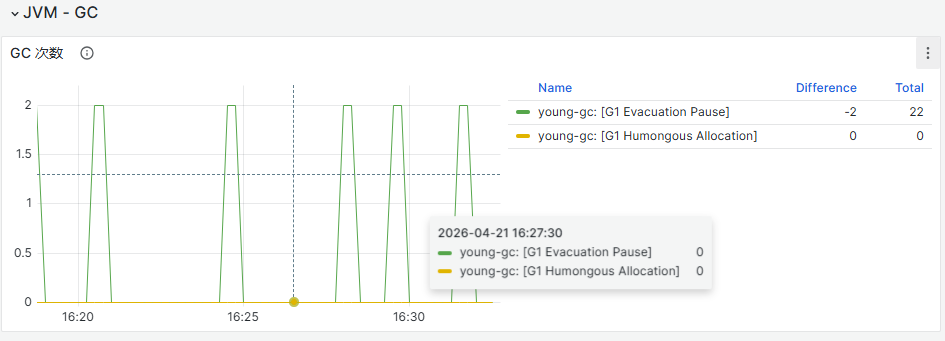
查看是否存在内存使用率过高超过红色阈值或fullgc频次过高问题,若无,则可初步排除网关问题。
结论:
考虑网关问题:可参考相关 常见应急恢复策略。
否则:继续后续分析...
9.判断:后端服务问题(高概率,重点分析)
基于以往场景,服务慢的问题,绝大多数场景都由以下相关原因导致,可重点分析。
常见相关后端异常问题:
├── 服务状态检测:服务异常重启假死
├── 应用关键指标异常检测
│ ├── 高cpu负载
│ ├── 高内存使用率(高频)
│ ├── 高频率GC
│ ├── 线程池高负载,线程排队
│ └── NO → 继续排查
├── 应用常见异常检测
├── 元空间异常问题
├── 慢sql(高频)
├── 慢redis
├── dubbo处理慢(高频)
├── 消息积压,处理慢
├── 常见其他可能问题
└── NO → 联系研发,继续排查快速分析排查锁定异常服务范围:
1、确认异常应用范围,如果异常服务几种在某类业务,比如公文、流程等,可重点查看对应公文服务(`edoc335172694483814428`),工作流服务(`bpm`)
2、确认服务状态,是否宕机,是否重启
3、如果异常业务无明细特征,可以通过告警和服务监控确定异常服务范围。服务整体变慢,大多出现在公共基础服务,如:`ctp-user`、`organization`、`app-common`等,可优先检测此类服务
4、如果大量业务变慢,也可重点分析是否为中间件数据库服务、`redis`服务异常,这些为高频使用中间件,异常会导致大量应用故障。
5、如果上面几步都未发现明细异常,可考虑近期是否有发版,导致问题1、先通过前端异常页面,F12打开调试窗口,找到对应慢接口或异常。查看异常是否集中在某个服务或几个服务。如果异常相对集中,则重点分析后端异常服务
2、如果通过前端页面无法快速确认异常的后端服务,可通过查看告警和监控,可结合告警信息一起分析。
如有监控:可关注下图中红色部分指标,如果出现异常标红的应用,可重点分析。
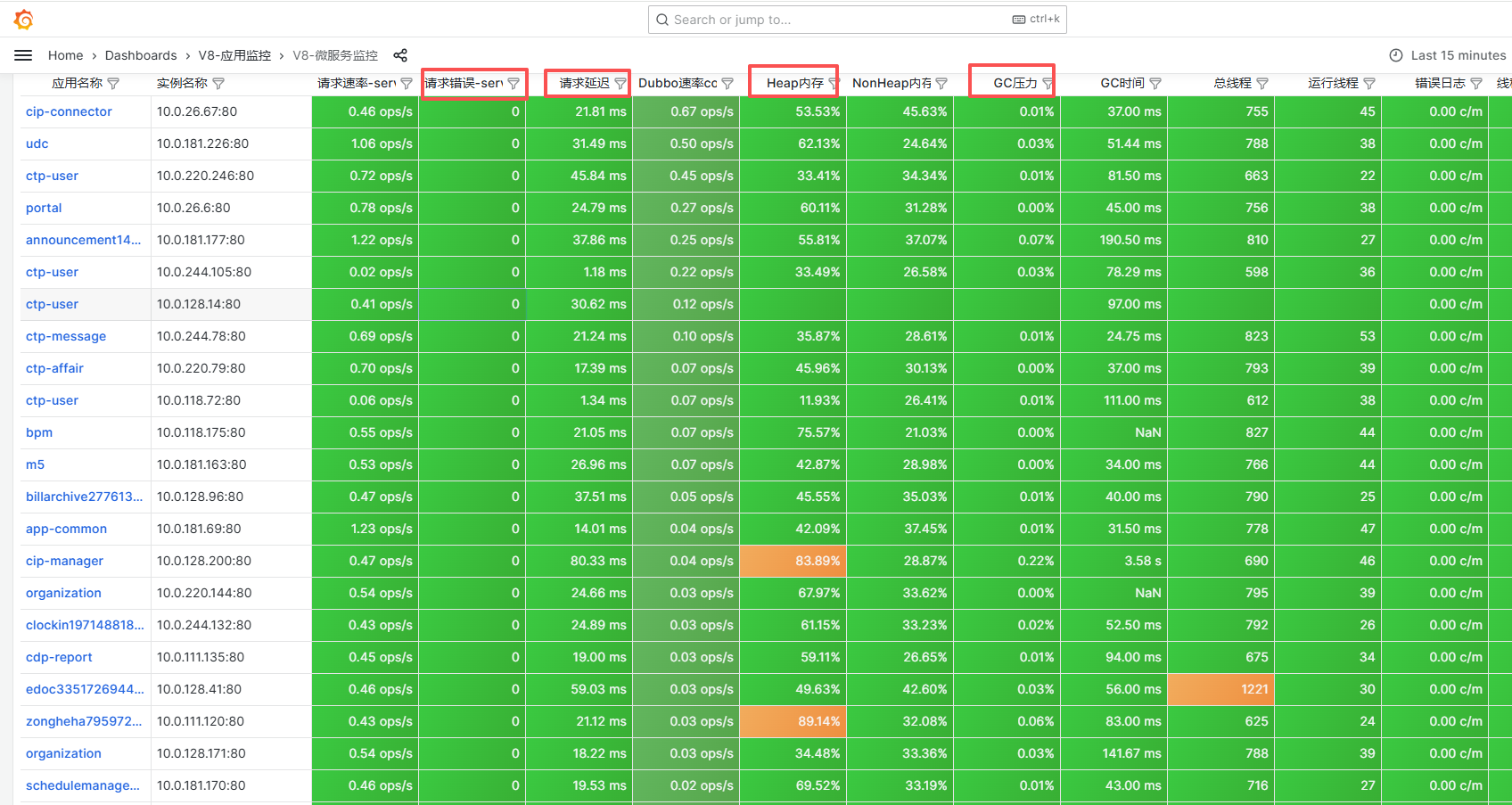
3、如果上面两步都无法确认可能异常的服务,则建议直接查看核心重点服务的日志,关注服务中的错误信息、超时信息部分。重点服务:
ctp-user
organization
bpm
ctp-affair
app-approval
edoc335172694483814428(如有公文相关异常可查看该服务)
app-common 等4、也可用 一键采集工具,进行采集扫描,初步定位可能的异常服务:
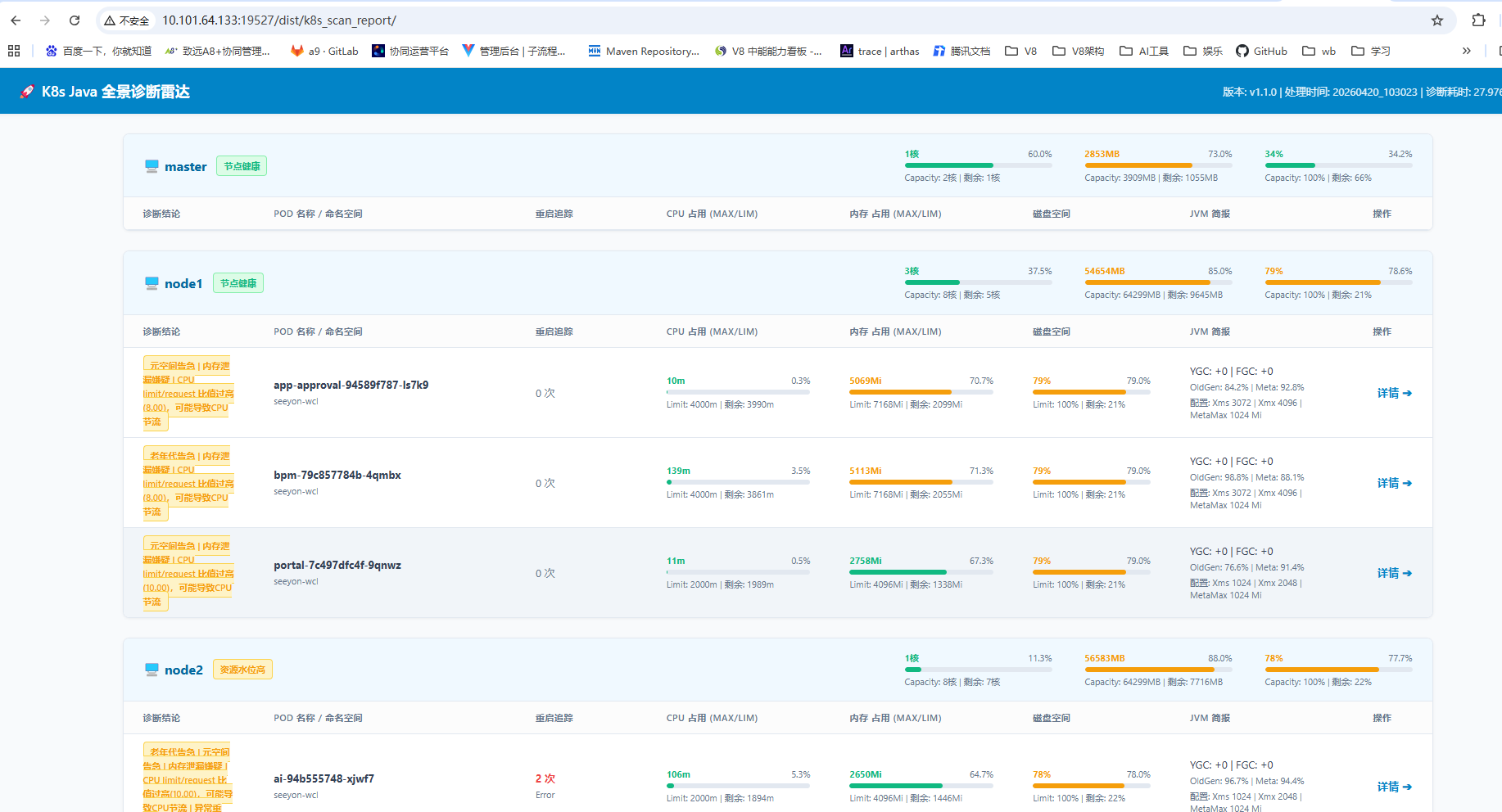
基于上述快速诊断分析,确认异常范围,和明确相关可疑问题点,可优先进行相关可疑点问题进行分析。
9.1 检测服务状态(服务宕机、重启)
1、如果确认可能异常的服务,可直接查看服务状态。
2、如果未确定服务范围,可直接在k8s服务面板,查看是否有服务宕机,重启等
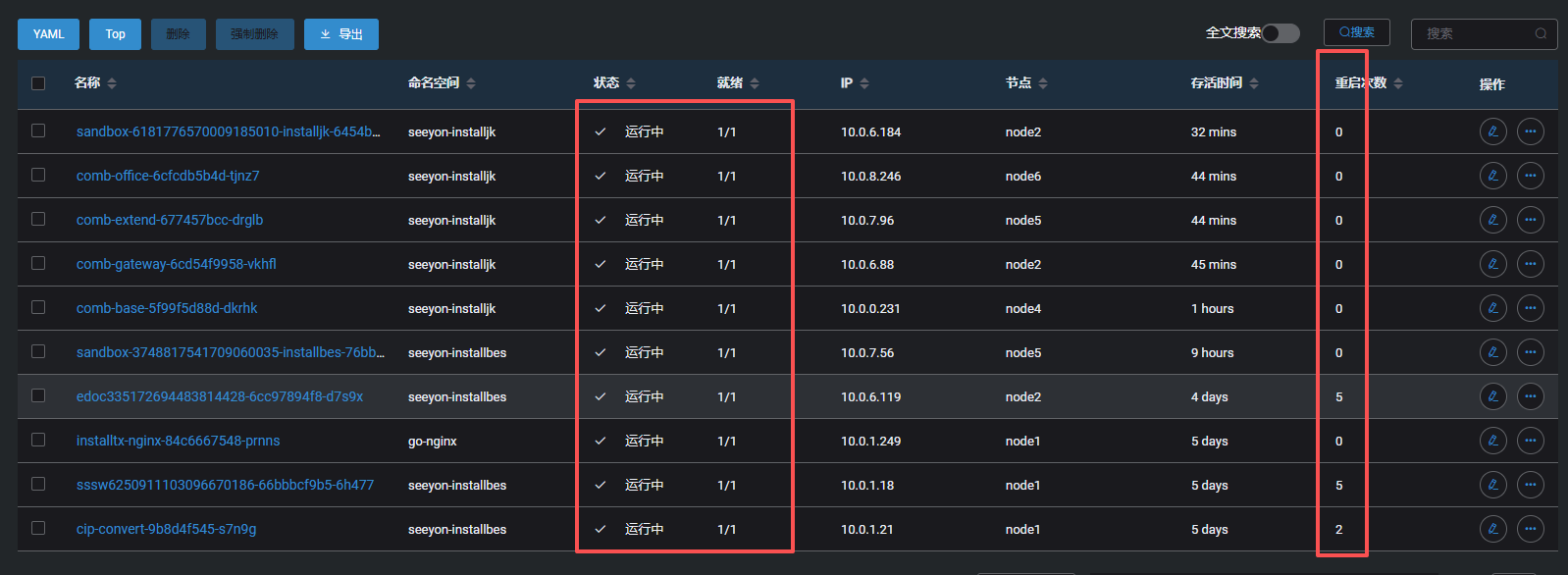
说明:不同k8s管理界面不同,可能展示不同,但查看管理界面,关注服务状态、重启情况
如果存在服务宕机:
1、请查看k8s的宕机事件,确认是否由于资源不足,服务被驱逐。
常见的资源不足,被驱逐的情况主要有:
1、服务器磁盘资源不足
2、服务器cpu资源不足,负载过高
3、服务内存不足,无法申请到足够内存给pod.如果确认是资源不足驱逐,可优先转入相关应急修复策略执行恢复。
2、查看服务监控(参考 系统监控查看说明),确认服务本身是否存在异常,导致宕机。常见容易导致宕机的异常指标多出现在内存占有率高、高频fullGC、元空间使用率高(非堆使用率)等。
2.1 如果根据宕机前监控信息,发现服务可能是由于内存不足造成的宕机。
2.2 如果监控异常表现为内存溢出问题,则可查看对应异常时段的应用日志是否有OOM等信息。如果有,则明确为OOM异常,可优先考虑执行恢复策略,同步再进行根因分析。
2.3 如果服务暂时还为宕机,但是监控中内存飙高,fullGC明显增加,表有较高宕机风险。可 先执行扩容资源重启的恢复策略,然在进行根因分析。
2.4 检测服务的yaml,基于应用推荐配置,并结合客户用户量和数据量进行评估,如果配置不合理,按照这恢复策略,进行调整。3、如果服务已宕机,可根据服务宕机前监控,初步分析导致宕机的原因
常见原因:
1、内存占用过大,OOM
2、cpu使用率过高,夯死服务
3、线程排队夯死服务
4、元空间不足,metaspaceOOM可结合日志和dump信息,进一步确认相关原因。恢复策略可参考后续应急措施处理(12.应用恢复措施)。 元空间内存溢出、 jvm分析工具、 K8S的oomkiller
如没有宕机:
未发现宕机等相关问题,则需进一步结合服务日志等手段策略分析
9.2 应用关键指标异常检测
如果服务状态正常,但是业务响应慢,可分析下面服务关键指标异常。实际场景中当异常出现时,
往往会伴随多个指标信息的异常,可结合关联分析。
常见的监控查看可参考章节: 系统监控查看说明
9.2.1 服务cpu负载高
快速确认现象:
1、可通过监控中服务cpu监控图,查看服务cpu负载是否飙高
2、也可直接登录服务所在pod, 通过`top` 命令等查看cpu负载是否高如果通过监控指标等确认存在高cpu使用,可进一步结合日志进行分析。
一般高cpu 负载往往会由于以下场景问题导致(可重点分析下面场景):
1. 高cpu消耗逻辑,如加解密、序列化、排序、复杂计算等
2. 高线程消息甚至线程排队,任务需频发切换cpu进行调度
3. 不合理业务逻辑,大循环等详细分析:
- 确认服务cpu负载过高等问题,可优先通过应用的监控图表观测。一般当使用率高于80%时,往往表明服务存在高cpu负载,有风险。当系统负载图中,使用率接近或超过100%时,也表示有高风险。
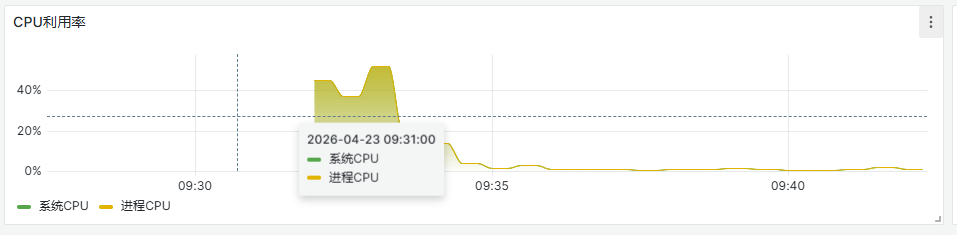
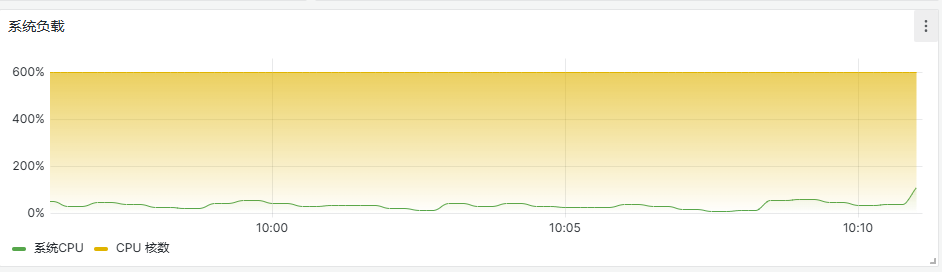
- 进一步确认,可登录服务所在容器,通过执行命令: top , 查看对应应用进程所使用的cpu信息,同时查看容器cpu的
load负载信息
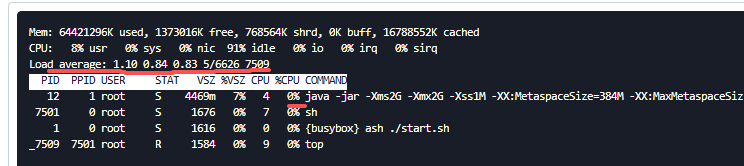
- 确认存在cpu高负载问题,可优先通过对应时间段的日志进行根因分析,排查是什么业务导致。(一般关注涉及到
加解密、压缩、解压、大数据循环等功能逻辑点) - 如果日志中信息不足,或无法定位,还可结合火焰图进行根因分析:
-- 火焰图生成工具:
-- 1. 安装async-profiler(如未安装,可先执行安装流程)
wget https://github.com/async-profiler/async-profiler/releases/download/v4.3/async-profiler-4.3-linux-x64.tar.gz
tar -xzf async-profiler-4.3-linux-x64.tar.gz
cd async-profiler-4.3-linux-x64
-- 2. CPU火焰图
./profiler.sh -d 30 -f cpu_flame.html <pid>
-- -d: 持续时间(秒)
-- -f: 输出文件
-- --title: 图表标题- 也可连接服务容器,执行
arthas命令进行分析。
确认问题应急处理:
确认cpu高,优先进行根因分析,如需快速恢复,可转入 常见应急恢复策略。
否则,继续执行其他分析。
9.2.2 服务内存使用率高/高频fullGC(目前高频出现)
内存使用率高,往往会同时伴有高频fullGC。
快速确认现象:
1、可通过监控中服务内存监控图、gc监控图,查看服务内存负载和gc是否存在飙高情况
2、也可直接登录服务所在pod, 通过`top`命令等查看内存负载是否高
3、也可通过`jstat -gcutil` 命令,查看jvm的GC情况,是否出现较大`fullGC`
4、也可使用`arthas`工具连接服务进行相关信息查看如果通过监控指标等确认存在高内存使用和 高fullGC,可进一步结合日志进行分析。
一般高内存负载和高频fullGC往往会由于以下场景问题导致(可重点分析下面场景):
1. 业务高峰访问,导致服务内存使用暴涨,拖慢服务
2. 业务触发大对象,导致内存使用增高
3. 可能存在内存泄漏,部分内存无法释放,造成服务内存增长,使用率超过阈值
4. 堆外元空间增量,超过阈值。(出现元空间不足,大概率为表单应该相关问题,如无法卸载等、加载慢等)详细分析:
- 通过监控确认现象,
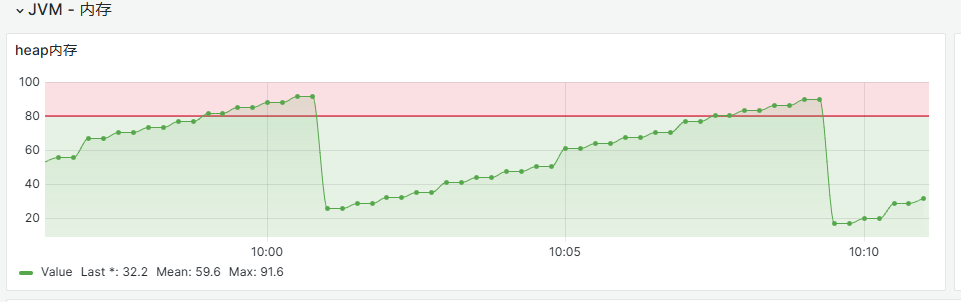
对于内存监控图,如果内存使用率高于80%,且有持续增长趋势(如近3-5分钟都>80%),或者居高不降,表明有高内存风险
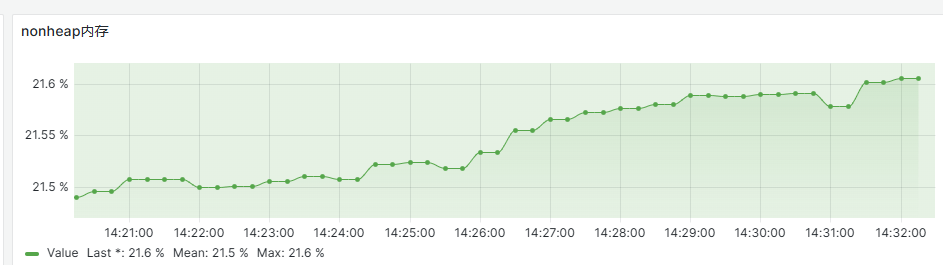
非堆内存使用,主要是元空间和堆外内存使用情况;如果存在使用率过高的情况,大概率是表单应用或使用堆外内存相关的组件异常,重点关注表单应用相关功能。
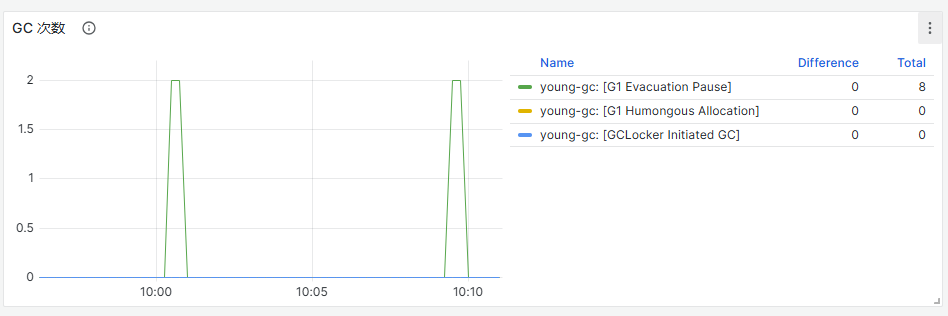
查看GC图,如果图中近30分钟,fullGC次数>=2次,表明近期内存不足触发了gc频率较高,关注高内存使用风险
- 通过登录服务容器节点,执行命令:
top, 确认问题。
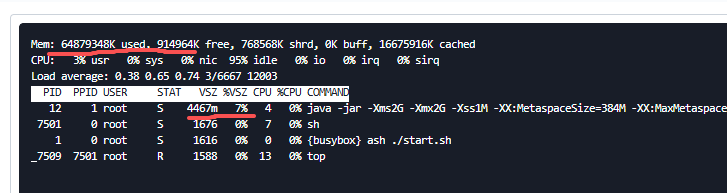
如果发现如图中%VSZ使用率为80%以上,并且持续居高不下,或在增长等,表明有高内存使用风险
- 可登录服务容器节点,执行下面命令,确认GC情况:
-- 第一步,查找java应用的进程id
jps
-- 1. GC统计摘要(最常用)
-- 输出格式:S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
jstat -gcutil <pid> 1000 10
-- 说明:每1秒采集一次,共采集10次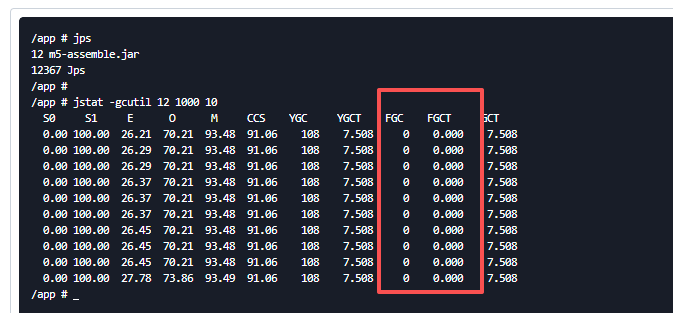
如上图,重点关注FGC 和 FGCT,FGC表示fullgc的次数,FGCT表示fullgc的耗时(单位:s)。如果 fullgc 次数多或fullGC耗时长,都表明服务内存使用异常,有相关风险。
fullgc 次数计算,可按照服务启动时间计算,如过服务日均fullGC超过1次,可初步认定有相关风险。
- 确认问题后,查看客户场景是否可能为高峰业务请求导致异常。根据高频业务请求,关联日志进行分析确认根因。
- 确认问题后,结合日志进行具体问题点定位,根因分析。分析时重点关注上面提到的可能导致高内存使用的高危场景。
- 如果通过日志无法定位,还可通过执行jmap -dump命令,获取应用堆栈,分析问题点。
-- 生成堆转储(谨慎使用,会阻塞应用,生成文件较大)
jmap -dump:live,format=b,file=heap_dump_$(date +%s).hprof <pid>确认问题应急处理:
确认内存高,优先进行根因分析,如需快速恢复,可转入 常见应急恢复策略。
否则,继续执行其他分析。
9.2.3 线程池高负载、排队
此场景,主要分析以下几类线程池:
1、tomcat线程池。考虑是否由于tomcat线程池满,请求排队,造成业务慢
2、jvm中的线程池。考虑是否由于程序线程池使用率过高,造成任务排,拖累业务处理慢。
3、考虑服务自定义线程池使用负载高,造成业务处理慢快速确认现象:
1、可通过监控中服务tomcat线程监控图、线程池监控图等查看是否存在高负载
2、也可直接登录服务所在pod, 通过`jstack`命令,获取程序线程堆栈信息,查看分析
3、也可通过平台提供的命令进行分析:`{host}/service/{appName}/monitor/thread-info`
4、也可通过`arthas`工具,连接服务进程,查看如果通过监控指标等确认存在线程池相关高负载,可进一步结合日志进行分析。
一般线程池相关高负载往往会由于以下场景问题导致(可重点分析下面场景):
1. 业务高峰访问,导致服务线程使用暴涨,拖慢服务
2. 业务触发慢sql、慢redis等处理慢的场景,造成线程持有时间长,触发任务堆积排队等
3. 可能存在死锁等,造成线程无法锁等待无法释放,触发高负载排队详细分析:
- 通过监控确认现象,

对于线程监控图,关注当前ActiveCount线程的数量和总线程数的占比,同时关注线程池排队图中QueueSize情况,如果ActiveCount数量高或QueueSize>0,表明有线程池负载高或存在排队情况,服务有相关高风险。
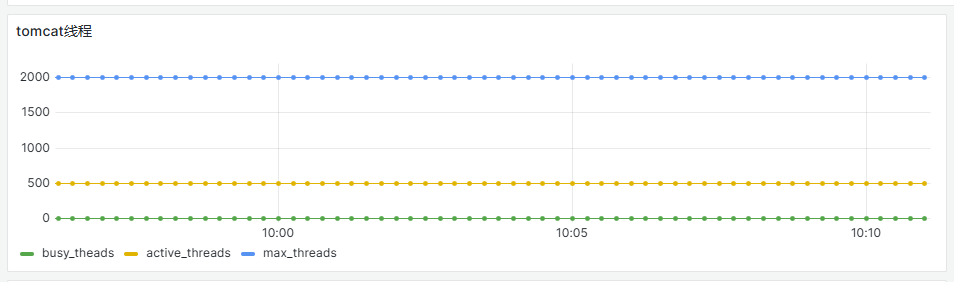
查看tomcat线程的监控图,如果busy_threads线程数接近或等active_threads时,表明系统接收到的http请求多,负载高,可能已排队,有高风险。
- 通过登录服务容器节点,执行命令:
jstack,获取程序线程堆栈,进一步分析确认。
线程堆栈(包含锁信息)
jstack -l <pid> > thread_dump_locks_$(date +%s).txt
也可以通过平台接口获取:
如:https://dev.seeyonv8.com/service/ctp-user/monitor/thread-info获取到线程堆栈后分析线程使用情况,重点查看:
1. 是否某类线程数占比很高,如果存在关注对应线程的执行任务并结合日志分析
2. 关注是否有线程锁等待的情况,如果存在线程死锁等,需结合线程堆栈等一起分析解决
3. 查看是否有线程wait较长时间等,如果有,可根据线程堆栈查看是等待的代码逻辑,如常见慢sql等待- 可登录服务容器节点,执行
arthas命令, 进一步确认。
确认问题应急处理:
确认内存高,优先进行根因分析,如需快速恢复,可转入应急修复措施。 1
否则,继续执行分析:
1、基于上面的监控指标的分析,可初步推测可疑的问题点,结合下面的分析路劲定位服务异常点
2、根据重点场景分析,结合 系统日志查看指引,关注info、record 日志,进行快速诊断定位。
通过获取相关应用的record.log, 过滤相关异常时间段日志,进行快速诊断:
1、对日志中的慢日志,按照type分类汇总分析
2、优先排查按type类型汇总后高频出现的,且耗时相对较高的,进行重点分析
如客户版本无record.log日志,则需要基于下面场景,逐个场景分析判断。9.3 堆内存使用率高
如通过监控,发现服务堆内存使用率过高,可能存在内存泄漏或大对象占用的问题,导致业务处理慢等。可结合下面进行进一步分析:
- 采集服务的线程信息(
threadDump),分析是否存在某个耗时业务点,夯住了服务 - 如果存在
record.log,查看异常时段服务的性能日志信息,确认服务的性能瓶颈点,确定问题。 - 如果存在异常时段的
内存dump,可疑查看通过MAT分析工具,分析服务内存中的大对象占用,确认问题点。 - 可考虑采集内存火焰图,分析内存异常点
- 结合应用的
info.log,分析异常时段可疑的触发业务或日志中的报错等相关信息进行分析。
对于堆内存使用率高的问题,应急恢复策略可参考: 常见应急恢复策略。
9.4 元空间(非堆)使用率高
如出现元空间(非堆)空间不足和使用率高问题,常见为表单应用导致的异常。
1、如果应用逻辑中涉及到表单应用相关的,基本可确认为相关表单应用问题。
表单应用相关主要有:
1. 所有UDC搭建的应用
2. app-approval
3. edoc335172694483814428业务表现为处理慢,且异常指标为元空间使用率高,可结合日志重点分析
常见表单应用加载慢:结合慢的业务分析,考虑对应业务触发表单加载慢,造成问题。结合相关日志和表单应该id等信息确认定位。
更多策略:参考 应用表单加载导致超时
应急策略: 常见应急恢复策略。
9.5 慢sql (高频)
1、如果通过record.log已定位为慢sql问题,可根据异常sql对应的traceId等,回查info日志,确认慢sql对应的业务逻辑点,分析并修复。
2、检测服务druid监控页面,查看是否存在慢sql和连接池不足等情况(如果非druid连接池忽略)
{host}/service/{appName}/druid/sql.html
如:
https://dev.seeyonv8.com/service/bpm/druid/sql.html重点关注:
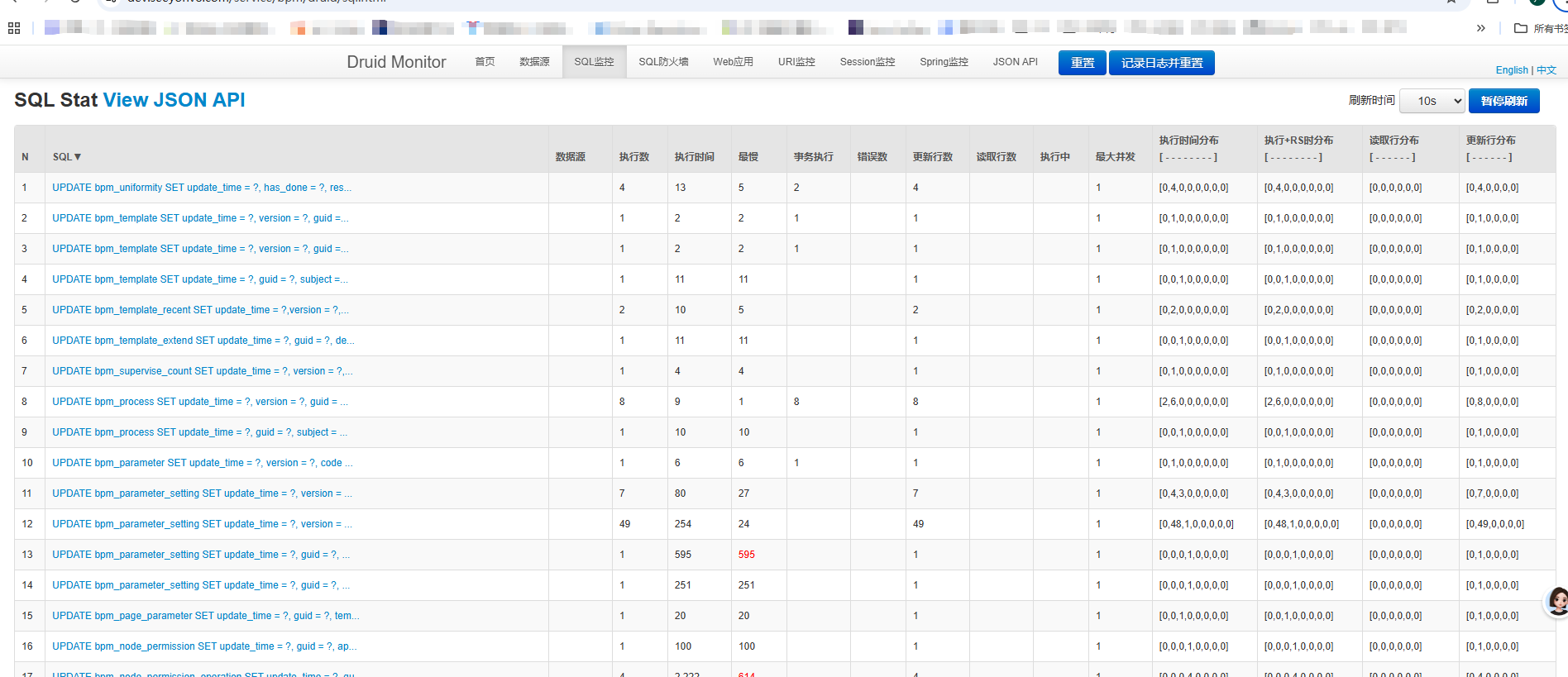
如果无法确认是否为最近场景导致的慢sql,可以考虑在页面上重置操作,间隔一会再来查看,确认刚才的猜想。
3、同时关注下面监控图表:
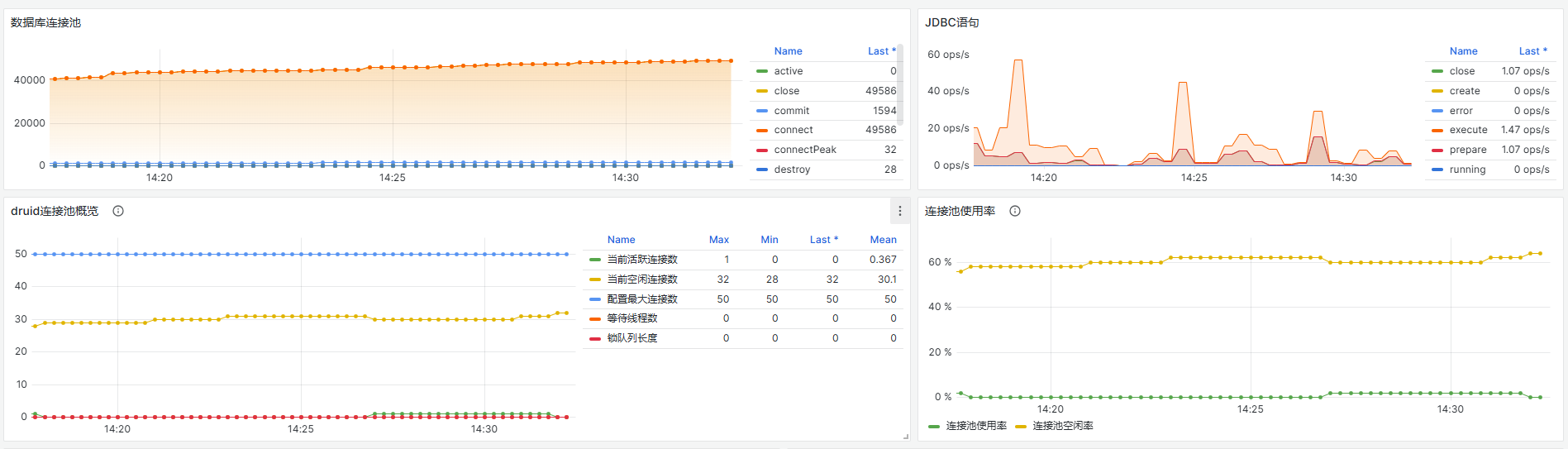
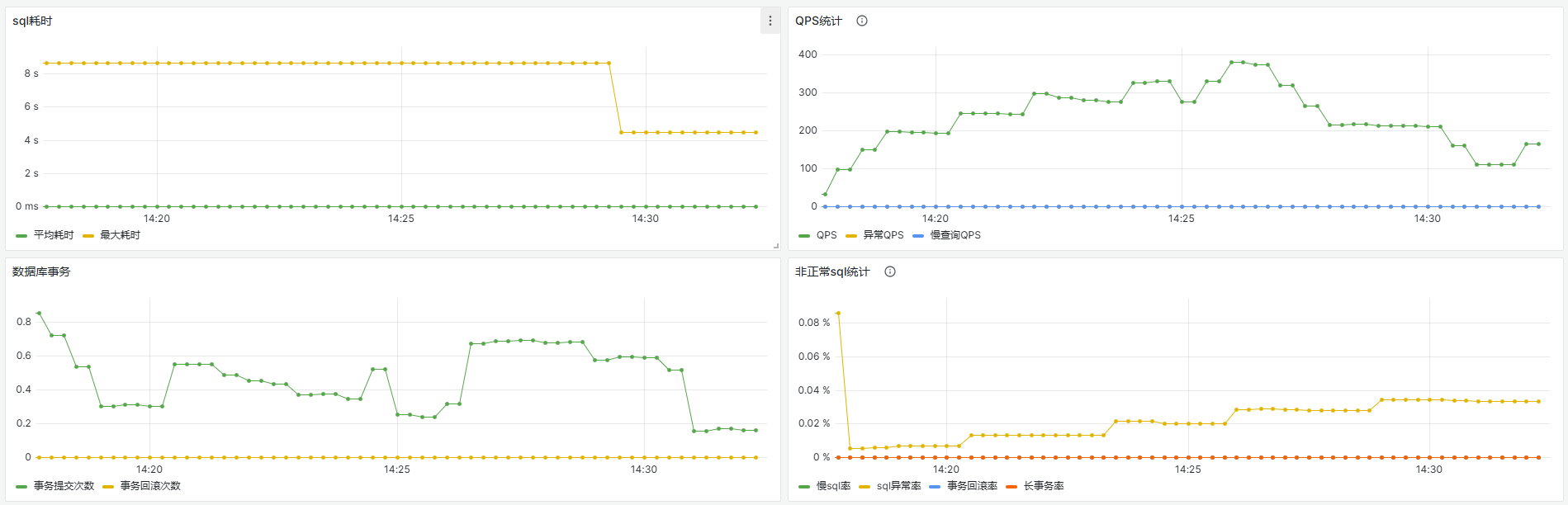
观测是否存在连接池增量,连接不足的情况;是否存在sql耗时增加,sql异常等信息。
4、如果出现连接不够用等,一般可在info日志中查询到 获取连接超时、无法获得到连接等异常。
5、也可结合服务的线程堆栈日志,查看是否有线程阻塞,并且对应堆栈显示为sql等待。如果是,则分析对应业务和sql业务点进行修复。
6、连接数据库服务,抽取慢SQL,对比高峰和低峰执行情况
7、检测数据库服务是否正常,测试连接,测试简易sql执行耗时,检测数据库服务器主机监控,查看负载等。
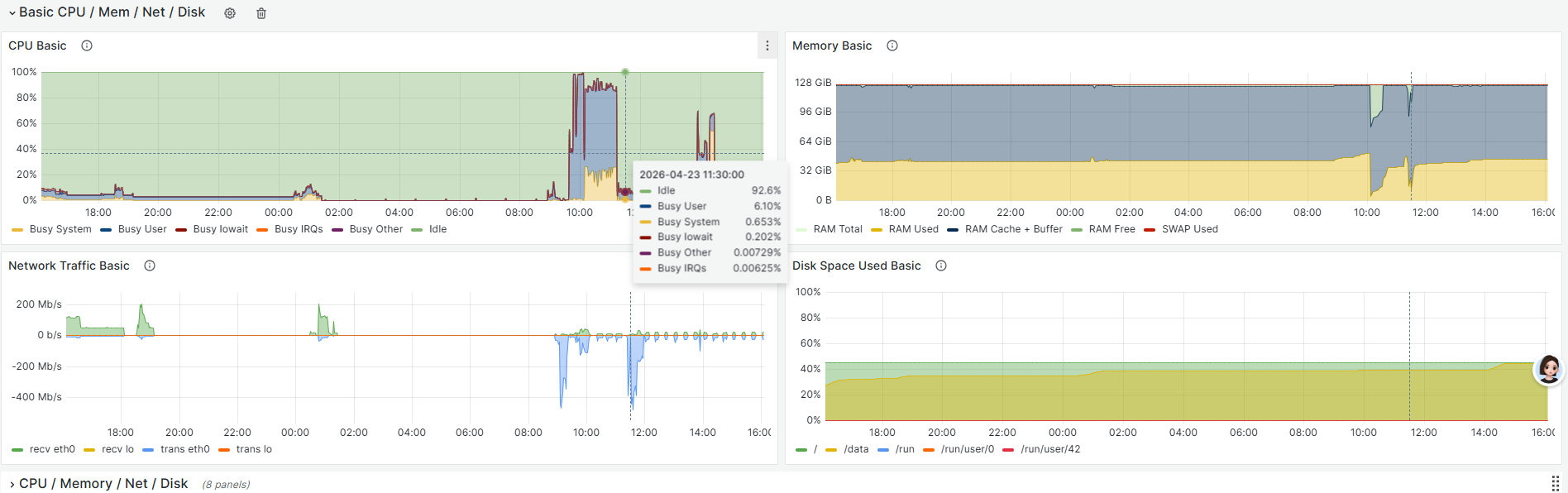
关注:
1. cpu负载,一般阈值80%,超过则认为风险
2. 内存负载,一般阈值80%,超过则认为风险
3. 网络,根据客户场景的网络带宽评估,但往往高网络占用也会表现为业务查询慢
4. 磁盘,如果出现磁盘慢等情况,会出现数据读写异常或卡死等定位后处理:
9.6 慢redis操作
1、如果通过record.log已定位为慢redis问题,可根据对应的traceId等,回查info日志,确认慢操作业务逻辑点,分析并修复。
2、如果需要进一步定位是否为redis操作慢,可连接redis服务器,查看redis服务状态,同时检测redis服务器资源使用情况(如通过top命令 或 监控查看)。
关注:
1. cpu负载,一般阈值80%,超过则认为风险
2. 内存负载,一般阈值80%,超过则认为风险
3. 网络,根据客户场景的网络带宽评估,但往往高网络占用也会表现为业务查询慢
4. 磁盘,如果出现磁盘慢等情况,会出现数据读写异常或卡死等3、可连接redis,获取对应的slow_log,查看是否有存在可疑的慢操作key。查看Redis slow log,重点找keys 、EVAL等命令,关注大key、热点key。
4、结合日志,关注日志中慢日志和错误日志信息,查看是否有业务异常时间点附件的相关redis操作异常。
定位后处理:
9.7 dubbo处理慢 (高频)
1、如果通过record.log已定位为dubbo处理慢问题,可根据对应的traceId等,回查info日志,确认慢操作业务逻辑点,分析并修复。
2、如果需要进一步定位是否为dubbo操作慢。
通过下面监控,初步定位是否dubbo接口存在慢的问题。
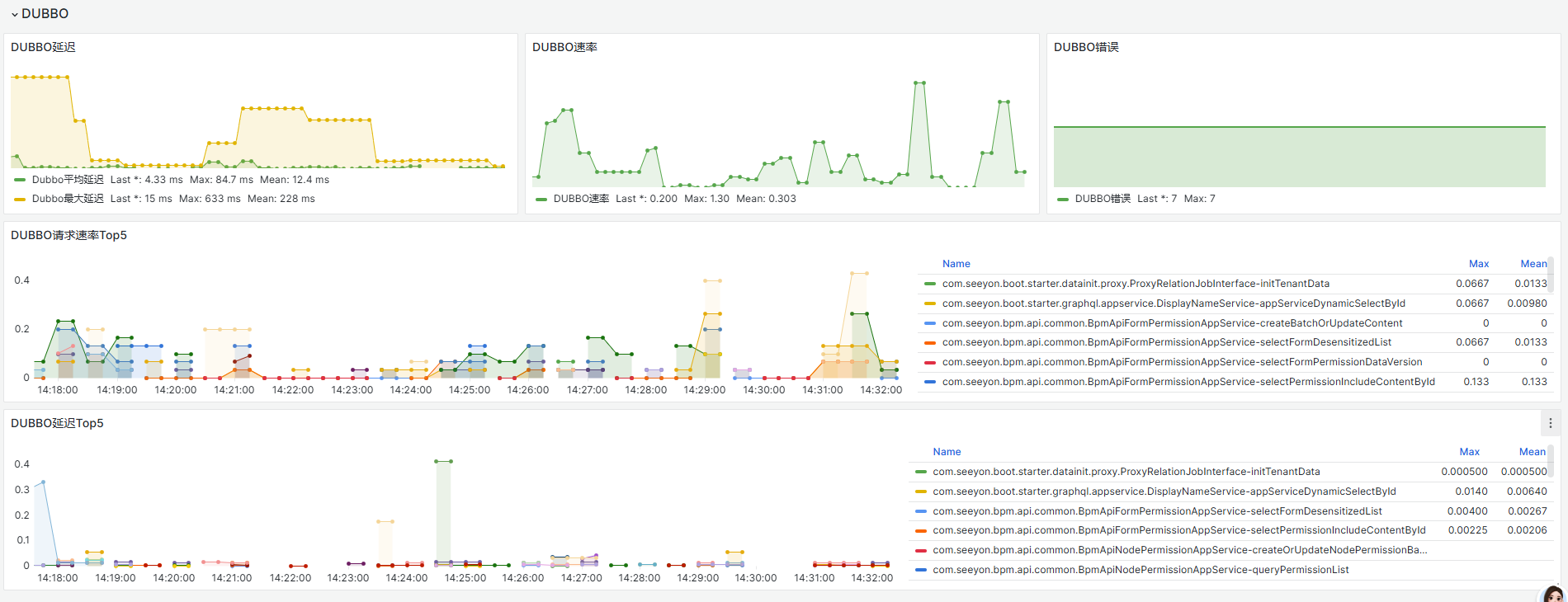
一般会出现延迟增加,同时可能dubbo错误也会增加,dubbo延迟TOP5 峰值会比较高,可能达到几秒等。
3、查看服务info日志,如果存在dubbo慢,往往会有dubbo请求超时等相关日志,关注 关键词: timeout 相关日志,确认具体的慢dubbo请求。
4、如果服务自身作为dubbo服务方处理慢,往往由于慢sql、慢redis或相关业务逻辑处理异常导致。可根据上游服务提供的调用慢接口作为入口进行分析,查询关联日志和traceId进行分析。
5、考虑可能为业务激增导致的dubbo处理慢,确认是否存在业务量激增,结合服务的thead-dump信息,查看是否dubbo相关线程数量较多,且有存在处理慢的dubbo线程。
定位后处理:
- 如果确认为服务dubbo慢问题,可联系对应开发进行处理,运维的应急策略可参考 常见应急恢复策略
- 未定位,可继续其他分析
9.8 消息处理慢(低概率)
1、消息处理往往为异步模式,一般不会造成业务变慢问题。但如果还是考虑肯影响点,可重点分析同步消息处理,尤其是同步eventBus消息。
2、需要进一步定位是否为消息操作慢,可结合日志进行分析,消息处理慢往往是由于慢sql,慢dubbo、慢redis等操作导致,所以可以优先定位其他相关异常。
3、关注日志中的慢信息(timeout)。
4、连接MQ查看,查看是否存在消息积压。消息积压可能导致相关业务处理阻塞等待、变慢等。
定位后处理:
- 如果确认为消息慢导致异常,可联系对应开发进行处理,运维的应急策略可参考 常见应急恢复策略
- 未定位, 可继续其他分析
9.9 常见其他可能的问题
1、优先考虑是否由于近期发版等变更导致。
1、近期是否存在发版或更新补丁等操作,更新前后业务性能出现较大变化,可重点考虑更新的功能点导致的问题
2、近期是否有调整服务参数(nacos配置参数、部署yaml参数、ddl、业务参数等),调整前后性能是否有较大变化2、其他可能导致慢的一些场景
1、大表查询等数据库操作场景
2、大对象导致内存不足,触发异常
2、异常逻辑触发大循环,触发异常更多信息,可联系对应研发进行分析。