1.适用范围
适用于以下场景:
- 多个/大量页面访问突然报错,核心操作无法继续
- 后端接口请求大面积失败,接口可能报错或超时
- 系统在某一时间点后大量业务报错
- 系统突然大面积无法登录,门户加载异常等
- 大量页面接口报错,报错-Nginx 502/503/504或10001异常等
不适用于以下场景:
- 单个接口报错,其他功能正常
- 单个用户登录异常
- 单点业务功能异常
2. 问题现象和排查目标
系统整体变慢时,优先要判断问题属于哪一层:
- 前端页面报错
- nginx/网关异常导致接口报错
- 后端接口报错 #7.判断:后端服务问题(高概率,重点分析)--重点分析
- 中间件异常--重点分析
- 基础设施或部署资源问题--重点分析
3. 快速排查流程
可优先重点排查高概率方向
系统整体变慢
├── 前端页面报错(低概率)
│ ├── YES → 转入前端页面问题SOP
│ └── NO → 继续排查
├── nginx服务/网关服务异常(低概率)
│ ├── YES → NG/网关异常分析sop
│ └── NO → 继续排查
└── 后端服务异常(高概率)
├── 接口执行超时、报错等
├── 慢SQL,导致接口超时报错
├── 慢Redis操作,导致接口超时报错
├── 消息消费慢,导致接口超时报错
├── dubbo请求慢,导致接口超时报错
├── 中间件异常,导致接口超时报错
└── 其他:发版变化导致变慢 4. 快速判断
4.1 快速判断法
1. 确认是否为全局现象,还是局部业务现象。(确定范围)
|---如果全局问题,优先看网络和NG/网关服务
|---如果局部问题且异常接口是否集中在某个服务,重点分析该服务
2. 查看近期是否有发版、配置变更、节点波动、Pod 重启。(怀疑和发布有关)
|---如果有相关变动后出现异常,优先考虑和变动有关联。
3. 查看核心监控是否存在 CPU、内存、磁盘 IO、网络带宽、错误率突增。(怀疑后端服务异常)
|--- 是否收到相关告警信息,如有相关告警,请优先分析告警相关异常服务组件。
4. 分析异常服务日志,重点分析错误日志和超时相关日志(怀疑后端服务异常)
|--- 如果日志出现访问中间件异常报错或超时,检测中间件服务状态。
5. 如果有相关表象与中间件有关(如数据库、redis、MQ等),检测各中间件状态是否正常(怀疑中间件)
|--- 可通过监控或连接各中间件确认服务状态
|--- 检测中间件主机否正常(cpu、内存、磁盘等)
|--- 检测服务到中间件直接的连接是否正常
6. 根据应用日志保存,检测对应中间件服务是否异常。(怀疑中间件)4.2 快速判断决策表
典型场景快速决策:
| 现场特征 | 关键观察点 | 初步判断 | 下一步 |
|---|---|---|---|
| 页面/接口报错 | 1.客户点击页面按钮或提交操作后直接报错; 2.页面接口可能报错或超时; 3.部分业务数据查不到、保存失败,核心操作无法继续。 | 后端服务或接口问题 | 分析对应后端服务 #7.判断:后端服务问题(高概率,重点分析) |
| 页面/接口报错-Nginx 502/503/504或10001异常 | 1.客户打开页面或发起请求时直接失败; 2.浏览器可能提示请求异常; 3.Nginx侧出现502/503/504,前端偶发提示10001,且常表现为异常时间段集中出现 | nginx配置或后端服务异常 | 检测nginx配置 网关服务问题(低概率) 检测后端服务 #7.判断:后端服务问题(高概率,重点分析) |
| 仅某几个接口异常 | 1.页面F12查看到报错是由于几个接口异常导致(超时或报错) | 特定后端服务问题 | 检测对应后端服务 #7.判断:后端服务问题(高概率,重点分析) |
| 特殊登录问题 | 1、重点查看ctp-user服务; 2、如果客户登录涉及三方集成,需要同步关注三方集成点 | 1.ctp-user服务; 2.三方集成服务 | 1.ctp-user服务; 2.三方集成服务 |
5. 判断:是否前端页面慢(低概率)
快速判断:
- F12查看页面报错时,是否存在后端接口报错、超时等异常,如果存在优先查看后端服务。
- F12查看页面报错时,所有后端接口都正常,则直接查看前端问题。
具体操作:
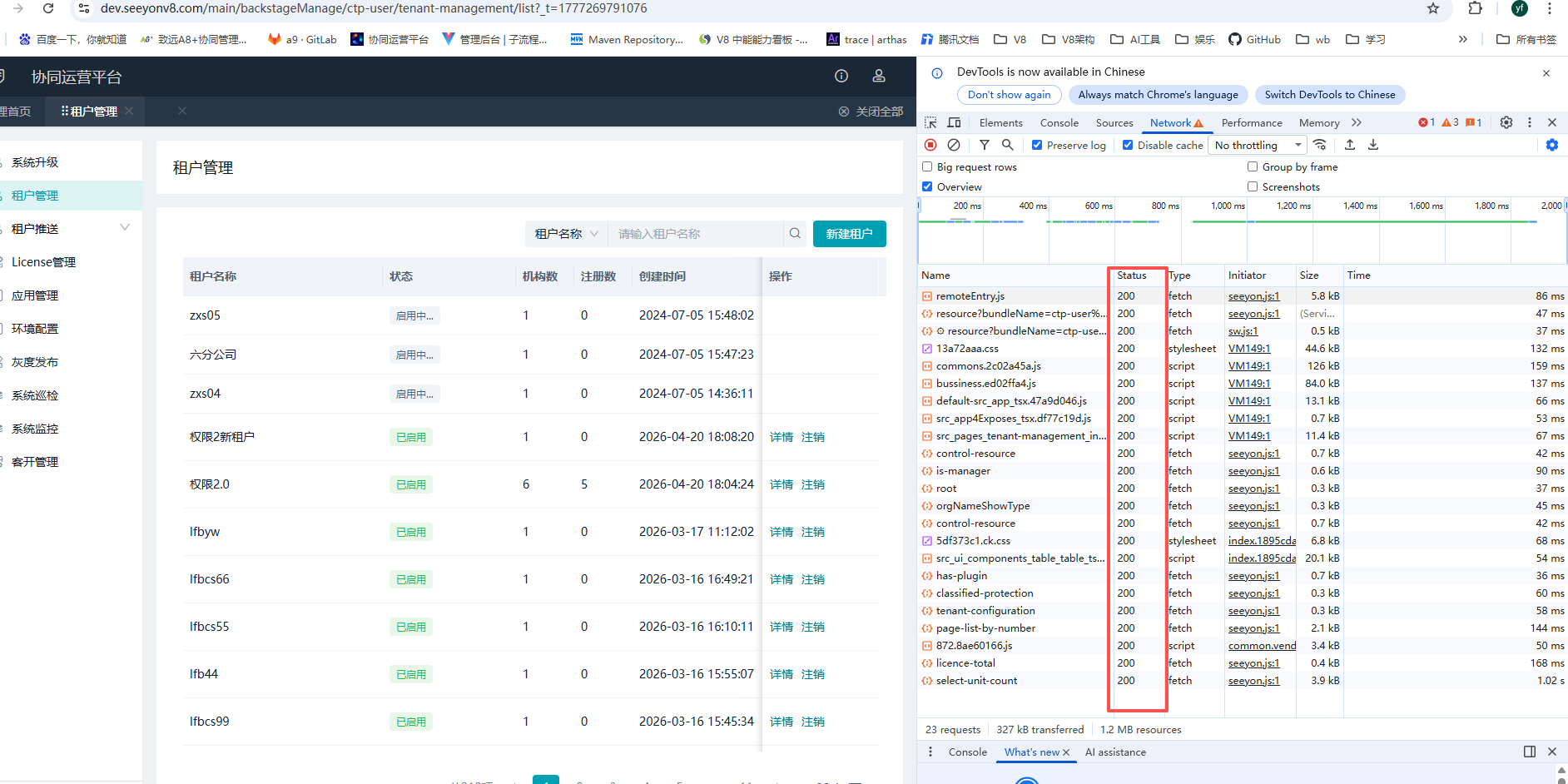
- 如上图,浏览器F12打开调试界面,关注请求status,如果都为200,则无接口问题,直接分析前端问题。(这种前端功能报错,往往是由于接口返回的数据内容或格式等兼容问题,导致前端页面渲染报错。)
- 如果上面调试页面中,出现接口状态异常(超时、报错504等),可直接分析后端关联服务。
- 如果报错接口较多,并非集中在某个服务,需要分析接口特征, 可考虑nginx/网关配置问题和 后端服务问题。
结论:
确认前端问题: 请查看前端页面问题SOP专项分析或联系研发。
常见前端问题处理指导参考: http://doc.seeyona9.com/pages/viewpage.action?pageId=52635418
无法定位:继续后续分析...
6. 判断:是否为Ngnix/网关服务问题(低概率)
1、当报错接口,显示为50x错误或1000x错误时,可以检测Ngnix和网关服务,可查看相关配置是否正常。
2、可通过报错接口获取到请求的traceId, 然后在应用服务日志中查看对应的traceId,如果为检索到,则可能为ngnix或网关服务异常导致。
常见状态码特征:
- `502`:常见是上游不可达、连接失败、Pod 不可用、转发失败
- `503`:常见是服务无可用实例、网关/Ingress 后端摘空、限流、熔断
- `504`:常见是上游处理超时,可能是网关超时,也可能是后端真的慢6.1 先从前端浏览器确认现象
看浏览器 `F12 -> Network`:
1. 找到报错接口
2. 记录:
- 请求 URL
- 状态码
- 响应体内容
- 响应头里是否有 `Server: nginx`、网关标识、traceId
- Timing 中是否卡在 `Waiting (TTFB)`
重点看两类信息:
1. 如果响应体已经是标准网关错误页,或明确写了 upstream/connect/timeout
- 很大概率在 `Nginx/网关` 这一层或它到上游的转发层
2. 如果返回的是业务服务自己的错误格式
- 更可能是后端应用自己报错,再被网关透传出来6.2 从集群内直接访问后端服务(关键步骤)
在集群内找一个能发请求的 Pod,分别测试:
1. 通过域名访问
- `https://外部域名/service/...`
2. 通过网关 Service 访问
- `http://gateway-service:port/...`
3. 直接访问后端服务
- `http://app-service:port/...判断逻辑:
1. 如果“经过 Nginx/网关 报错”,但“直连后端服务正常”
- 可以基本确认是 `Nginx` 或 `网关` 层的问题
2. 如果“经过网关报错”,且“直连后端也报错”
- 说明不是网关自身问题,更多是后端服务本身异常
3. 如果“外部访问报错”,但“集群内经网关访问正常”
- 更偏向 `Nginx、DNS、网络链路问题`结论:
考虑Nginx/网关问题:请查看Nginx/网关问题专项SOP或直接联系研发处理。
无法定位:继续后续分析...
7.判断:后端服务问题(高概率,重点分析)
基于以往分析,业务报错的问题,绝大多数场景都由后端服务异常导致,可重点分析。
常见相关后端异常问题:
├── 服务状态检测:服务异常重启假死 (高概率)
├── 后端服务异常(高概率)
│ ├── 接口执行超时、报错等
│ │ ├──SQL操作,导致接口超时报错
│ │ ├──Redis操作,导致接口超时报错
│ │ ├──消息消费慢,导致接口超时报错
│ │ └──dubbo操作,导致接口超时报错
│ └── 其他:发版变化导致业务
└── 中间件、主机、网络问题导致的报错
快速分析排查:
1、确认服务状态,是否宕机,是否重启
2、确认异常应用范围,如果异常接口集中在某个服务或某几个服务,比如公文、流程等,可重点查看对应应用
3、如果异常业务无明细特征,可以通过告警和服务监控确定异常服务范围。
4、如果为登录相关异常,可优先查看ctp-user服务相关日志等。
5、如果大量业务报错,也可重点分析是否为中间件数据库服务、redis服务异常,这些为高频使用中间件,异常会导致大量应用故障。
6、如果上面几步都未发现明细异常,可考虑近期是否有发版,导致问题
7、可通过前端获取报错异常接口的traceId, 在对应的服务日志中查看日志记录,分析问题1、关于报错问题,可以优先通过获取异常接口traceId,在对应服务查询异常日志进行定位。
2、也可通过服务监控的列表页快速筛选定位异常服务:
可参考图中请求错误、请求延迟等指标来分析确认异常服务
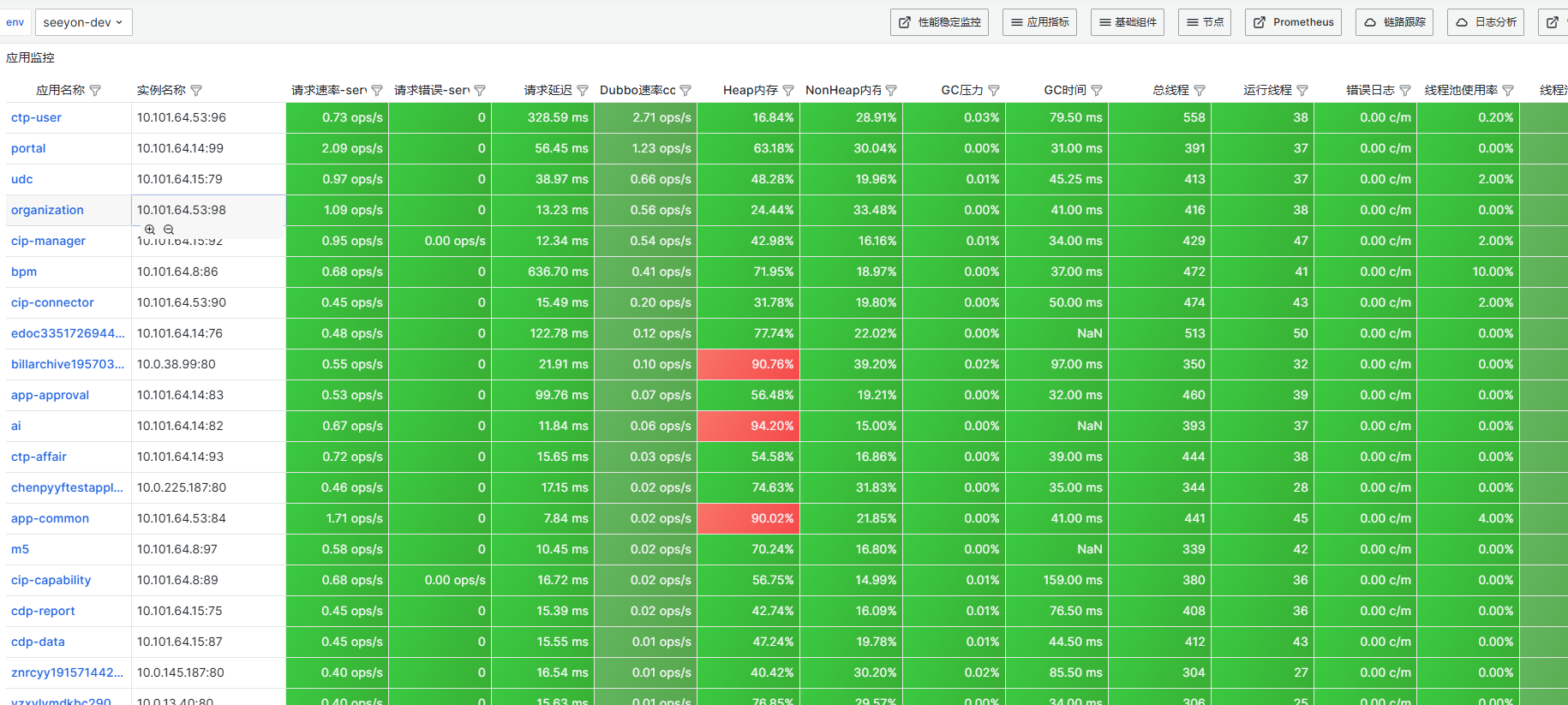
3、明确异常服务后,可用一键采集工具,进行采集扫描,初步分析定位可能的异常信息:
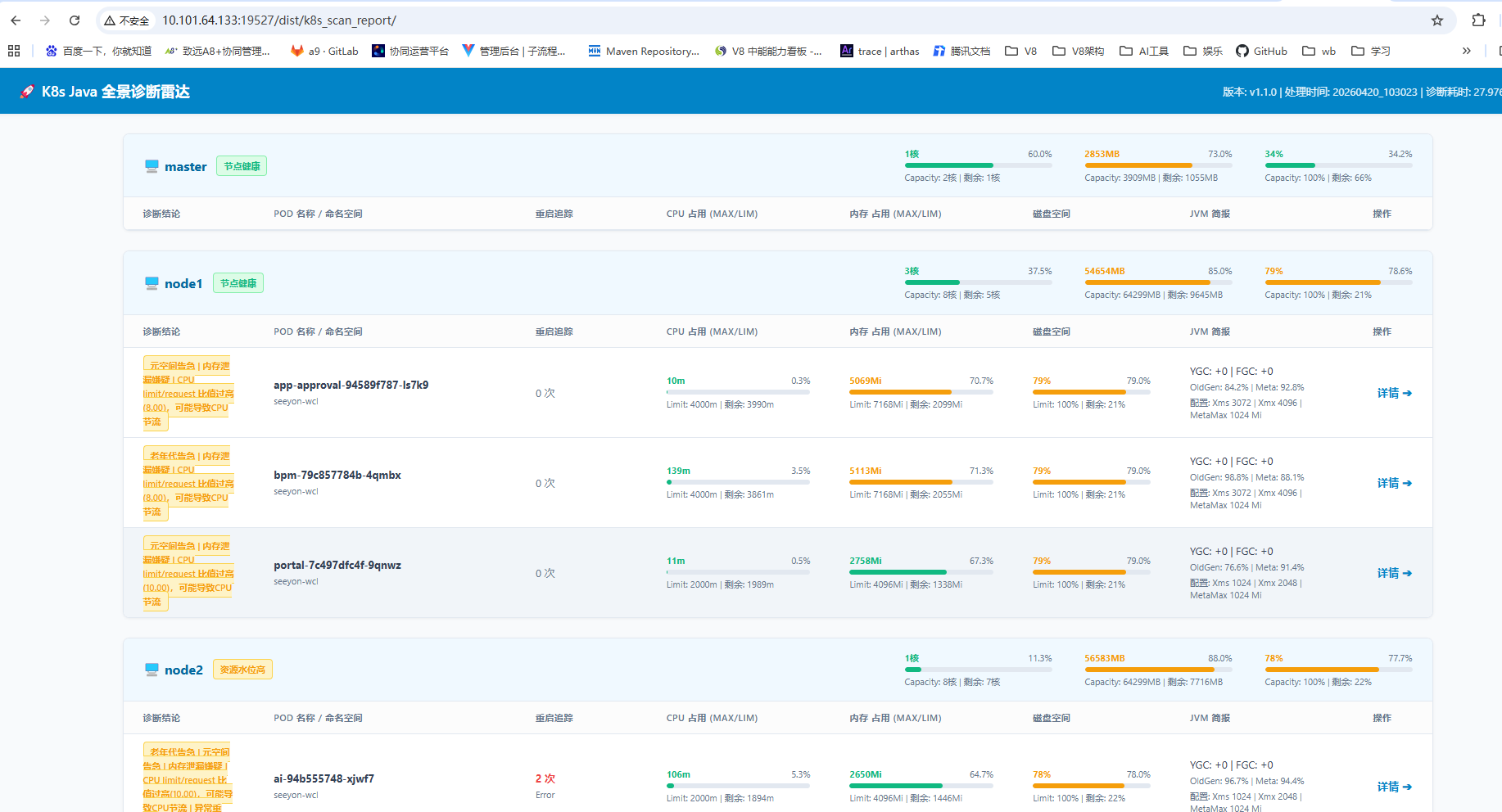
基于上述快速诊断分析,确认异常范围,和明确相关可疑问题点,可优先进行相关可疑点问题进行分析。
前端功能报错,一般情况都是由于后端接口请求报错、超时等问题导致。 而导致接口请求报错或超时,常见的可能因素:
- 业务功能逻辑异常,代码执行报错
- 接口触发了慢sql,造成超时报错
- 接口触发了redis慢请求,超时报错
- 调用其他dubbo接口慢,超时报错
- 消息处理慢,造成相关逻辑阻塞,出现报错
- 服务状态异常(内存不足、cpu高等),导致处理逻辑异常报错
- 中间件服务异常,导致业务接口执行慢或报错
如果服务为超时问题导致报错时,在分析时往往还需结合服务的监控信息一起分析,优先关注服务的(cpu / 内存 / gc 指标),分析确认是否由于资源不足问题导致的异常。
7.1 检测服务状态(服务宕机、重启)
1、如果已确认可能异常的服务,可直接查看服务状态。
2、如果未确定服务范围,可直接在k8s服务面板,查看是否有服务宕机,重启等
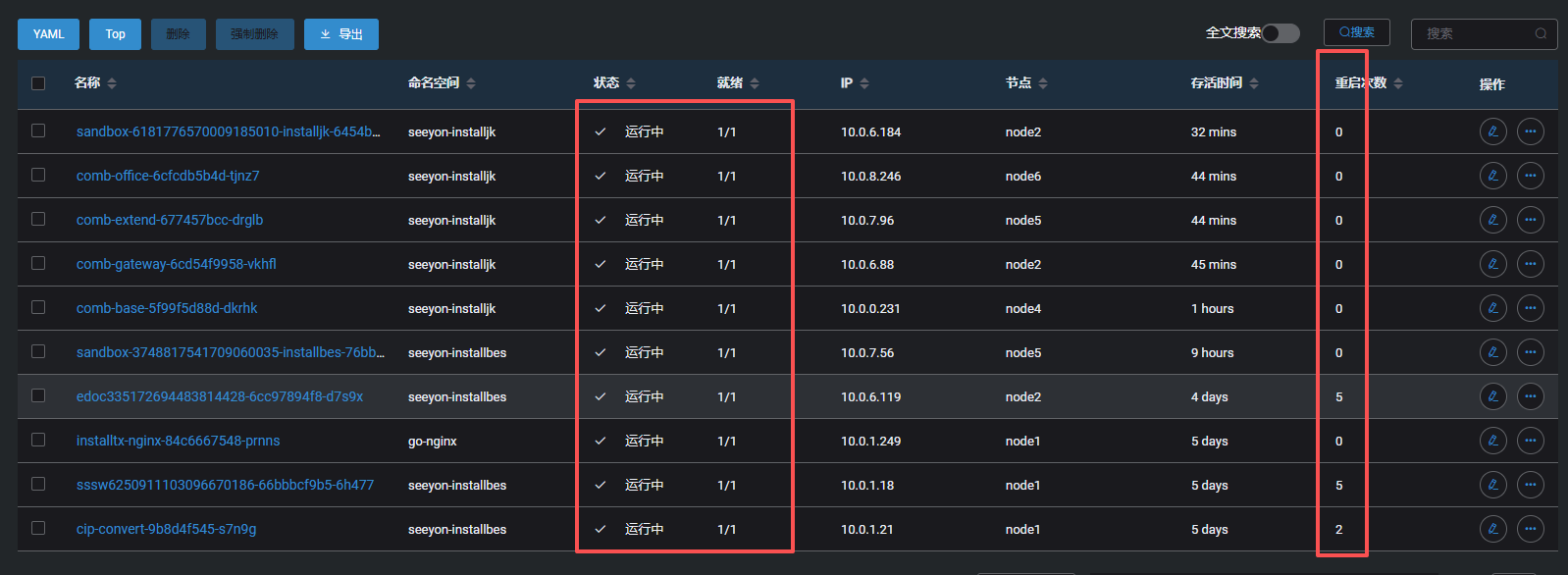
说明:不同k8s管理界面不同,可能展示不同,但查看管理界面,关注服务状态、重启情况
如果存在服务宕机:
1、请查看k8s的宕机事件,确认是否由于资源不足,服务被驱逐。( K8S的oomkiller)
常见的资源不足,被驱逐的情况主要有:
1、服务器磁盘资源不足
2、服务器cpu资源不足,负载过高
3、服务内存不足,无法申请到足够内存给pod.如果确认是资源不足驱逐,可优先转入相关应急修复策略执行恢复。
2、查看服务监控,确认服务本身是否存在异常,导致宕机。常见容易导致宕机的异常指标多出现在内存占有率高、高频fullGC、元空间使用率高(非堆使用率)等。( JVM堆内存溢出 、 元空间内存溢出)
2.1 如果根据宕机前监控信息,发现服务可能是由于内存不足造成的宕机。
2.2 如果监控异常表现为内存溢出问题,则可查看对应异常时段的应用日志是否有OOM等信息。如果有,则明确为OOM异常,可优先考虑执行恢复策略,同步再进行根因分析。
2.3 如果服务暂时还为宕机,但是监控中内存飙高,fullGC明显增加,表有较高宕机风险。可先执行扩容资源重启的恢复策略,然在进行根因分析。
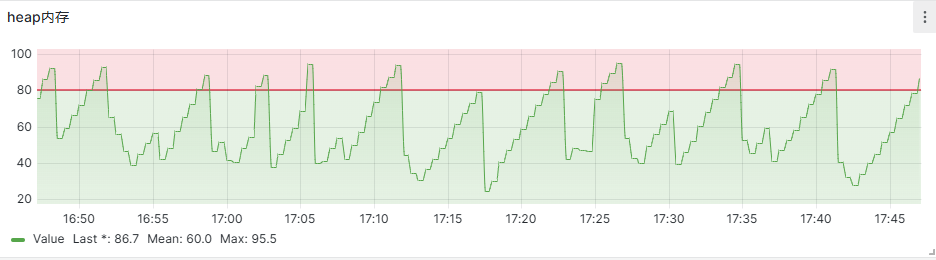
2.4 检测服务的yaml,基于应用推荐配置,并结合客户用户量和数据量进行评估,如果配置不合理,按照这恢复策略,进行调整。查看堆内存使用,是否出现超过80%阈值且有无法回收下降趋势,可能存在内存不足风险,?(图中为使用百分比)
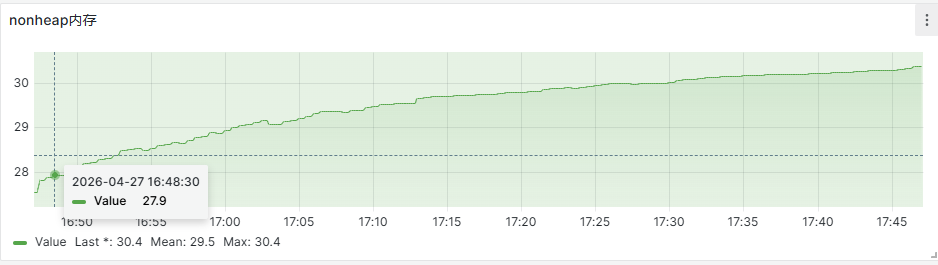
查看非堆内存使用(主要为元空间),是否存在元空间不足(图中为使用百分比)
查看GC情况,是否存在服务fullGC,可能导致服务卡顿处理的请求异常。
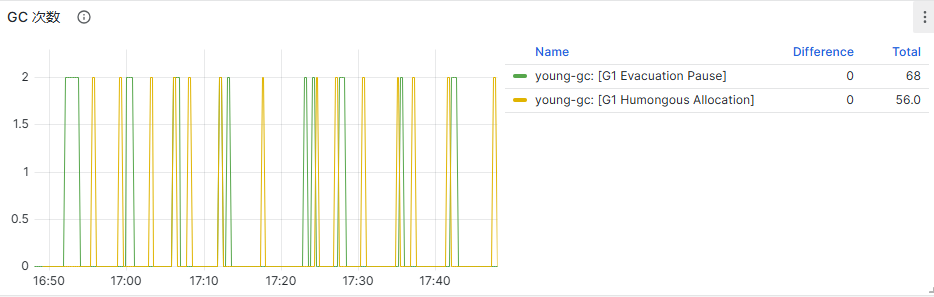
如果服务监控出现上述类似现象,表明服务有宕机风险,可以采用紧急策略优先扩展服务副本数,避免服务发生宕机后完全中断业务。同时针对异常服务进行后续分析。
3、如果服务已宕机,可根据服务宕机前监控,初步分析导致宕机的常见原因:
- 内存占用过大,
OutOfMemoryError: Java heap space( JVM堆内存溢出 ) - cpu使用率过高,夯死服务
- 线程排队夯死服务
- 元空间不足,
OutOfMemoryError: Metaspace (或 PermGen space)( 元空间内存溢出)
可结合日志和dump信息,进一步确认相关原因。恢复策略可参考后续应急措施处理( 常见应急恢复策略)。
如没有宕机:
未发现宕机等相关问题,则需进一步结合服务日志等手段策略分析
7.2 日志分析
1. 基于traceId分析日志
对于典型的后端接口异常导致业务报错问题,可优先通过获取异常接口traceId, 然后通过traceId串联服务日志内容进行分析。且针对本SOP场景,可能考虑获取多个异常接口的traceId日志进行分析,重点关注分析这些traceId日志中共有异常问题。
通过traceId过滤日志,进行分析:
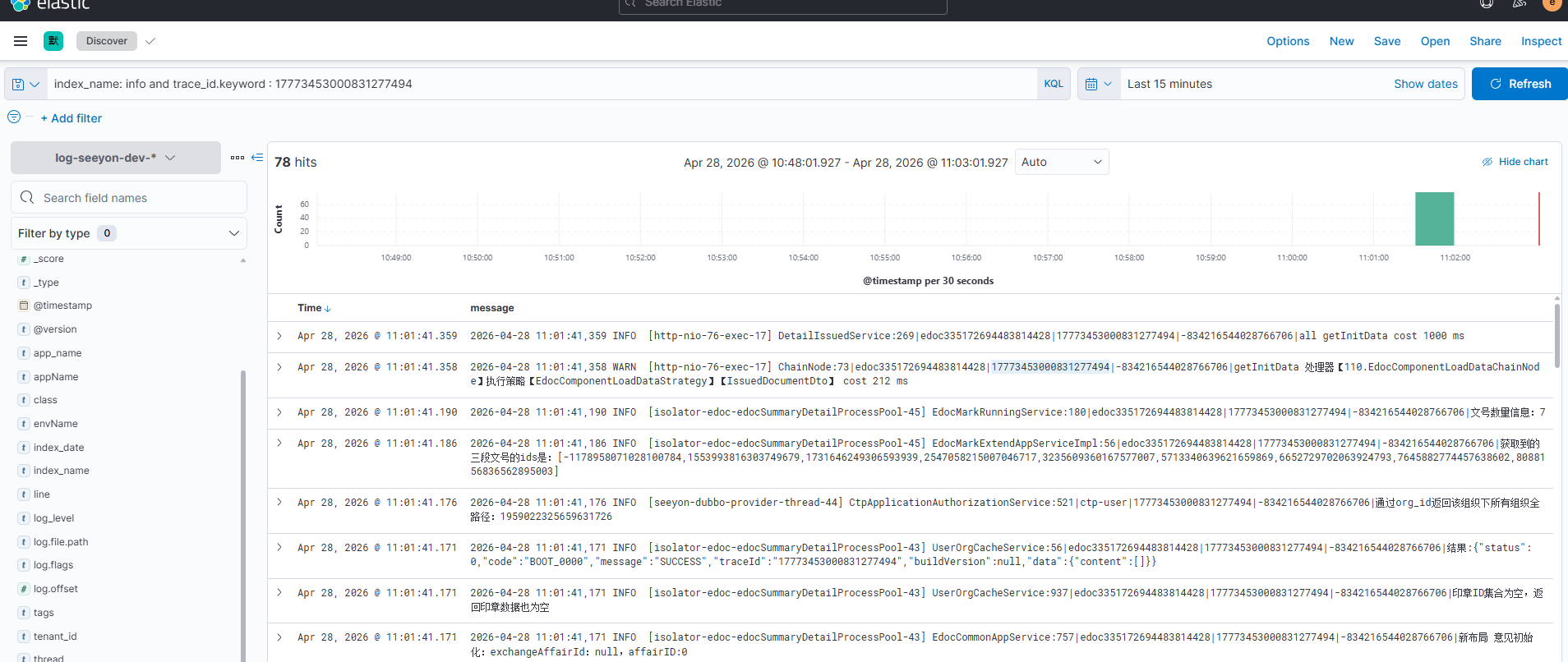
如无日志平台,也可直接过滤日志文件:
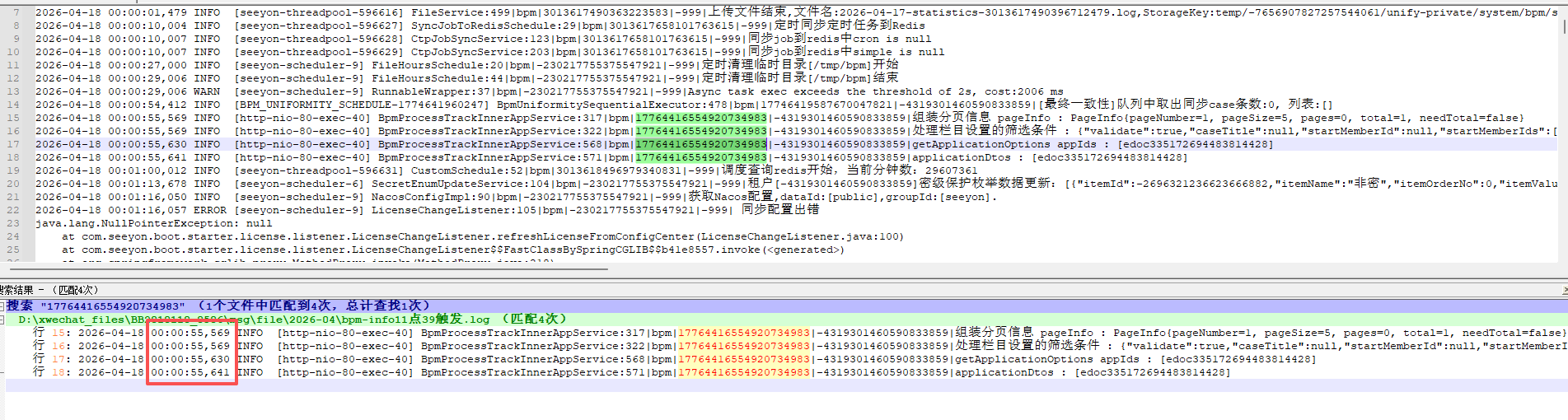
快速确认现象:
- 通过traceId,过滤对应异常服务日志,如果有日志平台ELK,则可通过在线查看界面直接用traceId查询过滤,可查询整个链路的日志进行上述分析;如果无日志平台,需要根据业务查询多个关联服务的日志进行分析。
- 基于过滤日志,检测日志中是否存在报错信息,如果存在,直接分析报错。
- 基于过滤日志,检测日志中是否存在调用慢日志超时日志,如
timeout,有则直接分析该异常点。 - 基于过滤日志,如果日志为http线程,关注http线程日志的整个处理时长,是否整个处理耗时过长,关注如果出现则,基于日志分析对应业务逻辑。
- 如果存在record.log日志,利用traceId过滤查询,检测是否有相关性能日志,分析对应耗时点。
针对异常的日志信息,进一步分析报错点/timeout异常点/耗时异常点:
- 如果错误和sql或数据库相关,转入后续 #7.3 sql和数据库问题分析(高频)
- 如果错误和redis操作相关,转入后续 #7.4 redis操作和redis服务异常分析
- 如果错误和dubbo操作相关,转入后续 #7.5 dubbo相关问题分析(高频)
- 其他异常可联系研发继续分析
2.无traceId分析日志
当无法获取到异常问题的traceId时,可通过异常时间段,大概定位相关异常信息的日志,结合服务监控和异常业务点,定位大致的异常点。
1. 根据锁定的异常服务范围,分析对应服务的异常时间段的info日志。
2. 优先分析对应日志中存在error日志信息,如果发现相关错误日志
3. 如未发现error日志,检索warn日志,查看是否存在相关异常点
4. 还可基于cost: 关键字查询,检索日志中长耗时相关日志信息,发现耗时异常的点,可依据其他类型继续分析。
5. 如果上述info日志中未发现明显异常,或异常信息不明显,可接口record.log中的日志集合分析,初步确认是否数据库操作、redis操作、dubbo操作等分类中,然后转入后续的分析流程针对日志异常信息点:
- 如果sql或数据库相关,转入后续 #7.3 sql和数据库问题分析(高频)
- 如果redis操作相关,转入后续 #7.4 redis操作和redis服务异常分析
- 如果dubbo操作相关,转入后续 #7.5 dubbo相关问题分析(高频)
- 其他异常可联系研发继续分析
特殊当日志检索到报错:
- 错误信息为业务逻辑代码错误,如NullPointerException等,则直接联系研发定位异常逻辑点。
- 如果发现大量sql相关异常或超时日志,可继续 #7.3 sql和数据库问题分析(高频)
- 如果日志中出现redis相关请求异常 #7.4 redis操作和redis服务异常分析
7.3 sql和数据库问题分析(高频)
如果由于服务数据库操作导致的服务接口功能异常,常见的场景可总结归纳为下面几类:
1. sql执行报错
2. sql执行超时
3. 数据库组件高负载或异常,导致查询异常
4. 数据库连接池异常(如无法获取连接等)日志中有相关sql报错异常场景:
- 如果报错出现
timeout等字样,考虑是否为慢sql导致。如果存在record.log,可结合该日志查看具体的慢sql信息,联系研发进行慢sql分析
- 如果异常日志中出现
connect reset等,一般表明连接被数据库服务端主动关闭,可能由于该连接异常或连接超时,需要检测数据库服务是否正常(可结合监控信息确认推断)。如果数据库服务异常,则可确认问题原因,进入快速恢复流程。
数据库主机监控信息: 重点关注 cpu、内存使用率等。
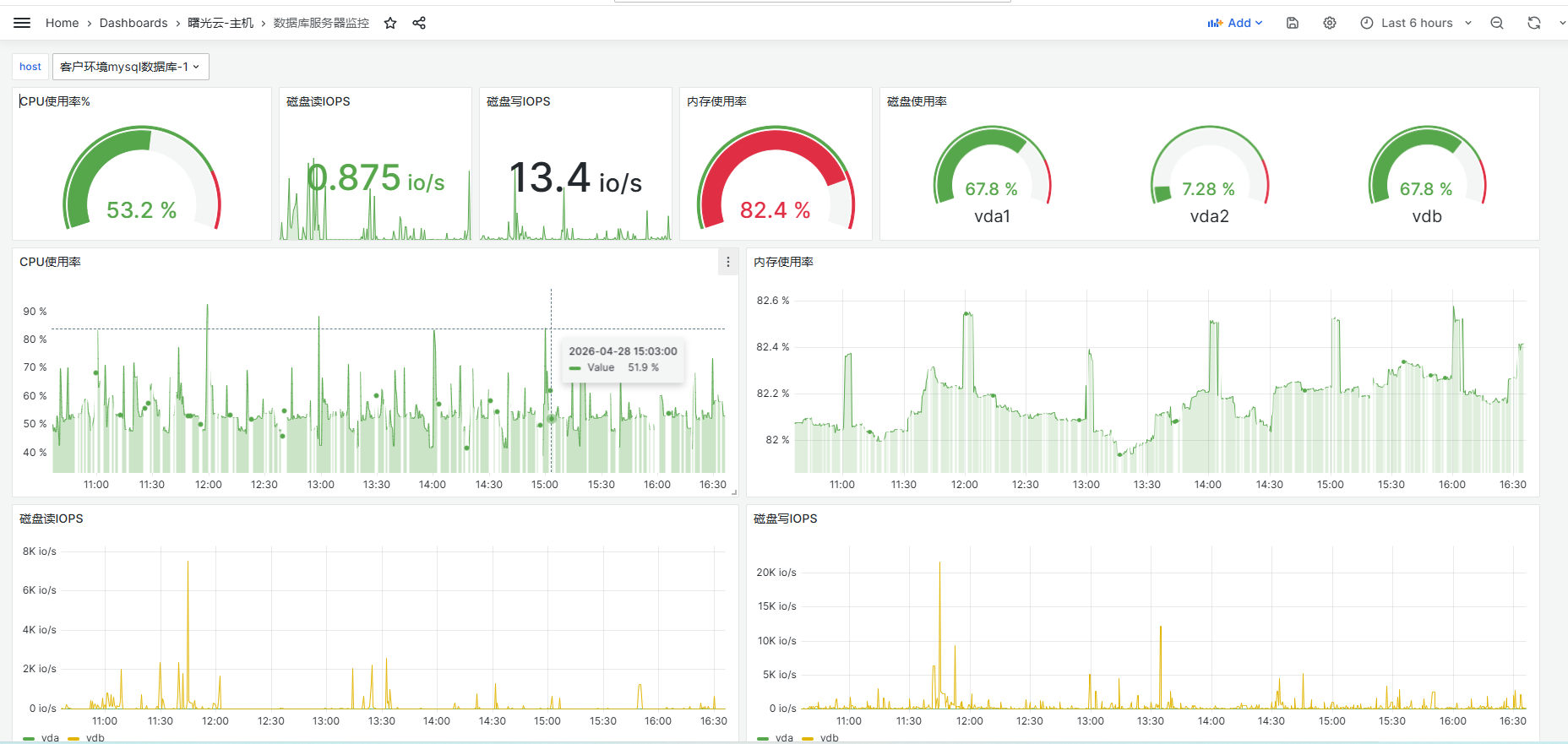
数据库监控信息(以mysql为例),关注数据连接数等 ! Pasted image 20260428163717.png
如果出现获取连接相关异常
1 确认数据库服务连接池是否超限。可通过数据库连接客户端查询,也可通过数据库监控进行查看。如果发现连接数据不够,则可考虑优先扩大数据库服务最大连接数。具体操作转应急恢复流程。
2 获取连接异常更多时候可能时服务配置文件,检测服务内数据库连接池使用情况。检测服务druid监控页面,查看是否存在慢sql和连接池不足等情况(如果非druid连接池忽略)
{host}/service/{appName}/druid/sql.html
如:https://dev.seeyonv8.com/service/bpm/druid/sql.html重点关注(活跃连接数峰值):
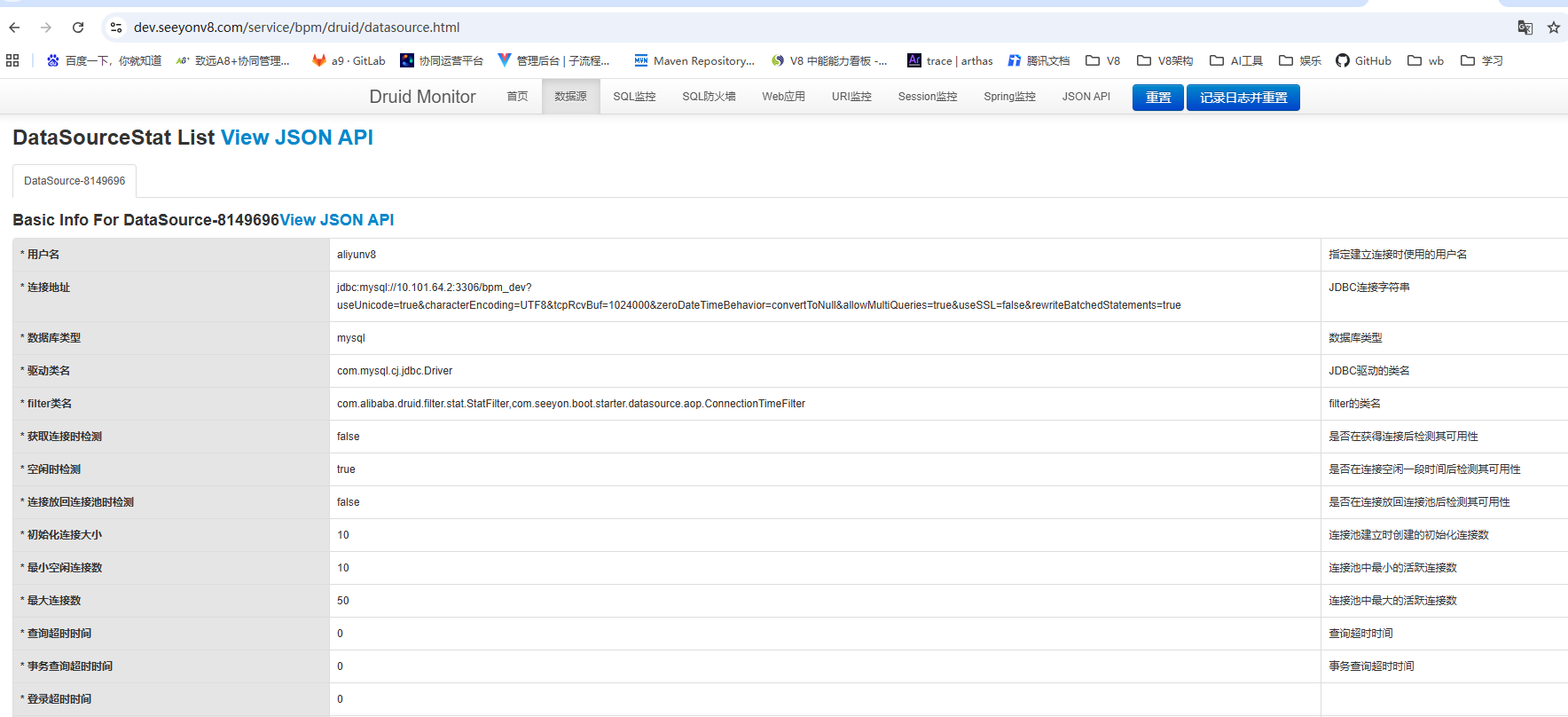
可通过下面url,查看应用数据库连接池情况,当前连接信息,慢sql统计情况等
{host}/service/{appName}/monitor/db-info
如:
https://dev.seeyonv8.com/service/ctp-user/monitor/db-info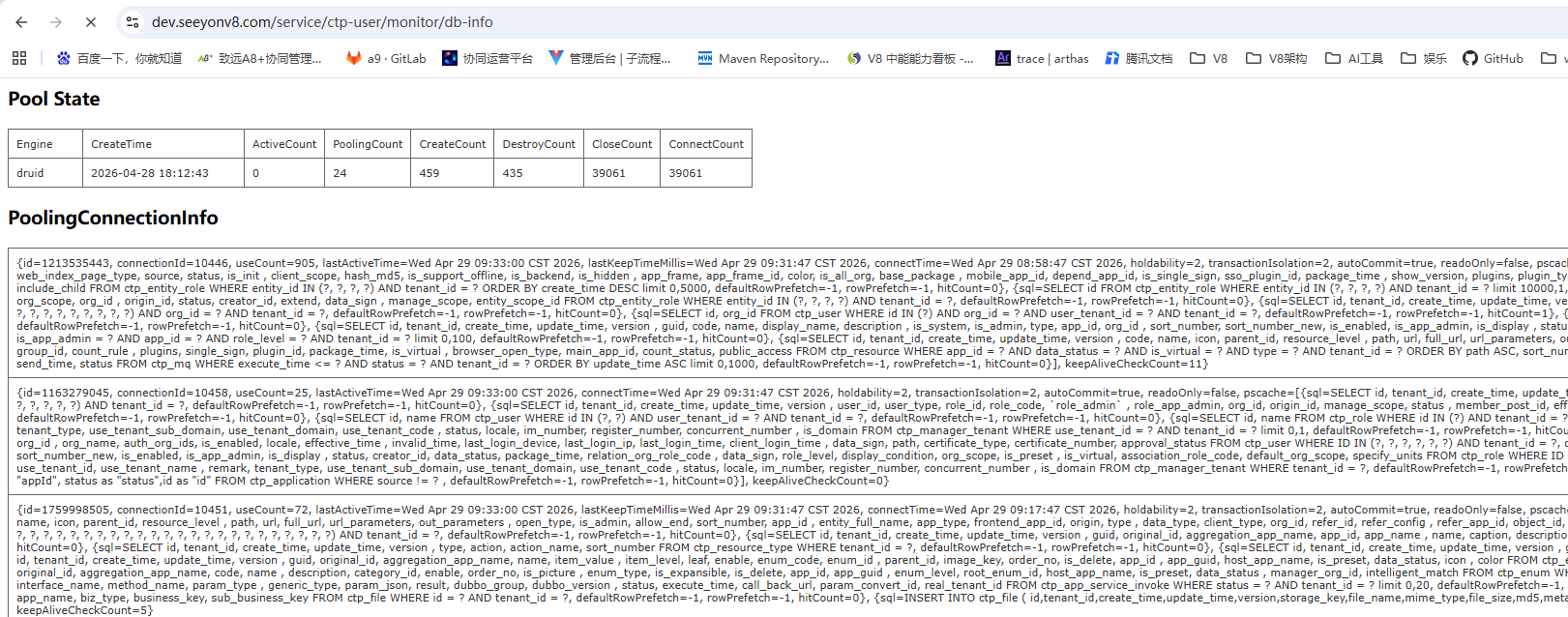
还可通过服务监控页面的数据库连接池部分进一步确认和定位
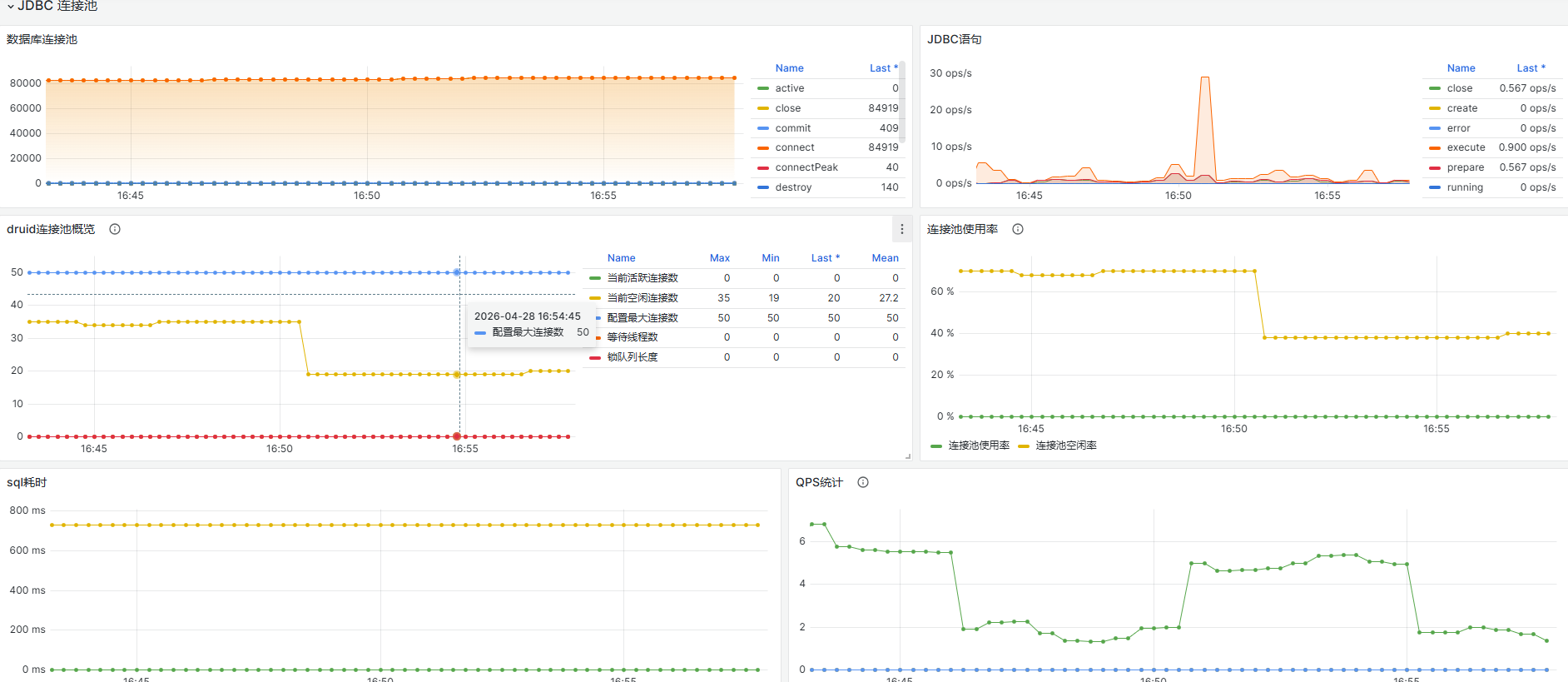
如果发现服务自身连接池不足, 导致无法获取到连接,可考虑增加服务连接池配置,可转入快速恢复流程操作.
2、日志中无明显sql报错,但性能日志(record.log)或info日志有相关sql执行的耗时异常等日志信息。也可结合服务监控中数据库连接池相关监控指标进行分析。
2.1 一般考虑数据库相关问题,但无相关报错,往往会有慢sql、连接池高负载等现象。重点关注。
2.2 此种情况,也可能为数据库服务异常,分析数据库服务是否存在高负载,处理慢的。通过检测相关监控,连接数据库验证sql执行性能等进一步确认。
如果确认相关慢sql( 数据库慢速sql)或数据库问题( 数据库异常),可转入快速恢复流程。转研发同步进行根因分析。
如果上述无法定位到问题,继续后续分析。
7.4 redis操作和redis服务异常分析
如果由于redis操作导致的服务接口功能异常,常见的场景可总结归纳为下面几类:
- redis大key慢
- redis操作失败
- redis服务异常
一般redis操作失败在下面监控图中的执行失败数会增加。
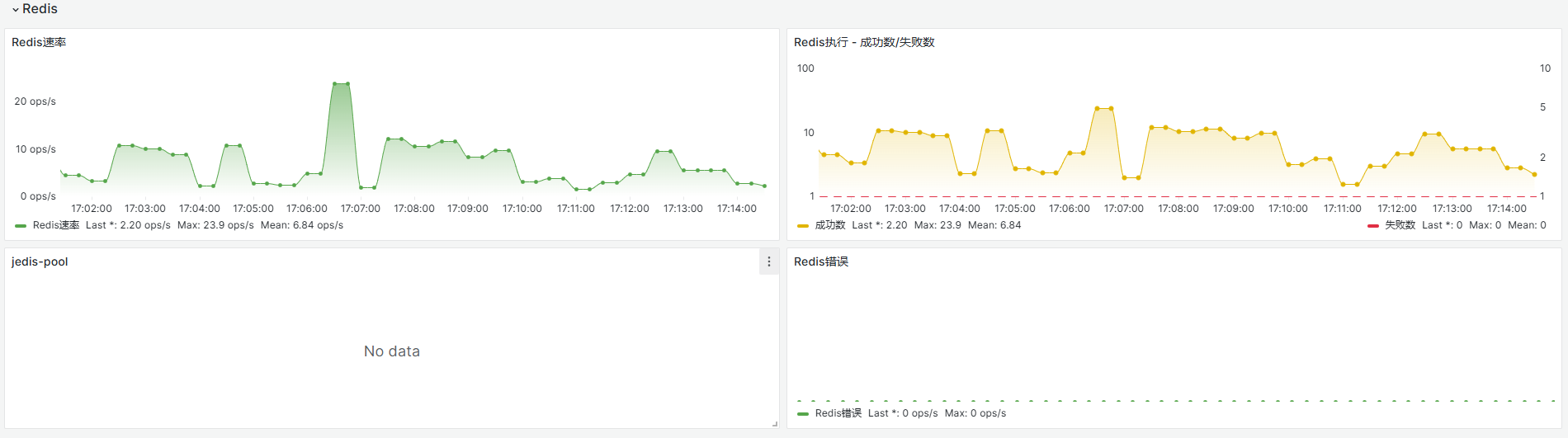
日志中有相关redis报错异常场景:
- 一般redis操作失败,如果日志中明确为业务逻辑异常导致,直接联系研发分析
- 如果redis操作,如果出现
timeout异常,或出现redis服务端相关异常信息,优先检测redis服务器是否正常。
2.1 检测redis主机是否内存达到使用上限(重点关注主机内存是否达到风险阈值,如超过80%)
2.2 检测redis服务是否正常,是否服务宕机等异常。
redis服务监控图:
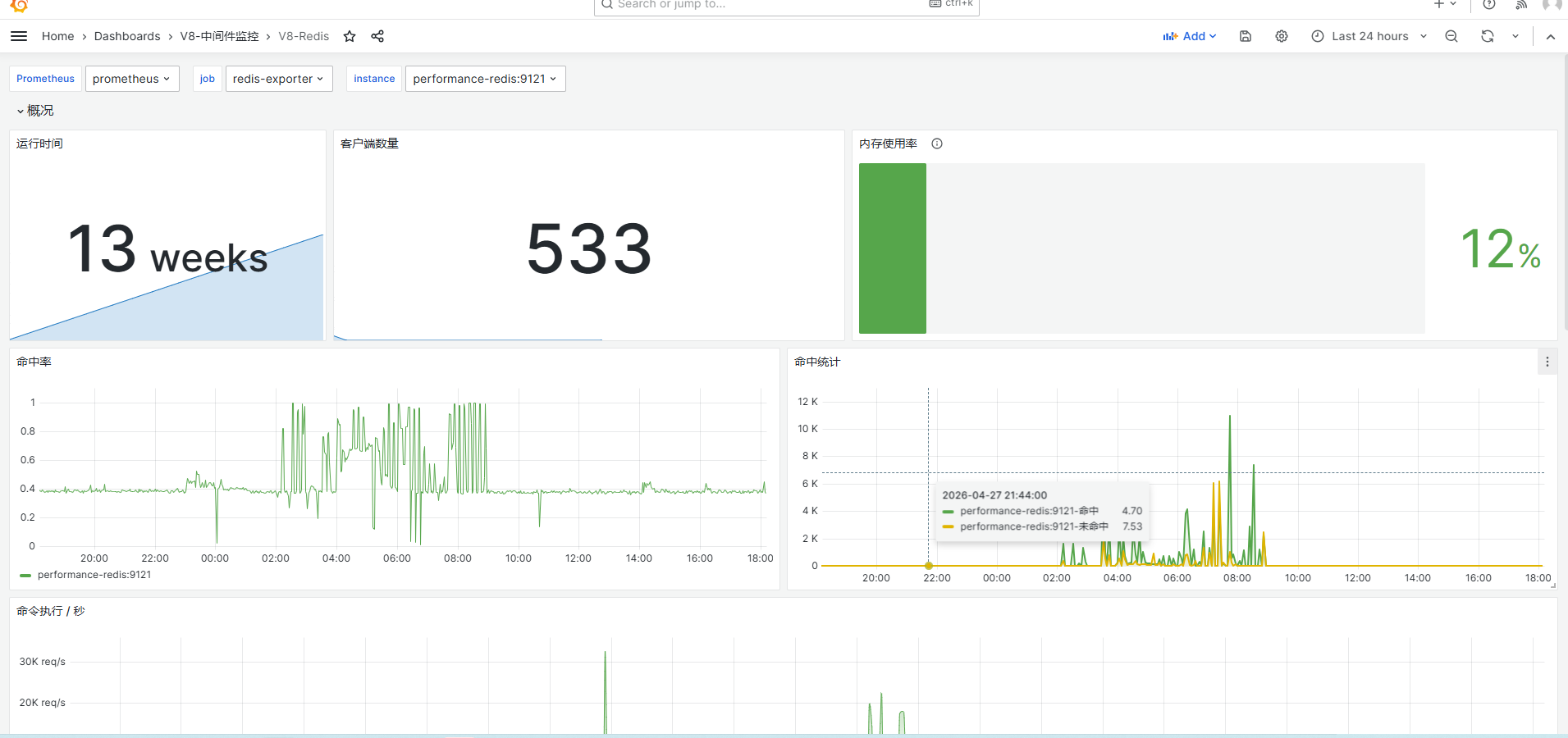
如果确认为redis服务异常导致问题( 数据库慢速sql 、 核心中间件服务异常),可转入对应快速恢复流程,并让研发转入后续根因分析。
如果上述无法定位到问题,继续后续分析。
7.5 dubbo相关问题分析(高频)
如果由于dubbo操作导致的服务接口功能异常,常见的场景可总结归纳为下面几类:
1、dubbo接口调用超时
2、dubbo接口调用失败(抛错、未找到服务(注册异常等))1、通过监控图表分析:
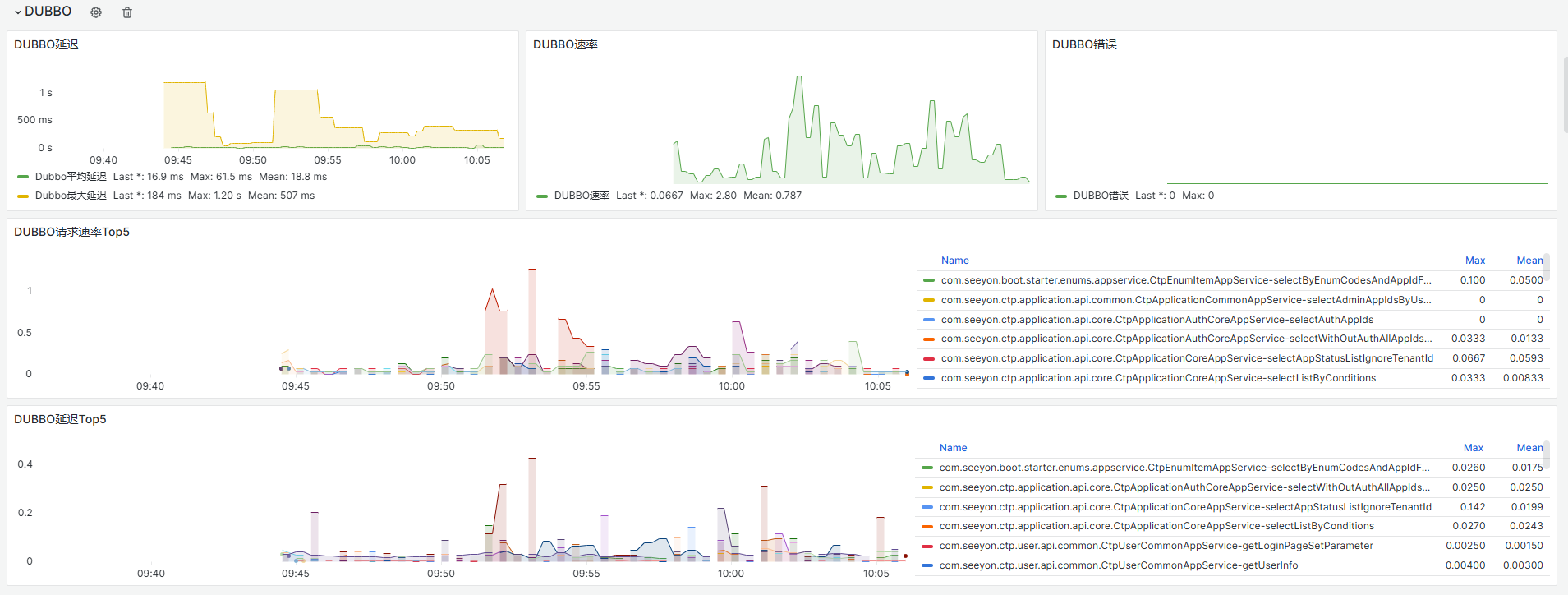
查看图表中是否有dubbo错误请求增加,是否存在dubbo延迟升高问题。
1.如果是dubbo错误增量,需要结合日志,查看具体异常dubbo接口。
2.如果考虑dubbo延迟问题,可查看dubbo延迟TOP5部分的近期的延迟接口,然后结合日志进行定位。如果初步定位为dubbo请求报错问题,可直接转入日志,查看info日志中的dubbo相关请求报错进行分析。
如果初步定位为dubbo请求慢问题,这种情况大多是dubbo发起方等待超时,可基于日志和监控分析dubbo接口提供方服务,分析dubbo接口提供方服务处理慢问题(常见原因:慢sql 数据库慢速sql、cpu繁忙、内存不足等情况)
对于dubbo请求慢问题,还可通过下面url,查看应用dubbo处理情况,
{host}/service/{appName}/monitor/dubbo-info
如:
https://dev.seeyonv8.com/service/ctp-user/monitor/dubbo-info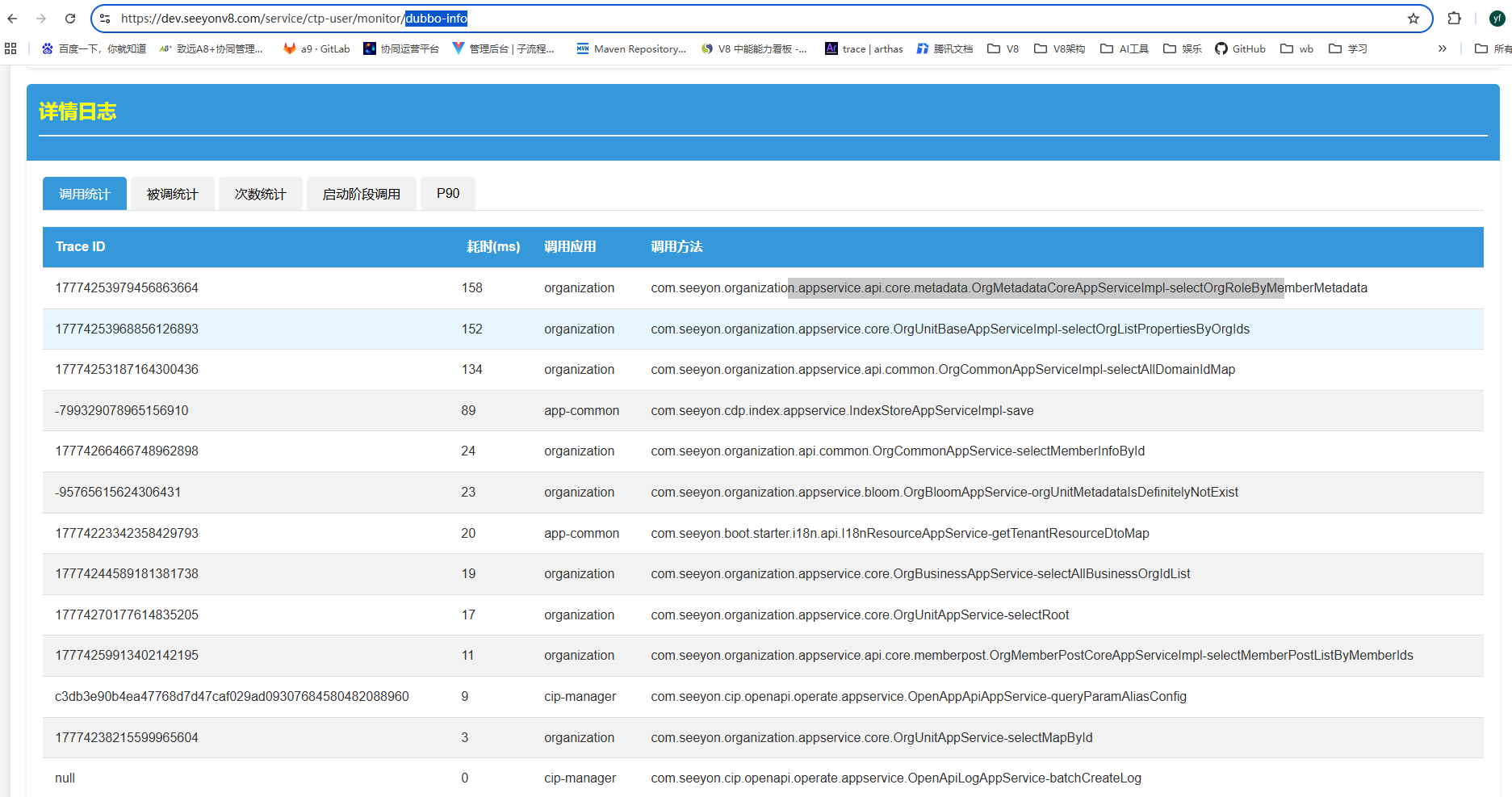
集合上面分析页面,定位可能的问题接口点,进入info日志进行更多分析。
如果确认为提供方dubbo问题,需要转入服务提供方应用继续分析。
如果其他dubbo问题,可联系研发继续分析。
如果上述为定位到问题,继续后续分析。
7.6 消息处理异常导致的问题
常见的消息处理异常场景有:
1、消息风暴,短时大量消息待处理,造成消息积压,业务异常或延迟
2、消息处理异常报错,阻塞后续相关消息的消费,并可能回出现大量同一消息消费错误的日志等
3、消息处理逻辑慢(可能慢sql等导致),造成消息积压,业务异常基于以往消息异常场景,消息异常时,往往会有以下特征:
1、服务日志中可能存在大量消费消息相关日志
2、可能存在较多消息消费报错日志
3、查看服务线程信息threadDump,可能存在较多线程在再处理消息
4、可登录MQ服务端,确认是否存在topic的消息积压通过监控,查看jvm的线程情况:

查看活跃线程数据和线程中不同状态的线程数
- BLOCKED过大 :锁竞争。
- WAITING/TIMED_WAITING过大 :I/O 等待或任务队列积压。
- RUNNABLE 饱满且系统慢 :CPU 瓶颈如果基于日志和上面监控,还无法定位问题,可考虑采用arthas和服务内存dump数据等进一步分析。
7.7 中间件服务异常导致的问题
常见的中间件异常场景有:
1、数据库配置不合理或异常,如:数据库服务宕机、重启
2、redis服务异常
3、kafka服务异常或配置
4、中间件宿主机异常,如常见:磁盘满、io异常等如果考虑数据库相关问题:
- 通过检查日志,查看是否存在相关中间件调用异常,比如 数据库查询超时
timeout、connect reset等,或发现大量慢sql, 确认sql对应的表数据量不大,且索引正常等,可初步推断数据库问题。 - 进一步检查数据库服务和 数据库主机,如果存在相关监控,可通过监控快速查看数据库服务内存、磁盘、连接数等指标,查看是否存在异常,如果由相关异常则转入 数据库异常,如发现是数据库主机问题,如常见的磁盘满等问题,则转入 硬件资源异常
如果考虑redis问题:
- 可检测redis服务器,通过监控确认redis服务和redis服务所在主机是否存在异常。如由相关异常,转入 核心中间件服务异常或 硬件资源异常
- 查看确认是否由于redis慢操作导致的异常,可通过服务的性能日志
recode.log,并查看redis的slow-log信息,结合监控,确认是否为redis操作慢问题。确认问题转入 redis请求慢
如果考虑kafka服务问题:
- 查看kafka主机,确认服务是否存在问题,检测主机是否正常(检测 cpu、内存、磁盘等)
- 连接kafka服务端,确认是否存在异常业务相关的topic消费延迟,造成服务功能异常。确认为kafka相关问题可联系总部运维或研发分析解决。
7.8 其他常见分析思路
1、如保存问题集中在登录场景,可优先直接分析ctp-user服务。
2、优先考虑是否由于近期发版等变更导致。
1、近似是否存在发版或更新补丁等操作,更新前后业务性能出现较大变化,可重点考虑更新的功能点导致的问题
2、近期是否有调整服务参数(nacos配置参数、部署yaml参数、ddl、业务参数等),调整前后性能是否有较大变化3、网络异常或波动可能导致的问题
典型异常现象:
1. 常见的页面接口报错为ConnectionTimeout
2. 网络波动造成的异常,经常表现为某个时间段异常,之后会自动恢复。
3. 异常时间段受影响的接口范围分散,没有明确集中再某个功能或某个服务。
确认策略:
1、可在异常时间段,采用网络分析工具分析网络,如ping | traceroute 等
2、TCP 连接状态检查,命令:netstat -an | grep <端口> 或 `ss -ant`,关注:是否存在大量 `TIME_WAIT`(短连接耗尽端口)或 `CLOSE_WAIT`(连接未正常关闭)状态,这可能引发后续连接失败
3、同时可检测服务端,同样的业务请求,再服务端触发无异常,但跨网络触发出现异常,大概率就是网络问题如上述分析还是无法定位到异常原因,请联系对应研发进行分析。
日常预防建议
- 建立前端、网关、应用、中间件、节点的统一监控。
- 针对接口调用失败,增加告警触发机制,如短时高频触发报错异常。
- 建立数据库、Redis 、Kafka等组件存在和服务状态监控告警 和巡检机制。
- 建立 Pod 重启、驱逐、OOM、节点压力告警。
- 发布必须保留回滚方案。